YARN架构与作业调度:解决MapReduce痛点
157 浏览量
更新于2024-08-28
收藏 388KB PDF 举报
YARN(Yet Another Resource Negotiator),是Hadoop生态系统中的一个重要改进,针对MapReduce存在的问题提出了全新的解决方案。这些问题主要包括JobTracker的单点故障风险、巨大的访问压力导致系统扩展性受限,以及对非MapReduce计算框架如Storm、Spark和Flink的支持不足。YARN的核心目标是将资源管理和作业调度功能从JobTracker中剥离,以实现更好的可扩展性和灵活性。
YARN的设计基于一个通用的资源管理系统,其架构包括以下关键组件:
1. **ResourceManager (RM)**: RM是全局的资源管理器,运行在一个独立的服务器上,负责整个集群的资源分配和回收。它集中管理内存、带宽和内核等核心资源,确保它们公平地分配给各个应用程序。
2. **NodeManager (NM)**: 每个节点上都有一个NodeManager,它是RM的代理,负责在本地执行和管理ApplicationMaster(AM)提交的Container。当用户提交应用程序时,RM会与NM协作来启动Container,并监控其状态。
3. **ApplicationMaster (AM)**: AM是每个应用程序的管理者,负责一个应用程序实例的生命周期管理。它负责动态调整资源需求,协调作业执行流程,并与RM保持心跳,报告Container的状态。
4. **Container**: 是YARN中的基本执行单元,由AM在NodeManager上启动并运行。一个应用程序可以包含多个Container,它们共享集群资源并执行特定任务。
用户通过客户端提交应用程序,YARN平台作为中介,提供资源和服务,使得用户可以直接与平台交互,而无需关心底层的资源管理和调度细节。这种设计极大地提高了系统的可用性和性能,使得YARN能够支持多种计算框架,并简化了开发者的使用体验。
YARN的引入是对Hadoop MapReduce架构的重大革新,它解决了旧体系中的局限性,促进了大数据处理的更高效和灵活的部署。通过分离资源管理和作业调度,YARN为Hadoop生态系统的进一步扩展和优化奠定了坚实的基础。
yarn入门入门——yarn的架构及作业调度的架构及作业调度
1、yarn产生背景
mapReduce存在问题:
JobTracker单点故障
JobTracker承受的访问压力大,影响系统扩展
不支持MapReduce之外的计算框架,比如Storm,spark,flink
2、yarn的核心思想
是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,YARN的基本思想是将JobTracker的两个主要功能(资源管理
和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的
ApplicationMaster(AM)。
它由下面几大构成组件:
ResourceManager:负责为集群中的所有应用程序分配资源
每个节点代理 的NodeManager
每个应用对应一个ApplicationMaster
一个ApplicationMaster拥有多个Container,Containner在NodeManager上运行
运行在独立节点上的RM和NM一起组成了YARN的核心且构成了这个平台。AM和相应的Container一起组成了一个Yarn的应用
程序。从YARN的角度来看,所有用户通过提交应用程序,然后利用该平台提供的资源来进行交互。从最终用户的角度看,他
们可能是直接在YARN平台上通过运用应用程序和YARN进行交互。
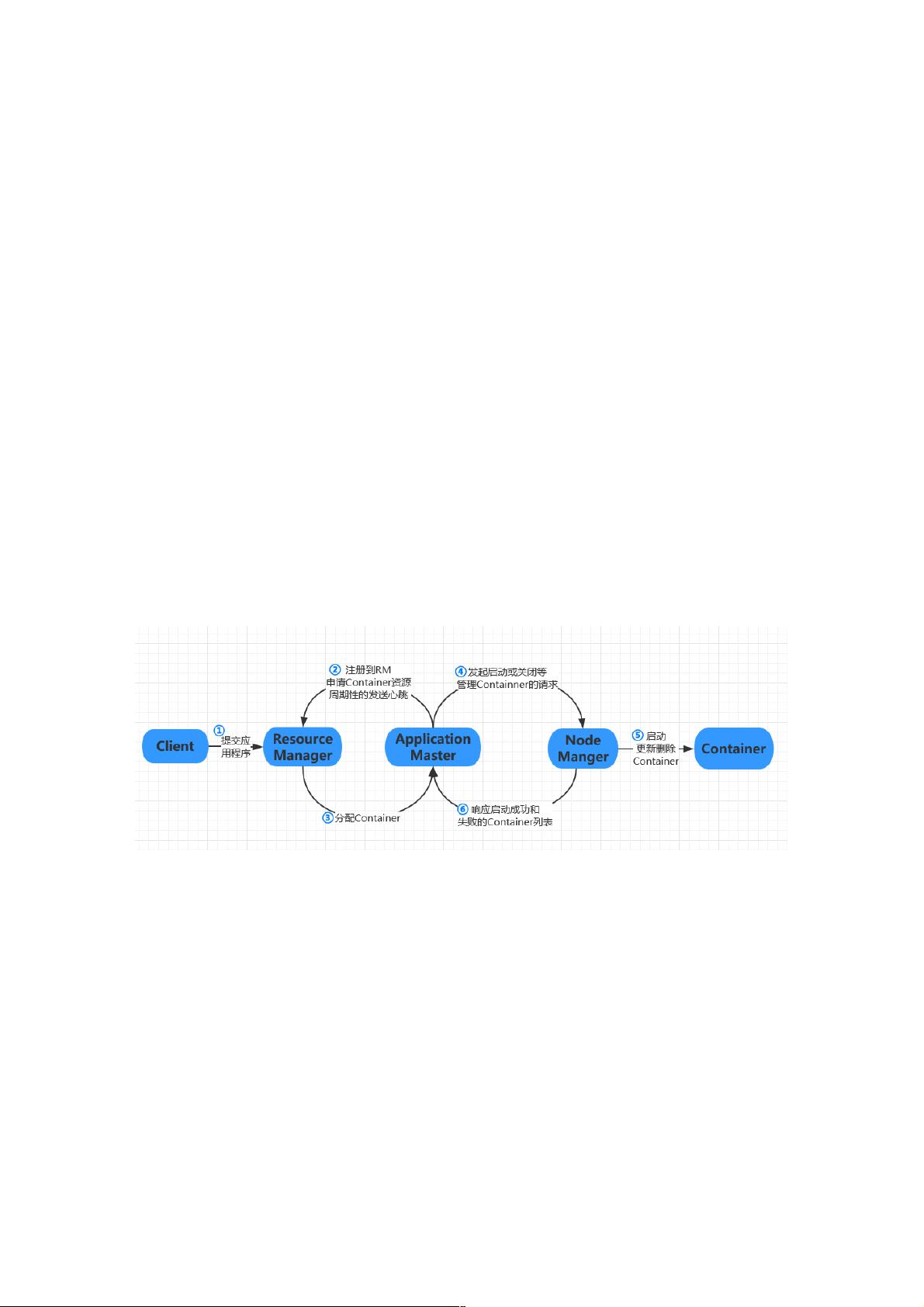
3、工作机制概述
Client向RM提交应用程序,应用程序提交到RM后,AM注册到RM上,RM计算所需资源并向RM提出申请,RM返给AM资源信
息,AM向NM发起启动container的请求,container启动后,NM将启动成功和启动失败的container列表发送给AM,由AM重新
向RM申请资源,期间AM和NM定期的向RM发送心跳。
4、组件简介
4.1、ResourceManager(RM)
RM作为一个独立的守护进程运行在专有机器上,RM拥有集群上所有资源的信息,是集群所有资源的仲裁者,只负责给应用
进行资源的划分和资源的收回。这里的资源主要指:内存,带宽,内核数等。
4.2、ApplicationMaster(AM)
ApplicationMaster管理一个在YARN内运行的应用程序的每个实例,每个应用程序对应唯一一个AM。 负责管理作业的生命周
期,包括动态的增加和减少资源使用,管理作业执行流程,处理故障和计算偏差,以及执行其本地优化。
4.3、NodeManager(NM)
管理集群中独立的计算节点。
NM是每个节点上的资源和任务管理器。一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container运行状态;
另一方面,它接收并处理来自AM的 Container 启动/停止等各种请求。
下载后可阅读完整内容,剩余5页未读,立即下载
2013-11-01 上传
2012-05-17 上传
2021-01-20 上传
2021-04-25 上传
2023-12-15 上传
2021-12-31 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38614462
- 粉丝: 4
- 资源: 965
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
