HDFS:Hadoop分布式文件系统详解与实践
155 浏览量
更新于2024-08-29
收藏 603KB PDF 举报
Hadoop大数据平台架构与实践中的关键组件HDFS(Hadoop Distributed File System)是Hadoop生态系统的核心,它解决了大规模数据存储和处理的需求。当文件容量超出单机存储限制时,分布式文件系统如HDFS允许将文件分割成多个部分(分片),分布在不同的节点上,以实现高可用性和容错性。
分布式文件系统的主要组成部分包括:
1. 被管理的文件:这些是实际的数据,如文本、图像、视频等,它们被拆分成多个数据块进行存储。
2. 文件管理相关软件:这是HDFS的客户端和服务器端组件,如NameNode(元数据管理器)和DataNode(数据存储节点),共同协作管理文件的分布和访问。
3. 数据结构:HDFS采用目录树结构,类似于文件系统的层级结构,方便文件的组织和查找。
将文件分布式存储带来的挑战包括:
- 文件一致性问题:由于文件可能分布在多个节点,如何保证数据的一致性和完整性是一个挑战。
- 系统复杂性:随着节点数量的增长,系统管理和维护的复杂性也随之增加。
- 网络依赖:数据传输需要通过网络,增加了网络延迟和故障的可能性。
HDFS采用的流处理访问模式是其核心特点,这种模式针对大数据处理的需求特别合适。它强调:
- 一次性写入,多次读取:大数据通常不需要频繁修改,而是用于分析和挖掘,这就要求读取操作远比写入频繁。
- 流式读取:HDFS优化了磁盘寻址,只在首次定位文件时进行,后续只需连续读取,减少了磁盘寻址的开销。
- 高性能:适合处理大文件,因为流处理能够减少不必要的I/O操作,提高读取效率。
HDFS的文件存储策略包含:
- 分片冗余存储:文件被切分为多个数据块,每个块都有多个副本,即使某个节点发生故障,仍可以从其他副本恢复数据,保证了高可用性。
- 压缩存储:为了节省存储空间,HDFS支持数据压缩,通过无损压缩技术(如重复数据删除)去除重复数据,只保留原始数据的最小表示。
HDFS作为Hadoop生态系统的重要支柱,不仅提供了高效的文件存储和管理,还适应了大数据环境下的一次写入多次读取的工作模式,确保了大数据处理任务的顺利执行。通过理解并掌握HDFS的架构和工作原理,用户可以更好地利用Hadoop进行大数据的处理和分析。
Hadoop大数据平台架构与实践大数据平台架构与实践|HDFS
HDFS作为Hadoop的核心部分,是Hadoop中MapReduce框架的存储层。
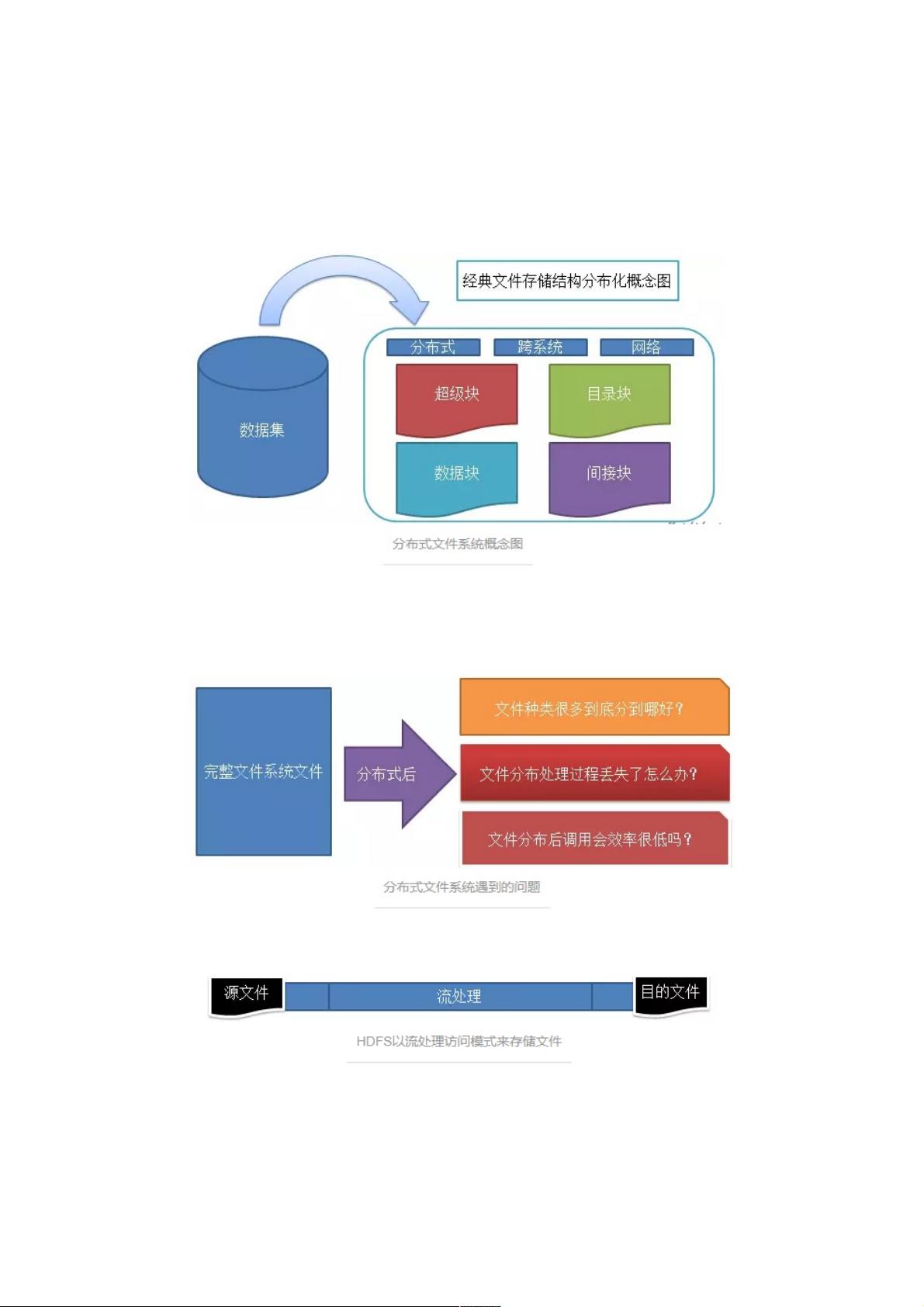
1、为什么需要分布式文件系统
当文件的大小超过了单台计算机的存储能力时,就需要将其分区存储在不同单独的计算机上。
分布式文件系统概念图文件系统的三个主要组成部分:被管理的文件、文件管理相关软件、实施文件管理所需要的数据结构
将文件分布式存储后带来的问题:文件不完整,系统复杂度加大,引入网络编程
2、HDFS对文件的读取方式:流处理访问模式
HDFS以流处理访问模式来存储文件什么是流处理访问模式呢?为什么分布式文件系统场景下这种文件访问模式更合适?
操作系统中文件访问方式有好几种,常见的是随机数据访问方式,这种方式要求文件定位、查询或者修改数据的延迟比较小,
比较适合常见数据后多次查询、读写的场景,传统关系型数据库非常符合这一点。
大数据场景与关系系数据库的场景有非常大的不同。大数据的数据源通常由源生成或从数据源直接复制而来,接着长时间在此
数据集上进行各类分析,不需要搬来搬去;这种数据访问场景是典型的一次写入,多次读取的场景(写入数据只需要生成数据
的那一次,基本没有修改数据的要求,后面就是多次读取以分析),所以这种场景下的数据访问方式更适合采用流处理方式。
流处理数据访问方式试磁盘寻址开销最小化:只需要一次寻址(起始地址),然后就是连续的流式读取。硬盘的物理构造导致
下载后可阅读完整内容,剩余6页未读,立即下载
2021-07-14 上传
2021-07-04 上传
2022-07-06 上传
2022-07-06 上传
点击了解资源详情
点击了解资源详情
2022-02-08 上传
2022-06-21 上传
2021-04-29 上传

weixin_38630612
- 粉丝: 5
- 资源: 891
 我的内容管理
展开
我的内容管理
展开







最新资源
- component-dev-test
- 编辑偏好
- conceitos-do-react
- zendea:使用Go语言编写的免费,开放源代码,自托管的论坛软件官方QQ群:656868
- DESTOON_8.0_BIZ_完整包20210518.zip
- 电子元器件识别(含图片).zip
- framework:个人的、React性的、开放的、私密的、安全的。 拥有和控制您的数据
- 【QGIS跨平台编译】之【MiniZip跨平台编译】:MacOS环境下编译成果(支撑QGIS跨平台编译,以及二次研发)
- mxjs-dropdown-menu
- MLIC:生成可解释的分类规则的新框架
- MusicBox.NET-开源
- 行业分类-设备装置-航拍无人机水上降落平台及降落方法.zip
- RDD:偶然推断RDD复制
- technical_assistant
- 斗地主单机版.zip易语言项目例子源码下载
- asp源码-C9静态文章发布系统 v1.0.zip
