智能时尚计算机视觉技术:深度探索与应用综述
需积分: 10 144 浏览量
更新于2024-07-15
收藏 10.64MB PDF 举报
"这篇综述论文深入探讨了智能时尚与计算机视觉技术的融合,由WEN-HUANG CHENG、SIJIE SONG、CHIEH-YUN CHEN、SHINTA MICHUSNUL HIDAYATI和JIAYING LIU等人撰写,涉及四大主题:时尚检测、时尚分析、时尚合成和时尚推荐。"
在计算机视觉领域,智能时尚正逐渐成为研究热点。这篇论文详细总结了超过200项关键研究,旨在推动智能时尚的发展。首先,时尚检测是该领域的基础,包括地标检测(识别服装上的特定特征)、时尚解析(理解衣物的结构和元素)和物品检索(找到与给定图像相似的服装)。这些技术使计算机能够理解和识别不同类型的时尚元素。
其次,时尚分析涵盖了属性识别(识别衣物的颜色、样式等属性)、风格学习(理解并模仿时尚趋势)以及流行度预测(预测某款服装或风格的受欢迎程度)。这些分析有助于品牌和零售商做出市场决策,适应快速变化的时尚潮流。
第三部分,时尚合成主要涉及风格转移(将一种风格应用于另一种图像)、姿势变换(将衣物从一个姿势迁移到另一个姿势)和物理模拟(确保虚拟衣物在不同动态条件下的真实感)。这些技术在虚拟试衣间和在线购物体验中起着关键作用,提供更逼真的预览效果。
最后,时尚推荐系统是智能时尚中的一个重要组成部分,包括时尚兼容性分析(判断两件或多件衣物是否搭配)、 outfit匹配(创建协调的服装组合)和发型建议(根据个人特征推荐适合的发型)。这些推荐系统利用机器学习算法,为用户提供个性化的时尚指导,提升购物体验。
这篇论文全面概述了智能时尚计算机视觉技术的现状和进展,对研究者和业界人员了解这一领域的最新动态具有很高的参考价值。随着技术的不断进步,我们可以期待智能时尚在零售、广告、娱乐等领域发挥更大的作用,改变我们与时尚互动的方式。
Fashion Meets Computer Vision: A Survey 7
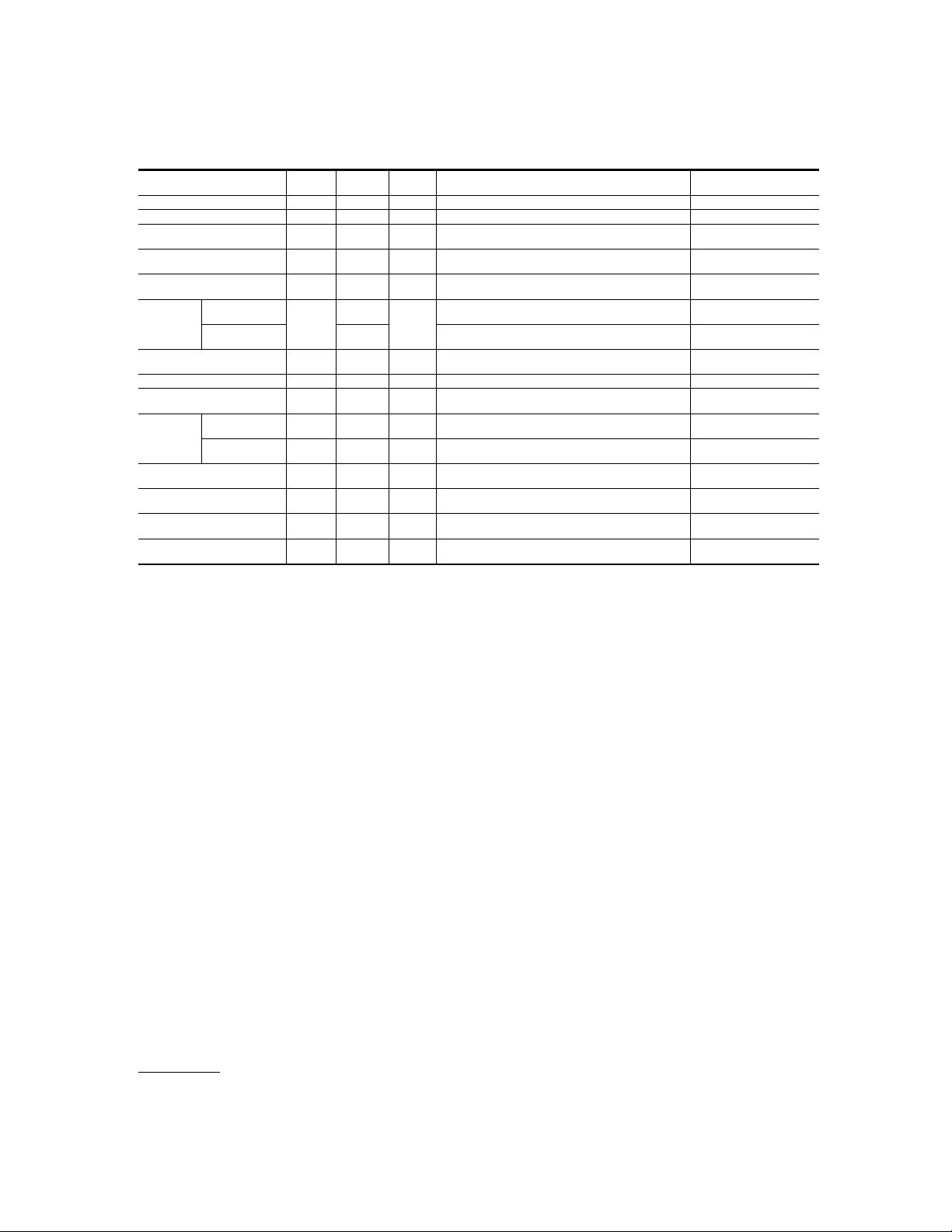
Table 3. Summary of the benchmark datasets for fashion parsing task.
Dataset name
Publish
time
# of
photos
# of
classes
Key features
Sources
Fashionista dataset [206]
2012 158,235 56
Annotated with tags, comments, and links Chictopia.com
Daily Photos (DP) [32]
2013 2,500 18
High resolution images; Parselet definition Chictopia.com
Paper Doll dataset [205, 207]
2013 339,797 56
Annotated with metadata tags denoting characteris-
tics, e.g., color, style, occasion, clothing type, brand
Fashionista [206],
Chictopia.com
Clothing Co-Parsing (CCP)
SYSU-Clothes [106, 212]
2014 2,098 57
Annotated with superpixel-level or image-level tags Online shopping websites
Colorful-Fashion Dataset
(CFD) [116]
2014 2,682 23
Annotated with 13 colors Chictopia.com
ATR [107]
Benchmark
2015
5,867
18
Standing people in frontal/near-frontal view with good
visibilities of all body parts
Fashionista [206], Daily
Photos [32], CFD [116]
Human Parsing
in the Wild
1,833
Annotated with pixel-level labels N/A
Chictopia10k [108]
2015 10,000 18
It contains real-world images with arbitrary postures,
views and backgrounds
Chictopia.com
LIP [41, 105]
2017 50,462 20
Annotated with pixel-wise and body joints Microsoft COCO [111]
PASCAL-Person-Part [196]
2017 3,533 14
It contains multiple humans per image in uncon-
strained poses and occlusions
N/A
MHP
v1.0 [98]
2017 4,980 18
There are 7 body parts and 11 clothes and accessory
categories
N/A
v2.0 [224]
2018 25,403 58
There are 11 body parts and 47 clothes and accessory
categories
N/A
Crowd Instance-level Human
Parsing (CIHP) [40]
2018 38,280 19
Multiple-person images; pixel-wise annotations in
instance-level
Google, Bing
ModaNet [227]
2018 55,176 13
Annotated with pixel-level labels, bounding boxes,
and polygons
PaperDoll [205]
DeepFashion2 [38]
2019 491,000 13
A versatile benchmark of four tasks including clothes
detection, pose estimation, segmentation, and retrieval.
DeepFashion [123],
Online shopping websites
Fashionpedia [80]
2020 48,000 46
There are 294 fine-grained attributes. It contains high
resolution with 1710 × 2151 to maintain more details
Flickr, Free license
photo websites
N/A: there is no reported information to cite
human parsing. This work won the 1
𝑠𝑡
place within all three human parsing tracks in the 2
𝑛𝑑
Look
Into Person (LIP) Challenge
5
. For multi-person parsing, they designed a global to local prediction
process based on CE2P cooperating with Mask R-CNN to form M-CE2P framework and achieved
the multi-person parsing goal.
In 2019, hierarchical graph was considered for human parsing tasks [
39
,
187
]. Wang et al. [
187
]
defined the human body as a hierarchy of multi-level semantic parts and employed three processes
(direct, top-down, and bottom-up) to capture the human parsing information for better parsing
performance. For tackling human parsing in various domain via a single model without retraining
on various datasets, Gong et al. [
39
] comprised hierarchical graph transfer learning based on the
conventional parsing network to constitute a general human parsing model, Graphonomy
6
, which
consisted of two processes. It first learned and propagated compact high-level graph representation
among the labels within one dataset, and then transferred semantic information across multiple
datasets.
2.2.2 Benchmark Datasets. There are multiple datasets for fashion parsing, most of which are
collected from Chictopia
7
, a social networking website for fashion bloggers. Table 3 summarizes
the benchmark datasets for fashion parsing in more detail. To date, the most comprehensive one is
the LIP dataset [
41
,
105
], containing over 50,000 annotated images with 19 semantic part labels
captured from a wider range of viewpoints, occlusions, and background complexity.
2.2.3 Performance Evaluations. There are multiple metrics for evaluating fashion parsing meth-
ods: (1) average Pixel Accuracy (aPA) as the proportion of correctly labeled pixels in the whole
image, (2) mean Average Garment Recall (mAGR), (3) Intersection over Union (IoU) as the ratio of
5
https://vuhcs.github.io/vuhcs-2018/index.html
6
https://github.com/Gaoyiminggithub/Graphonomy
7
http://chictopia.com
, Vol. 1, No. 1, Article . Publication date: January 2021.

剩余38页未读,继续阅读
1095 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
