理解Python爬虫:通用爬虫与聚焦爬虫的工作原理
"本文主要介绍了Python爬虫的基本原理,包括通用爬虫和聚焦爬虫的定义,以及通用搜索引擎的工作流程,涉及URL抓取、数据存储和预处理等关键步骤。"
在信息技术领域,网络爬虫是获取大量网络数据的重要工具。Python作为一门流行的编程语言,因其简洁易懂的语法特性,常被用于开发爬虫程序。本文以“浅谈Python爬虫原理与数据抓取”为主题,深入探讨了爬虫技术。
首先,我们区分了两种主要类型的网络爬虫:通用爬虫和聚焦爬虫。通用爬虫是搜索引擎抓取系统的核心部分,如百度、Google、Yahoo等,它们的任务是广泛地抓取互联网上的网页,构建一个互联网内容的本地备份,以供搜索引擎建立索引。通用搜索引擎的工作原理包括三个主要步骤:抓取网页、数据存储和预处理。
抓取网页是爬虫工作的起始点。这个过程通常从一组初始的种子URL开始,这些URL被放入待抓取队列。爬虫会持续从队列中取出URL,解析DNS获取主机IP,然后下载网页内容,存入已下载的网页库,并将抓取的URL加入已抓取队列。爬虫通过分析已抓取的URL来发现新的链接,不断扩展其抓取范围。
获取新网站URL的方式主要有三种:新网站主动向搜索引擎提交、设置外部链接以及通过搜索引擎与DNS服务商的合作。但爬虫的爬行行为受到Robots协议的约束,网站所有者可以通过该协议指示搜索引擎哪些页面应被爬取,哪些不应。
数据存储阶段,爬取的网页内容会被保存在原始页面数据库中,保持与用户浏览器接收到的HTML内容一致。同时,搜索引擎还会进行重复内容检测,避免收录过多的重复信息。
预处理是搜索引擎提升检索效率的关键步骤,包括HTML去噪(去除无关的HTML标签)、文本分词、词干提取、建立倒排索引等,目的是将非结构化的网页数据转化为可快速查询的结构化信息。
Python爬虫原理涉及网络请求、网页解析、数据存储等多个方面,而实现高效爬取则需考虑如何遵循规则、避免重复、处理异常和优化抓取策略。了解这些基础知识对于进行有效的数据抓取和分析至关重要。在实际应用中,开发者还需要关注法律法规,确保爬虫活动的合法性,尊重网站的Robots协议,合理使用爬取的数据。
浏览器发送浏览器发送HTTP请求的过程:请求的过程:
当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
当我们在浏览器输入URLhttp://www.baidu.com的时候,浏览器发送一个Request请求去获取http://www.baidu.com的html文件,服务器把Response文
件对象发送回给浏览器。
浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获
取图片,CSS文件,或者JS文件。
当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
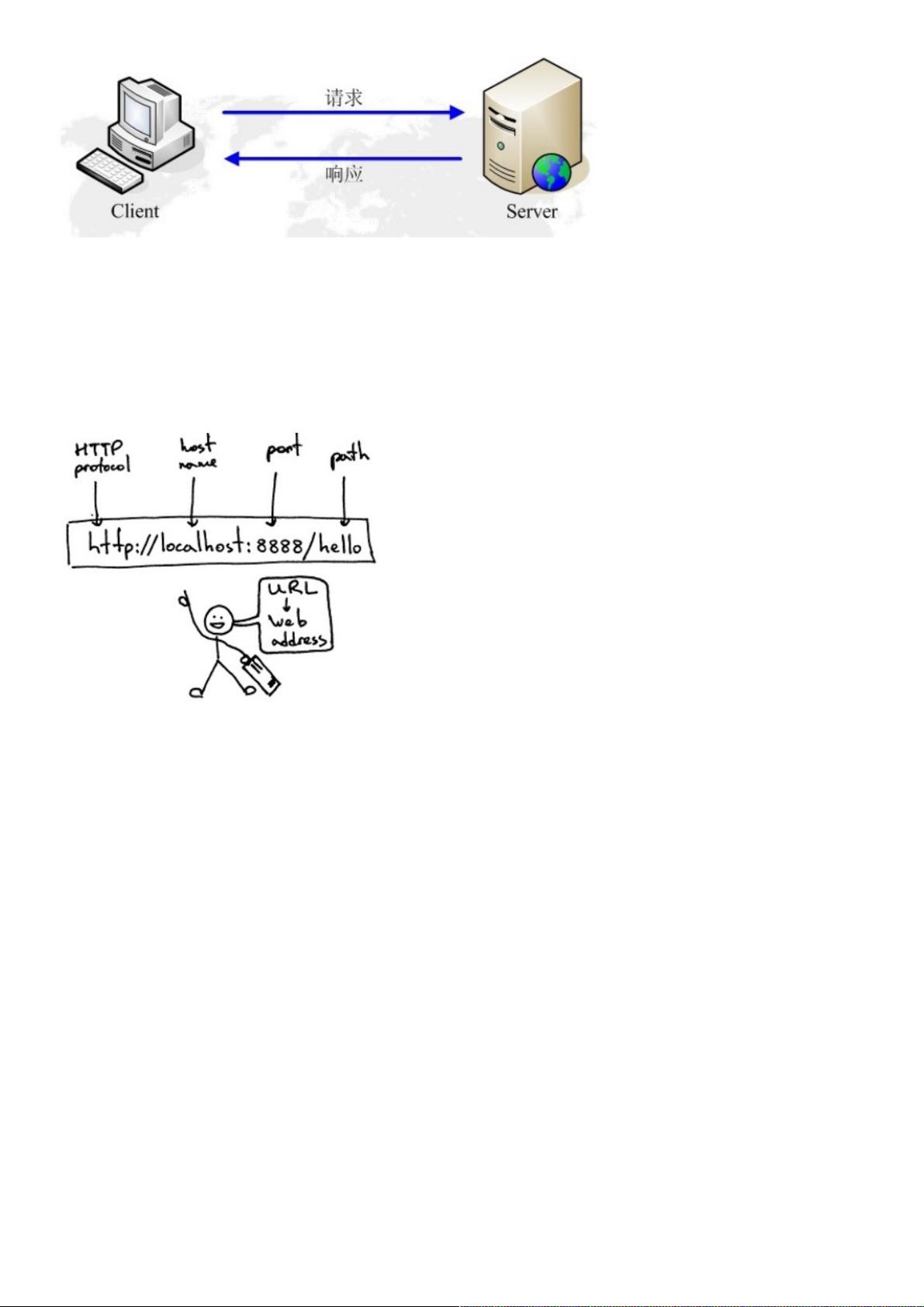
URL(Uniform / Universal Resource Locator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp)
host:服务器的IP地址或者域名
port#:服务器的端口(如果是走协议默认端口,缺省端口80)
path:访问资源的路径
query-string:参数,发送给http服务器的数据
anchor:锚(跳转到网页的指定锚点位置)
例如:
ftp://192.168.0.116:8080/index
http://www.baidu.com
http://item.jd.com/11936238.html
客户端HTTP请求
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行、请求头部、空行、请求数据
四个部分组成,下图给出了请求报文的一般格式。
剩余10页未读,继续阅读
2023-03-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-06-09 上传
2024-05-28 上传

weixin_38607088
- 粉丝: 5
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
