
china.xilinx.com
Xilinx 全可编程器件 :出色的计算密集型系统开发平台
WP492 (v1.0.1) 2017 年 6 月 13 日
4
GPU 架构的局限性
本部分将深入研究典型的 GPU 架构,以揭示它的局限性以及如何将它们应用于各种算法和工作负载。
SIMT ALU 阵列
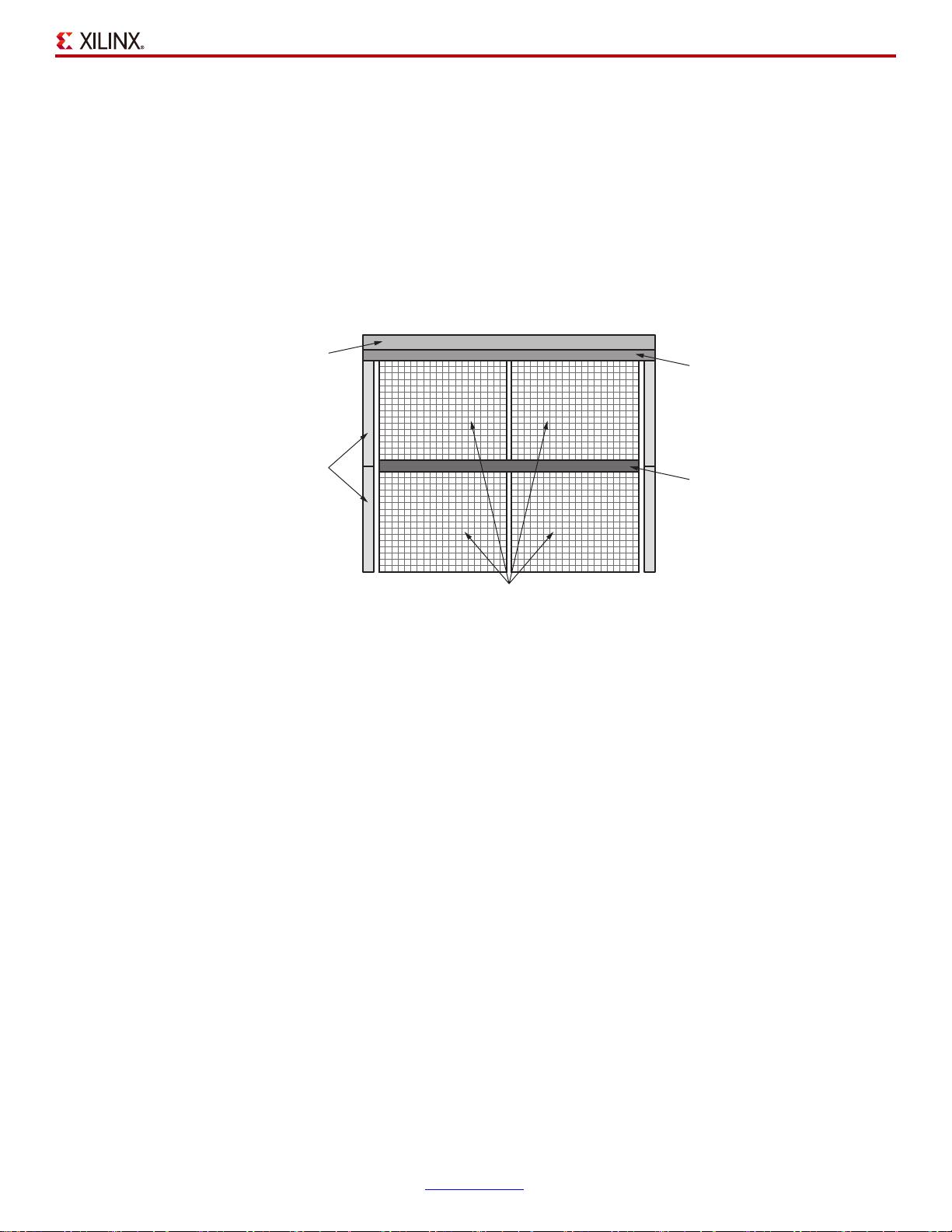
图 1 给出了典型的 GPU 方框图。通用 GPU 计算功能的核心是大型的算数逻辑单元 (ALU) 或内核阵列。
这些 ALU 通常被认为是单指令多线程 (SIMT),类似于单指令多数据 (SIMD)。
图 1 :
GPU 方框图
基本原理是将工作负载分成数千个并行的线程。需要大量 GPU 线程来防止 ALU 闲置。然后,对这些线
程进行调度,以使 ALU 组并行执行同一(单个)指令。利用 SIMT,GPU 厂商能实现相对 CPU 占位面
积更小和能效更高的方案,因为内核的很多资源都可与相同组中的其他内核共享。
然而,显然只是特定的工作负载(或部分工作负载)能被高效映射到这种大规模并行架构中 [ 参考资料 5]。
如果构成工作负载的线程不具有足够的共性或并行性(例如连续工作负载或适度并行工作负载),则
ALU 会闲置,导致计算效率降低。此外,构成工作负载的线程预期要最大化 ALU 利用率,从而产生额
外的时延。即使有英伟达的 Volta 架构中的独立线程调度这样的功能,底层架构也保持 SIMT,也需要大
规模并行工作负载。
对于连续、适度并行或稀疏工作负载,GPU 提供的计算功能和效率甚至低于 CPU [ 参考资料 6]。例如
用 GPU 实现稀疏矩阵计算 ;如果非零元素数量较少,则从性能和效率角度看 GPU 低于或等同于 CPU
[ 参考资料 7][ 参考资料 8]。
有趣的是,很多研究人员正在研究稀疏卷积神经网络,以利用很多卷积神经网络中的大规模冗余
[ 参考资料 9]。这种趋势显然在机器学习推断领域向 GPU 提出了挑战。
WP492_01_033017
PCIe Host
Interface
Memory
Controllers
PCIe 主机接口
存储器
控制器
线程接口
片上缓存
ALU 阵列
剩余16页未读,继续阅读















