YARN架构详解:资源管理与作业调度分离
198 浏览量
更新于2024-08-28
收藏 388KB PDF 举报
YARN(Yet Another Resource Negotiator)是Apache Hadoop项目中的下一代分布式资源管理和调度系统,旨在解决MapReduce在大型集群中面临的单点故障、性能瓶颈以及对新计算框架支持不足的问题。MapReduce中的JobTracker存在明显的局限性,包括集中式架构导致的单点故障风险和资源管理的不灵活性。
YARN的核心设计思想是将JobTracker的功能分解,通过引入一个全局的ResourceManager (RM) 和多个与应用程序相关的ApplicationMaster (AM) 来实现资源管理和作业调度的分离。RM负责整个集群的资源分配,它掌握着所有节点的资源信息,如内存、带宽和CPU核心数,并根据应用程序的需求进行公平和动态的资源调度。AM则代表每个应用程序,负责管理单个应用程序实例的生命周期,包括资源请求、任务调度、失败处理等。
在YARN的工作机制中,用户首先通过客户端提交应用程序到RM,应用程序提交后,AM会向RM注册并申请所需的资源。RM根据申请分配资源后,AM再向NodeManager (NM) 发出启动Container的请求。NM在各个节点上运行,负责容器的实际执行。当Container启动后,NM会向AM报告其状态,如果成功则继续执行任务,如有问题则AM需要重新申请资源。在整个过程中,AM和NM通过心跳机制保持与RM的通信。
4.1 ResourceManager (RM)
作为YARN的核心组件,RM在高可用性方面进行了增强,它运行在专用服务器上,避免了JobTracker的单点故障。RM的职责包括资源分配和回收,确保资源的合理利用,同时提供一个统一的接口供用户提交和管理应用程序。
4.2 ApplicationMaster (AM)
AM是YARN中的一个重要角色,每个应用程序都对应一个AM实例。AM不仅负责应用程序实例的初始化和终结,还负责动态调整资源需求,例如在任务执行过程中增加或减少资源。此外,AM还需处理任务失败的情况,确保任务的正确执行和恢复。
YARN的设计允许其他计算框架(如Spark、Flink和Storm)与之集成,提供了更大的灵活性和可扩展性。用户可以直接在YARN平台上提交他们的应用程序,享受到资源管理和调度的一致性,从而简化了运维和开发工作。
总结起来,YARN通过模块化的架构和职责分工,解决了Hadoop MapReduce的痛点,成为现代大数据处理的重要基础设施,为大数据生态系统中的各种计算任务提供了强大而灵活的资源管理和调度能力。
yarn入门入门——yarn的架构及作业调度的架构及作业调度
1、yarn产生背景
mapReduce存在问题:
JobTracker单点故障
JobTracker承受的访问压力大,影响系统扩展
不支持MapReduce之外的计算框架,比如Storm,spark,flink
2、yarn的核心思想
是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,YARN的基本思想是将JobTracker的两个主要功能(资源管理
和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的
ApplicationMaster(AM)。
它由下面几大构成组件:
ResourceManager:负责为集群中的所有应用程序分配资源
每个节点代理 的NodeManager
每个应用对应一个ApplicationMaster
一个ApplicationMaster拥有多个Container,Containner在NodeManager上运行
运行在独立节点上的RM和NM一起组成了YARN的核心且构成了这个平台。AM和相应的Container一起组成了一个Yarn的应用
程序。从YARN的角度来看,所有用户通过提交应用程序,然后利用该平台提供的资源来进行交互。从最终用户的角度看,他
们可能是直接在YARN平台上通过运用应用程序和YARN进行交互。
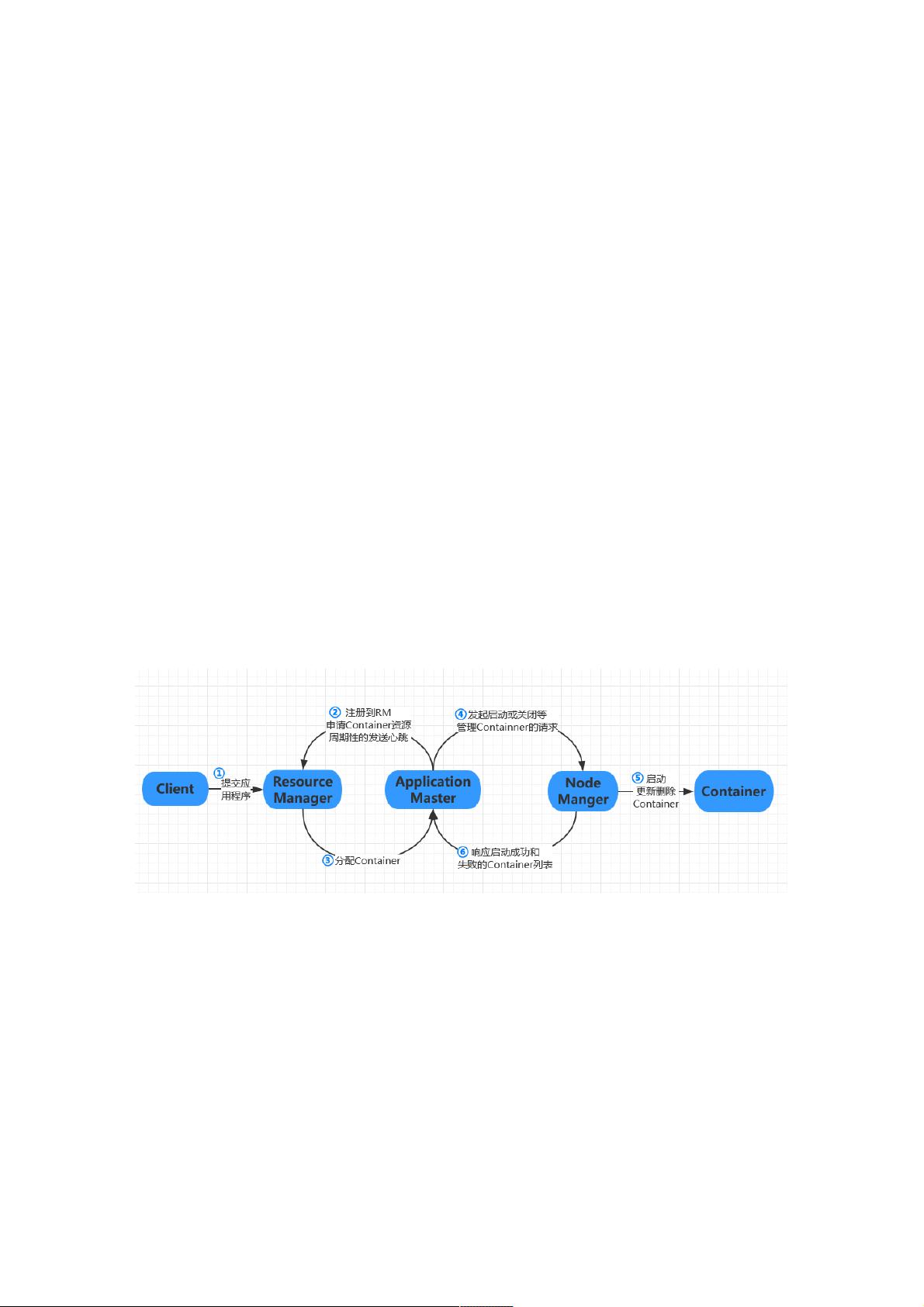
3、工作机制概述
Client向RM提交应用程序,应用程序提交到RM后,AM注册到RM上,RM计算所需资源并向RM提出申请,RM返给AM资源信
息,AM向NM发起启动container的请求,container启动后,NM将启动成功和启动失败的container列表发送给AM,由AM重新
向RM申请资源,期间AM和NM定期的向RM发送心跳。
4、组件简介
4.1、ResourceManager(RM)
RM作为一个独立的守护进程运行在专有机器上,RM拥有集群上所有资源的信息,是集群所有资源的仲裁者,只负责给应用
进行资源的划分和资源的收回。这里的资源主要指:内存,带宽,内核数等。
4.2、ApplicationMaster(AM)
ApplicationMaster管理一个在YARN内运行的应用程序的每个实例,每个应用程序对应唯一一个AM。 负责管理作业的生命周
期,包括动态的增加和减少资源使用,管理作业执行流程,处理故障和计算偏差,以及执行其本地优化。
4.3、NodeManager(NM)
管理集群中独立的计算节点。
NM是每个节点上的资源和任务管理器。一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container运行状态;
下载后可阅读完整内容,剩余5页未读,立即下载
2017-11-01 上传
2012-05-17 上传
2021-01-20 上传
2013-11-01 上传
2021-04-25 上传
2023-12-15 上传
2021-12-31 上传

weixin_38720461
- 粉丝: 9
- 资源: 924
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
