大数据平台的Lambda与Kappa架构解析
50 浏览量
更新于2024-08-31
收藏 208KB PDF 举报
"大数据处理中的Lambda架构和Kappa架构"
在大数据处理领域,Lambda架构和Kappa架构是两种常见的处理模型,它们分别适用于不同的场景和需求。
Lambda架构是一种经典的处理模式,主要由三个层次组成:数据采集、批量处理和实时处理。在数据采集阶段,数据源如数据库、日志文件等通过工具如Sqoop、Flume或Kafka进行收集和传输。数据质量各异,需要根据具体情况进行预处理。批量处理部分通常涉及HDFS、MapReduce、Hive等技术,对历史数据进行离线分析,适合大规模、低延迟容忍的任务。实时处理则利用Spark Streaming或Storm等流处理框架,实现快速响应的近实时计算。最后,处理后的数据通过数据导出工具如Sqoop导入数据库,供前端应用和报表系统使用。
Kappa架构是Lambda架构的一种简化和优化,主要针对实时流处理。它主张消除Lambda架构中的批量处理层,强调所有的数据处理都应该基于事件流。在Kappa架构中,所有的计算都是事件驱动的,数据通过事件流(如Kafka)不断进行处理,没有明确的批处理和实时处理区分。这使得系统更简洁、易于维护,但可能无法很好地支持历史数据的重新处理或回溯。
Lambda架构的优点在于其健壮性,能够处理历史数据的批量计算,同时也能实时处理新数据,适合需要同时满足离线分析和实时查询的场景。然而,它的复杂性和维护成本较高,因为需要维护两套处理系统。
相比之下,Kappa架构更加轻量,适合快速响应的实时应用场景,但可能不适用于需要定期回顾历史数据的情况。而且,Kappa架构可能需要更强大的容错机制和数据一致性保证,以确保在仅处理一次事件的情况下得到正确的结果。
在选择架构时,应根据实际业务需求来决定。如果需要处理大量历史数据,同时对实时性有较高要求,Lambda架构可能是更好的选择。如果业务更侧重于实时响应,且能够接受牺牲部分离线处理能力,Kappa架构则更为合适。不论哪种架构,都需要结合实际的硬件资源、团队技能以及业务目标进行综合考虑。
大数据处理中的大数据处理中的Lambda架构和架构和Kappa架构架构
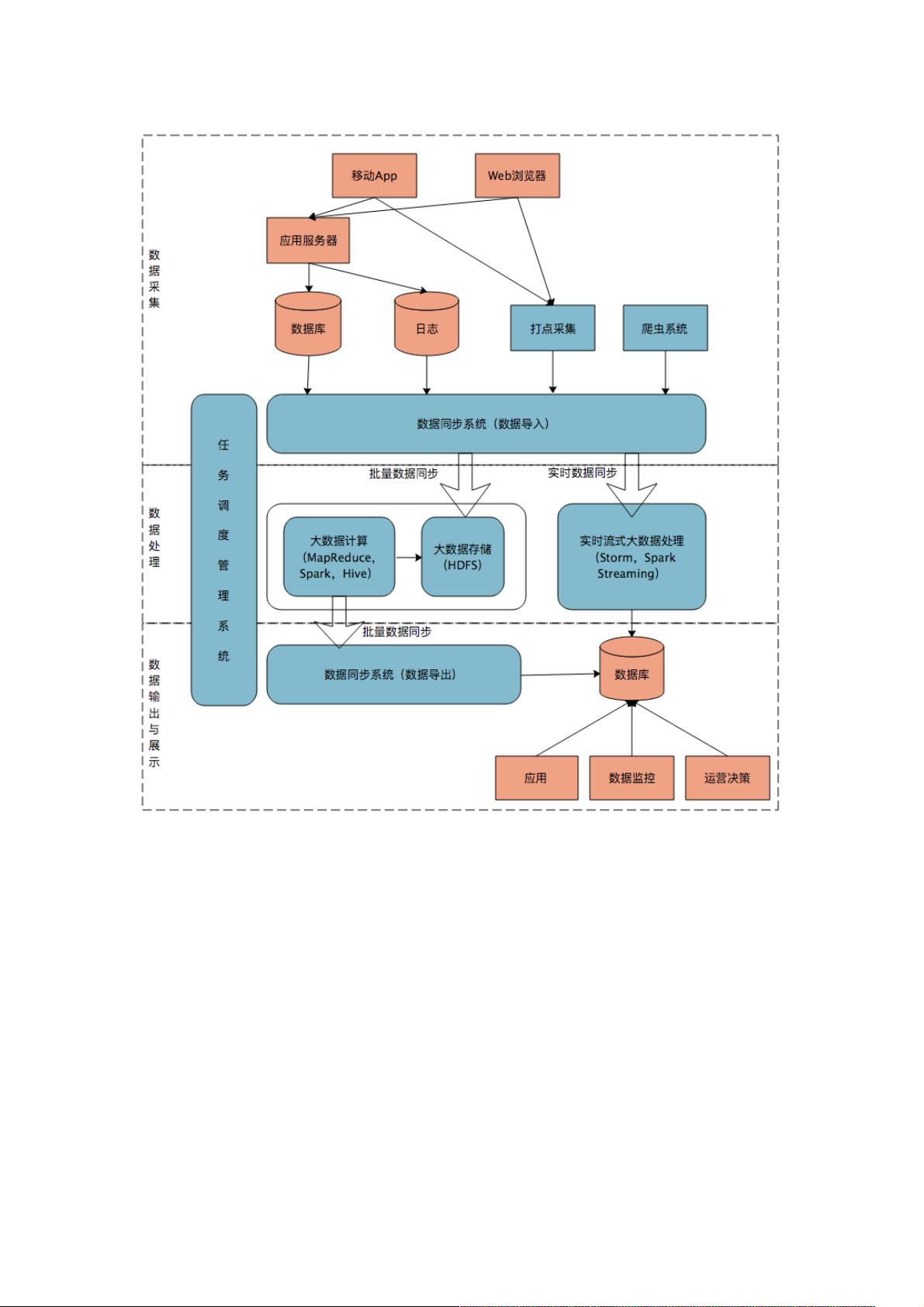
首先我们来看一个典型的互联网大数据平台的架构,如下图所示:
在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝
色的部分属于大数据相关组件,使用开源大数据产品或者自己开发相关大数据组件。
你可以看到,大数据平台由上到下,可分为三个部分:数据采集、数据处理、数据输出与展示。
数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。
数据库同步通常用 Sqoop,日志同步可以选择 Flume,打点采集的数据经过格式化转换后通过 Kafka 等消息队列进行传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以使用了,而日志和爬虫产生
的数据就需要进行大量的清洗、转化处理才能有效使用。
数据处理
这部分是大数据存储与计算的核心,数据同步系统导入的数据存储在 HDFS。MapReduce、Hive、Spark 等计算任务读取
HDFS 上的数据进行计算,再将计算结果写入 HDFS。
MapReduce、Hive、Spark 等进行的计算处理被称作是离线计算,HDFS 存储的数据被称为离线数据。在大数据系统上进行
的离线计算通常针对(某一方面的)全体数据,比如针对历史上所有订单进行商品的关联性挖掘,这时候数据规模非常大,需
要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,但是要求处理的时间却比较短。比如淘宝要统计每秒产生的订单数,以便
进行监控和宣传。这种场景被称为大数据流式计算,通常用 Storm、Spark Steaming 等流式大数据引擎来完成,可以在秒级
甚至毫秒级时间内完成计算。
下载后可阅读完整内容,剩余3页未读,立即下载
2022-02-22 上传
2022-12-14 上传
2023-06-07 上传
点击了解资源详情
2023-07-13 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38551205
- 粉丝: 3
- 资源: 894
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
