分库分表后全局唯一ID生成策略:业务字段与生成ID的权衡
需积分: 0 46 浏览量
更新于2024-08-05
收藏 538KB PDF 举报
在分布式数据库系统中,保证分库分表后的全局唯一性(主键)生成是一项关键任务。分库分表的目的是提高系统的可扩展性和性能,但同时也带来了挑战,特别是确保数据一致性。本文主要探讨如何在实现数据分片和读写分离后,处理主键生成的全局唯一性问题。
首先,理解主键选择的重要性。数据库的主键需满足唯一性和稳定性,通常有两种策略:
1. **业务字段为主键**:例如用户表中,常用手机号、电子邮件或身份证号作为主键。然而,这在某些情况下可能不合适。例如评论表中,由于一条评论可能对应多个用户,且用户的联系方式可能会改变,因此这些字段不适合做主键。另外,像邮箱和手机号码并不能完全保证唯一性,且用户更换联系方式可能导致数据同步问题。
2. **自动生成唯一ID**:这是另一种常见的选择。这种方式利用时间戳或者其他算法生成的数字,确保每次插入都是唯一的。但需要注意的是,如果时间戳只记录秒,需要设计合理的范围以避免冲突,例如在一定时间段内使用有序的递增ID。
在分库分表场景下,由于数据分布到多个节点,传统的基于业务字段的主键方法可能受到限制。例如,查询时必须包含分区键,而聚合查询可能效率低下。因此,需要特别关注如何设计一个在分布式环境中既能保持唯一性又能支持高效查询的主键生成策略。
一种解决方案是结合业务逻辑和时间戳,比如在用户表中,可以使用用户的唯一标识(如用户ID)与时间戳相结合生成复合主键,例如`user_id + timestamp`。这样即使用户ID发生变化,通过时间戳的增量可以保证全局唯一性,同时仍能支持高效的查询。
另一个策略是采用UUID(通用唯一识别符),这是一种专门为分布式系统设计的全局唯一ID,生成过程复杂但确保唯一。然而,UUID可能会导致数据存储空间增加,因此在性能和空间效率之间需要权衡。
处理分布式数据库分库分表后的全局唯一性问题,需要综合考虑业务需求、数据唯一性、查询效率以及数据存储成本。选择合适的主键策略是提升系统稳定性和性能的关键,同时也要适应不断变化的业务场景和技术发展趋势。
10-发号器:如何保证分库分表后ID的全局唯⼀性?10-发号器:如何保证分库分表后ID的全局唯⼀性?
你好,我是唐扬。
在前⾯两节课程中,我带你了解了分布式存储两个核⼼问题:数据冗余和数据分⽚,以及在传统关系型数据
库中是如何解决的。当我们⾯临⾼并发的查询数据请求时,可以使⽤主从读写分离的⽅式,部署多个从库分
摊读压⼒;当存储的数据量达到瓶颈时,我们可以将数据分⽚存储在多个节点上,降低单个存储节点的存储
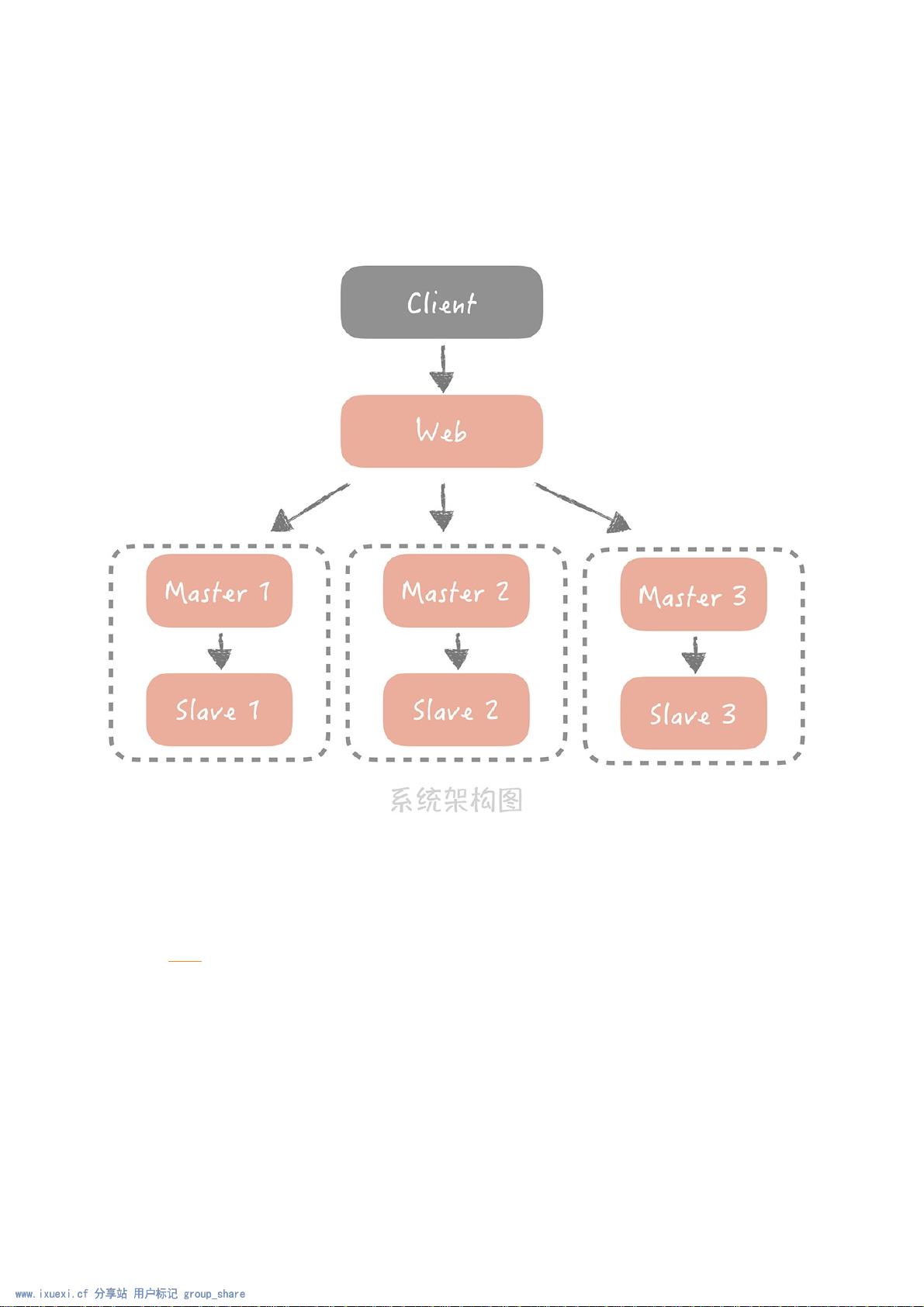
压⼒,此时我们的架构变成了下⾯这个样⼦:
你可以看到,我们通过分库分表和主从读写分离的⽅式解决了数据库的扩展性问题,但是在09讲我也提到
过,数据库在分库分表之后,我们在使⽤数据库时存在的许多限制,⽐⽅说查询的时候必须带着分区键;⼀
些聚合类的查询(像是count())性能较差,需要考虑使⽤计数器等其它的解决⽅案,其实分库分表还有⼀
个问题我在09讲中没有提到,就是主键的全局唯⼀性的问题。本节课,我将带你⼀起来了解,在分库分表后
如何⽣成全局唯⼀的数据库主键。
不过,在探究这个问题之前,你需要对“使⽤什么字段作为主键”这个问题有所了解,这样才能为我们后续
探究如何⽣成全局唯⼀的主键做好铺垫。
数据库的主键要如何选择?数据库的主键要如何选择?
数据库中的每⼀条记录都需要有⼀个唯⼀的标识,依据数据库的第⼆范式,数据库中每⼀个表中都需要有⼀
个唯⼀的主键,其他数据元素和主键⼀⼀对应。
那么关于主键的选择就成为⼀个关键点了,那么关于主键的选择就成为⼀个关键点了,⼀般来讲,你有两种选择⽅式:
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2022-02-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

白羊带你成长
- 粉丝: 30
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- MyProjects:Meus projetos
- strip-ansi-escapes
- aws-cicd-workshop-cpt
- OPPOA71 73 79 手机 原厂维修图纸电路图PCB位件图资料.zip
- elasticsearch:此仓库用于在ppc64le的ubi8上创建用于Elasticsearch的映像
- portfolio-project
- HitboxPlugin:BakkesMod Hitbox 插件
- Android ActionSheet动画效果实现
- google-homepage
- LoadingImageView:UIImageView 的加载指示器,用 Swift 编写
- SCHOOL-WEBSITE
- aayushmau5
- 参考资料-72_企业职工离职管理制度.zip
- arrayhua.github.io:高级开发工程师简历
- 类似UC 浏览器复制功能
- groot:使用子模块管理 git 存储库(已失效)
