使用PyTorch构建共享单车数量预测模型
21 浏览量
更新于2024-07-15
收藏 770KB PDF 举报
"本文将引导读者使用PyTorch构建一个共享单车数量预测模型,通过实际操作理解神经网络的工作原理和数据预处理技术。"
在本文中,我们探讨的是如何利用PyTorch这一强大的深度学习框架来解决共享单车分布不均衡的问题。首先,我们了解到共享单车的普及虽然带来了出行的便利,但也产生了单车分布不均的困扰,尤其是在早晚高峰期。为了解决这个问题,共享单车公司需要预测不同地点在特定时间的单车需求量,以便进行有效的调度。
构建一个预测模型,我们需要数据。本例中,我们使用的是国外公开的CapitalBikeshare数据集,涵盖了2011年至2012年间某地区的单车使用信息,包括日期、假期状态、天气条件、风速等特征,以及关键的单车使用量(cnt)。这些数据为我们构建预测模型提供了基础。
在使用PyTorch构建模型之前,首先要做的是数据预处理。这包括清洗数据,处理缺失值,将分类变量转换为数值型,归一化数值特征,以及将数据集划分为训练集和测试集。对于时间序列数据,还可能涉及时间窗口的创建,以便模型能捕捉到时间序列中的模式。
接下来,我们将构建神经网络模型。PyTorch提供了动态计算图机制,使得模型构建灵活且易于调试。模型通常包含输入层、隐藏层和输出层,其中隐藏层可以包含多个全连接层(Dense Layer),每个层后跟随一个激活函数,如ReLU,用于引入非线性。模型的优化器(如Adam)和损失函数(如均方误差MSE)也是关键组成部分,它们负责调整模型参数以最小化预测与实际值之间的差距。
在训练模型时,我们将使用批量梯度下降(Batch Gradient Descent)或其变种,如随机梯度下降(SGD)和小批量梯度下降,迭代地更新权重。在每轮迭代中,模型会根据训练数据预测单车使用量,然后计算损失并反向传播误差,调整权重以减少损失。
训练完成后,我们会评估模型在测试集上的表现,看其预测效果如何。为了更好地理解模型的内部工作,可以使用可视化工具如TensorBoard或者直接在PyTorch中检查权重和激活值,以洞察哪些神经元对预测结果起着关键作用。
通过这个项目,读者不仅能够掌握PyTorch的基本用法,还能深入理解神经网络的结构和训练过程,以及如何应用这些知识解决实际问题。此外,还会学到如何解析和处理时间序列数据,这对于许多其他领域的预测任务同样具有指导意义。这是一个很好的起点,可以帮助初学者进入深度学习的世界,并为更复杂的预测任务打下坚实的基础。
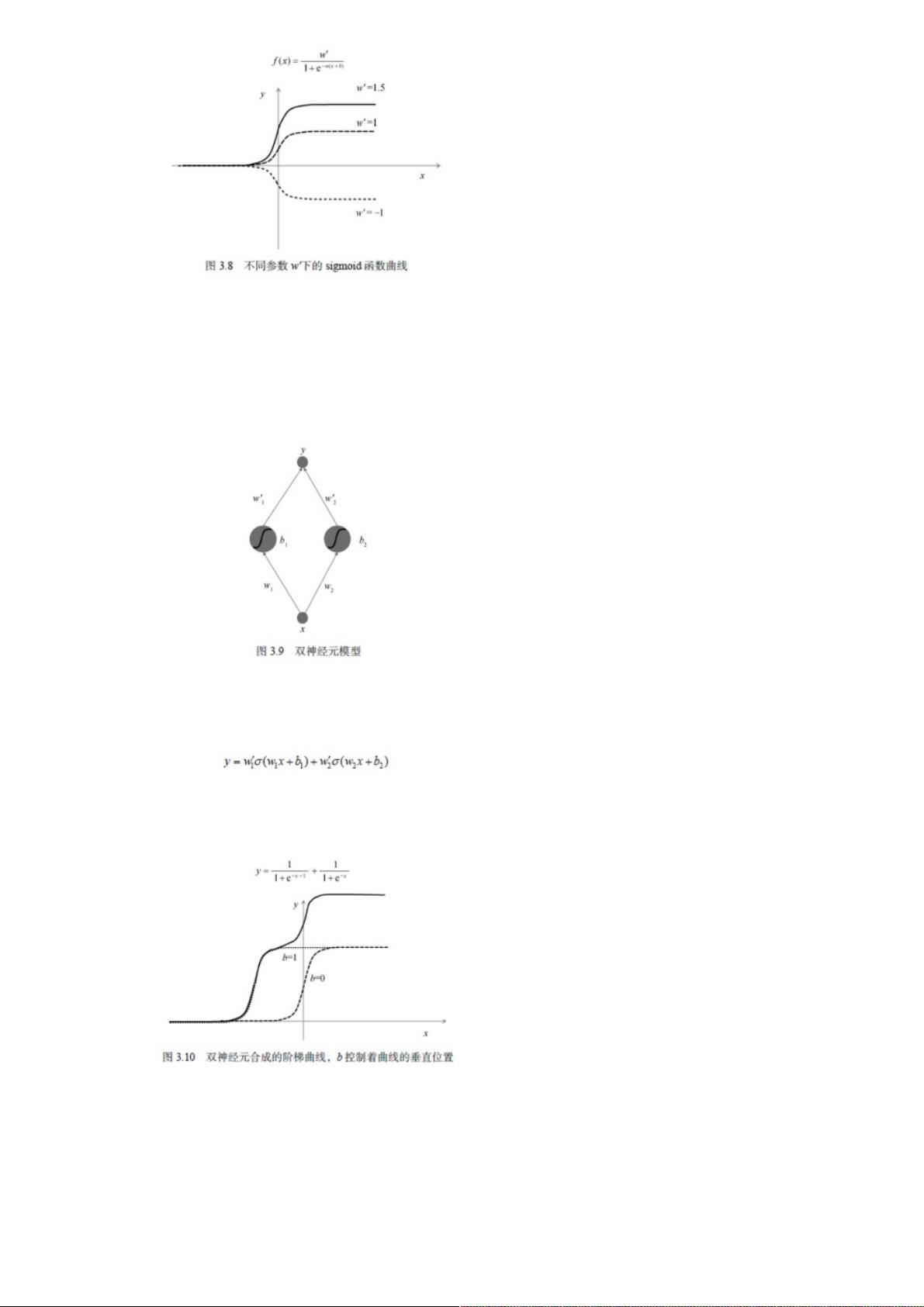
不难看出,当w' > 0的时候,w'控制着曲线的高矮;当w' < 0的时候,曲线的方向发生上下颠倒。
可见,通过控制w、w'和b这3个参数,我们可以任意调节从输入x到输出y的函数形状。但是,无论如何调节,这条曲线永远都
是S形(包括倒S形)的。要想得到更加复杂的函数图像,我们需要引入更多的神经元。
3.2.3 两个隐含层神经元两个隐含层神经元
下面我们把模型做得更复杂一些,看看两个隐含层神经元会对曲线有什么影响,如图3.9所示。
输入信号进入网络之后就会兵分两路,一路从左侧进入第一个神经元,另一路从右侧进入第二个神经元。这两个神经元分别完
成计算,并通过w'1和w'2进行加权求和得到y。所以,输出y实际上就是两个神经元的叠加。这个网络仍然是一个将x映射到y的
函数,函数方程为:
在这个公式中,有w1, w2, w'1, w'2, b1, b2这样6个不同的参数。它们的组合也会对曲线的形状有影响。
例如,我们可以取w1=w2=w'1=w'2=1,b1=-1,b2=0,则该函数的曲线形状如图3.10所示。
由此可见,合成的函数图形变为了一个具有两个阶梯的曲线。
让我们再来看一个参数组合,w1=w2=1,b1=0,b2=-1,w'1=1,w'2=-1,则函数图形如图3.11所示。
剩余16页未读,继续阅读
2020-06-13 上传
2021-05-17 上传
2020-09-16 上传
2023-03-11 上传
2023-05-01 上传
2023-09-11 上传
2023-07-08 上传

weixin_38618540
- 粉丝: 3
- 资源: 943
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
