
MapReduce 来进行批量数据处理,可以用 Impala 来进行交互式查询(Impala 与 Hive 相似,
但底层引擎不同,提供了实时交互式 SQL 查询),对于流式数据处理可以采用开源流计
算框架 Storm。一些企业可能只会涉及其中部分应用场景,只需部署相应软件即可满足业
务需求,但是,对于互联网公司而言,通常会同时存在以上三种场景,就需要同时部署三
种不同的软件,这样做难免会带来一些问题:
� 不同场景之间输入输出数据无法做到无缝共享,通常需要进行数据格式的转换;
� 不同的软件需要不同的开发和维护团队,带来了较高的使用成本;
� 比较难以对同一个集群中的各个系统进行统一的资源协调和分配。
Spark 的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系
统,既能够提供内存计算框架,也可以支持 SQL 即席查询、实时流式计算、机器学习和
图计算等。Spark 可以部署在资源管理器 YARN 之上,提供一站式的大数据解决方案。因
此,Spark 所提供的生态系统足以应对上述三种场景,即同时支持批处理、交互式查询和
流数据处理。
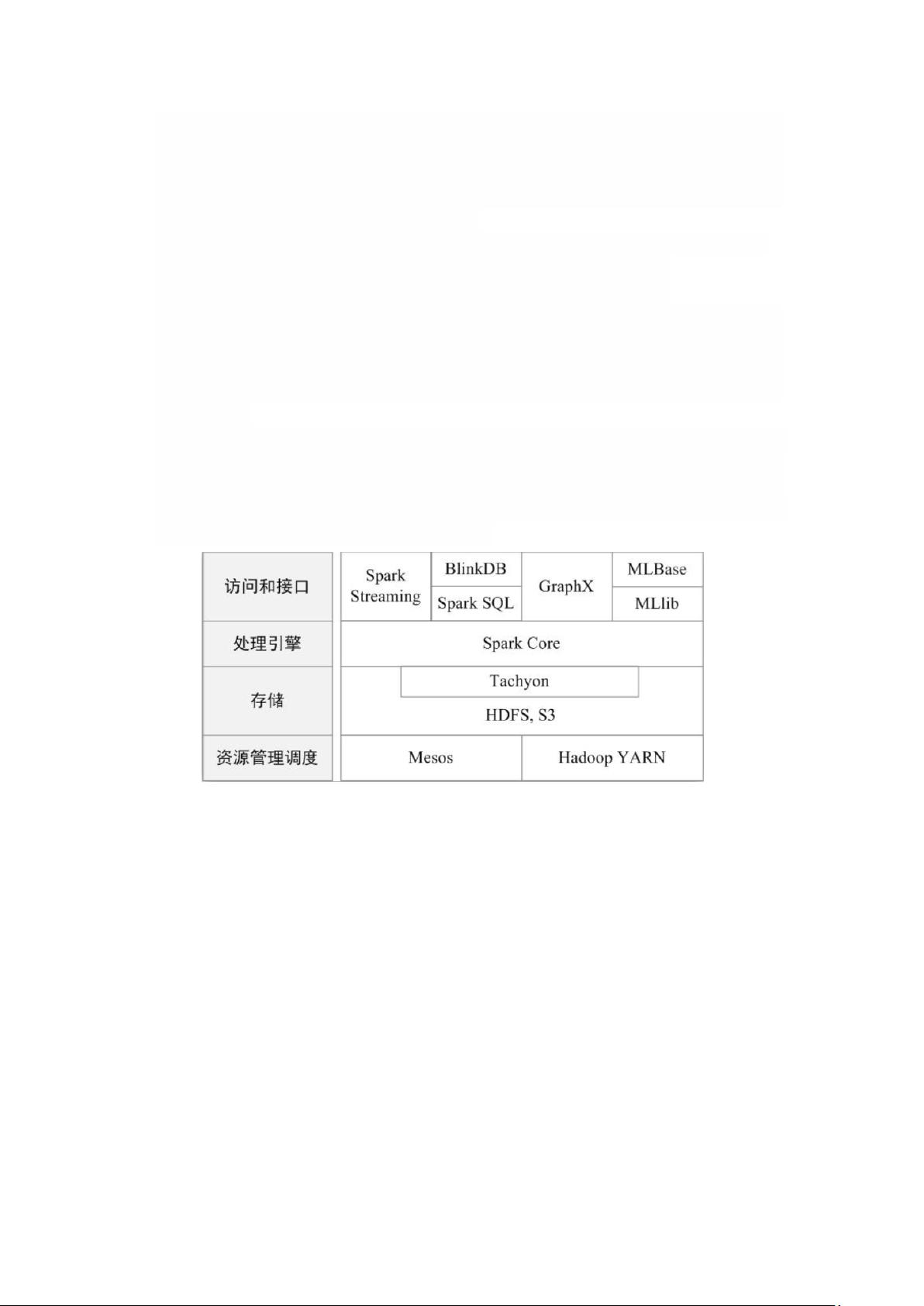
现在,Spark 生态系统已经成为伯克利数据分析软件栈 BDAS(Berkeley Data Analytics
Stack)的重要组成部分。BDAS 的架构如图所示,从中可以看出,Spark 专注于数据的处
理分析,而数据的存储还是要借助于 Hadoop 分布式文件系统 HDFS、Amazon S3 等来实
现的。因此,Spark 生态系统可以很好地实现与 Hadoop 生态系统的兼容,使得现有 Hadoop
应用程序可以非常容易地迁移到 Spark 系统中。
④架构设计
Spark 运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节
点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务
的执行进程(Executor)。其中,集群资源管理器可以是 Spark 自带的资源管理器,也可
以是 YARN 或 Mesos 等资源管理框架。
与 Hadoop MapReduce 计算框架相比,Spark 所采用的 Executor 有两个优点:一是
利用多线程来执行具体的任务(Hadoop MapReduce 采用的是进程模型),减少任务的启
动开销;二是 Executor 中有一个 BlockManager 存储模块,会将内存和磁盘共同作为存储
设备,当需要多轮迭代计算时,可以将中间结果存储到这个存储模块里,下次需要时,就
可以直接读该存储模块里的数据,而不需要读写到 HDFS 等文件系统里,因而有效减少了
开销;或者在交互式查询场景下,预先将表缓存到该存储系统上,从而可以提高读写 IO
性能。如下图所示:
剩余14页未读,继续阅读

自xing且乐观~
- 粉丝: 119
- 资源: 14
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0