汇顶科技GH3011心率测量芯片手册
需积分: 41 179 浏览量
更新于2024-07-09
收藏 1.12MB PDF 举报
"GH3011_Datasheet_V0.3.pdf"
《汇顶GH3011心率测量芯片手册》提供了关于汇顶科技GH3011心率芯片的详细技术信息,该手册主要涵盖了产品的概述、应用信息、电源管理与复位、通信接口、工作模式以及电气参数等方面,旨在帮助设计者理解和应用这款心率传感器。
1. 产品概述
- 概述:GH3011是一款专用于心率测量的高性能芯片,适用于健康监测设备和智能穿戴产品。
- 特点:可能包括高精度、低功耗、快速响应等特性。
- 技术指标:详细的技术参数,如测量范围、误差率、工作电压、电流消耗等。
2. 应用信息
- 芯片系统简介:介绍GH3011如何集成到心率监测系统中,以及它与其他组件的交互方式。
- 管脚定义:详细列出芯片的所有引脚及其功能,包括电源、数据接口和控制信号等。
- 应用参考:提供电源方案和通信电平选择的指导,以确保正确和稳定的工作。
3. 电源管理及复位
- 芯片上电时序:规定了芯片正确启动的电源供电步骤。
- 复位:详述了芯片的复位机制,包括正常复位和硬件复位。
4. 通信接口
- IIC:解释了如何通过IIC接口进行写、读和命令传输,并给出了时序图。
- SPI:介绍了SPI接口的操作协议,包括写、读和命令协议,以及SPI的时序要求。
- 通信接口验证指南:提供了一套测试和验证通信接口正确性的流程。
5. 工作模式
- SLEEP模式:低功耗待机模式,适合长时间无需测量时使用。
- HBD模式:可能代表心率检测模式,用于实时测量心率。
- ADT模式:可能是自动检测模式,定时启动心率测量。
- 模式切换:描述了如何在不同工作模式之间进行切换。
6. 电气参数
- 极限电气参数:列出了芯片可以承受的最大和最小电压、电流等电气条件。
- 推荐工作条件:指芯片在最佳性能下的工作环境参数。
- 直流特性参数:详细列出了芯片在直流工作状态下的各种性能指标。
7. 封装
- 封装示意图:展示了芯片的实际物理形状和引脚布局。
- PCB/FPC封装推荐:提供了关于如何在电路板上布置和连接芯片的建议。
- 封装标准:可能包括了芯片封装的行业标准和规格。
这份手册是开发基于GH3011心率芯片产品的工程师的重要参考资料,它包含了设计、测试和优化系统所需的所有关键信息。通过遵循手册的指导,开发者可以确保设备的可靠性和性能达到预期标准。
GH3011 心率测量芯片
6
汇顶科技 机密信息
未经允许 不得转载
问题反馈
参数
值 单位
电源
VCC 供电电源
2.1~3.3 V
VDDIO 通信电平
1.62~VCC V
2. 应用信息
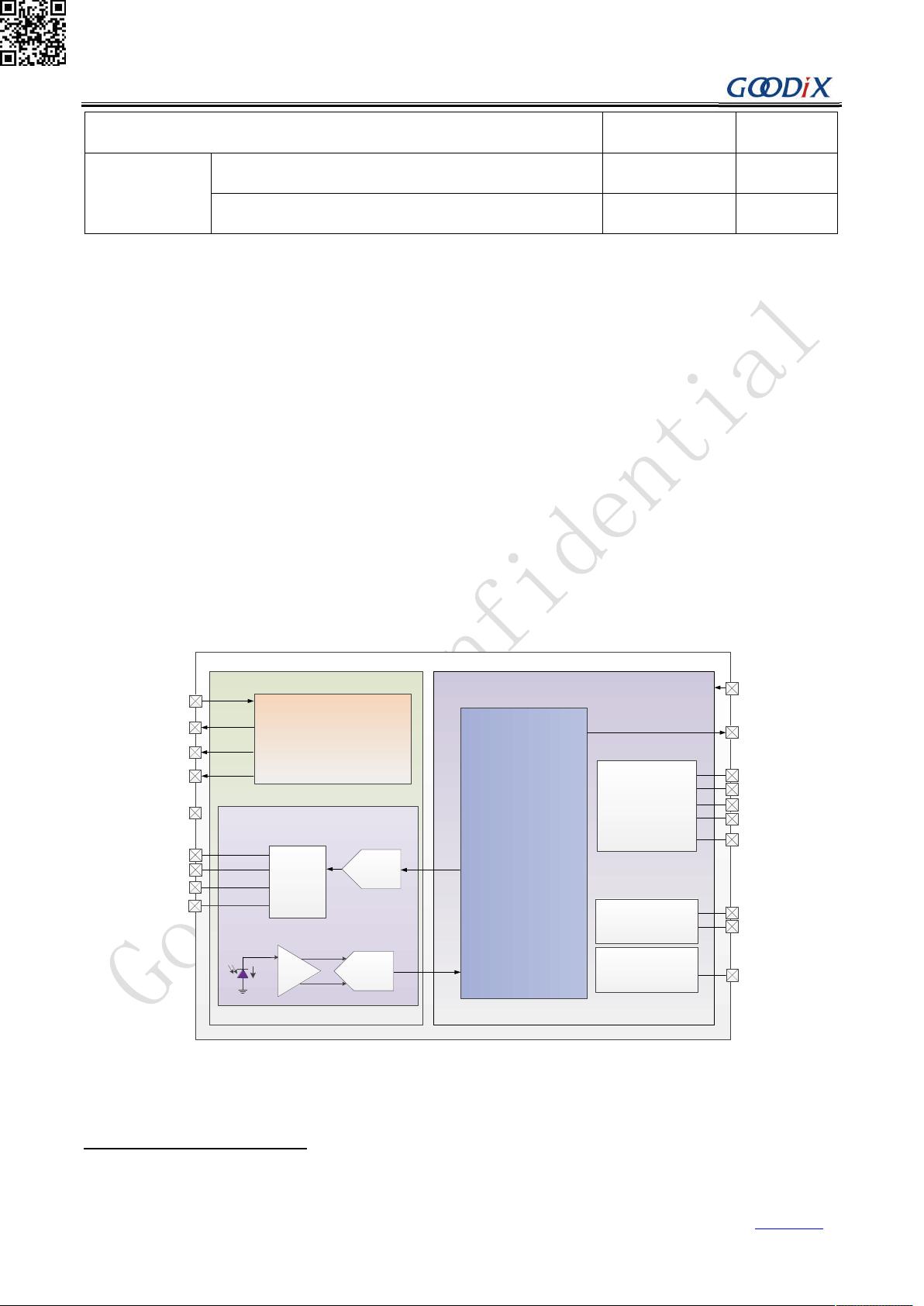
2.1 芯片系统简介
如图 1 所示,GH3011 心率检测芯片主要模块包括:
HBD Sensor、LED Driver、TIA
①
、ADC 等部件构成的 HBD 模拟前端;
实现通信功能的 IIC、SPI 模块;
PMU 电源管理、时钟系统、复位、中断等基础型电路单元;
Data Buffer、Logic Control 等数字逻辑单元。
HBD_AFE
VCC
DVDD18
AVDD18
GND
VDDIO
Current
driver
I-DAC
RSTN
CLK
CS / SDA
INT
LED_DRV2
ADC
TIA
GINT
HBD_ON
VPP
Mode_ctrl&
Data Buffer
INT Control
RSTN Control
i
PD
MOSI/SCL
MISO
IIC_EN
Communication
Control
LED_DRV1
LED_DRV0
LED_GND
PMU
图 1 GH3011 IC 系统框图
①
TIA 的作用是将输入的光电流转化为电压,作为 ADC 的输入。
剩余27页未读,继续阅读
132 浏览量
2023-06-10 上传
2023-06-01 上传
2023-02-21 上传
2023-05-11 上传
2023-05-31 上传
2024-09-22 上传
2023-07-08 上传
2023-07-23 上传

嵌入式开发-阿汤
- 粉丝: 1
- 资源: 40
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
