在线广告最优策略:周期预算下的多臂强盗问题与乐观稳健学习算法
需积分: 5 15 浏览量
更新于2024-07-09
收藏 1.26MB PDF 举报
"这篇研究论文探讨了如何在具有定期预算的在线广告环境中制定最佳广告组合策略。通过将问题转化为多臂强盗(Multi-Armed Bandits,MAB)问题,作者提出了一种乐观稳健学习(ORL)算法,旨在最大化广告商的预期总收入,同时确保拍卖支出不超过预算。"
在线广告市场是一个快速变化且竞争激烈的领域,广告商必须精确地定位目标受众,并在实时拍卖中明智地竞标。这种拍卖机制要求广告商在众多可能的目标中选择出价,以期望获得最高的回报。文章中提到的问题核心在于如何在有限的预算内制定广告投放策略,确保每一轮(即每个时间周期)都能选择最优的广告目标组合。
多臂强盗问题是一种经典的探索与利用的决策问题,通常用于描述在不确定环境中通过试错学习最佳选择。在这个背景下,每个“手臂”代表一种可能的广告目标或组合,每次“拉臂”(选择一个目标)都会带来不同的收益(点击或转化带来的收入)。由于预算的周期性,广告商需要在每个时间周期开始时决定投资哪个组合,以期望在整个预算周期内获得最大收益。
为了解决这个问题,研究人员开发了ORL算法,它结合了上置信界(UCB)算法和稳健优化的思想。UCB算法在多臂强盗问题中常用来平衡探索和利用,通过估计每个手臂的潜在价值,鼓励尝试那些可能高回报但尚未充分测试的目标。而稳健优化则考虑了不确定性,确保即使在面对数据噪声或模型不准确时,算法也能做出相对稳定的决策。
论文证明了ORL算法的预期累积后悔(衡量实际收益与最佳可能收益之间的差距)是有界的,这意味着即使在未知环境中,算法也能保证一定的性能。此外,通过模拟实验,ORL算法在合成数据和真实世界数据上相比于基准方法,至少减少了10-20%的遗憾,显示出其在实际应用中的优越性。
这篇研究为在线广告领域的策略制定提供了一个新颖且有效的工具,有助于广告商在复杂和动态的市场环境中更好地管理他们的广告预算,实现更高的投资回报率。通过采用ORL算法,广告商可以更智能地选择目标组合,提高广告效率,从而在竞争激烈的在线广告市场中脱颖而出。
Baardman, Fata, Pani, and Perakis: Learning Optimal Online Advertising Portfolios with Periodic Budgets
8
the to-be realized costs are unknown. Hence, the selected set of arms might in fact be infeasible to
pull. We use techniques from the robust optimization literature to bound the probability that the
realized cost of the chosen arms violates the budget constraint. Similar probabilistic guarantees
on the feasibility of a solution to a robust optimization problem can be found in Bertsimas et al.
(2004). The interested reader is referred to Bertsimas and Sim (2004), Bertsimas et al. (2011),
Gabrel et al. (2014) for an overview on robust optimization.
2. Online Advertising Process
In this section, we describe the process by which online advertising platforms function. The process
is visualized in Figures 1 and 2 in two steps: Figure 1 describes the problem of selecting a portfolio
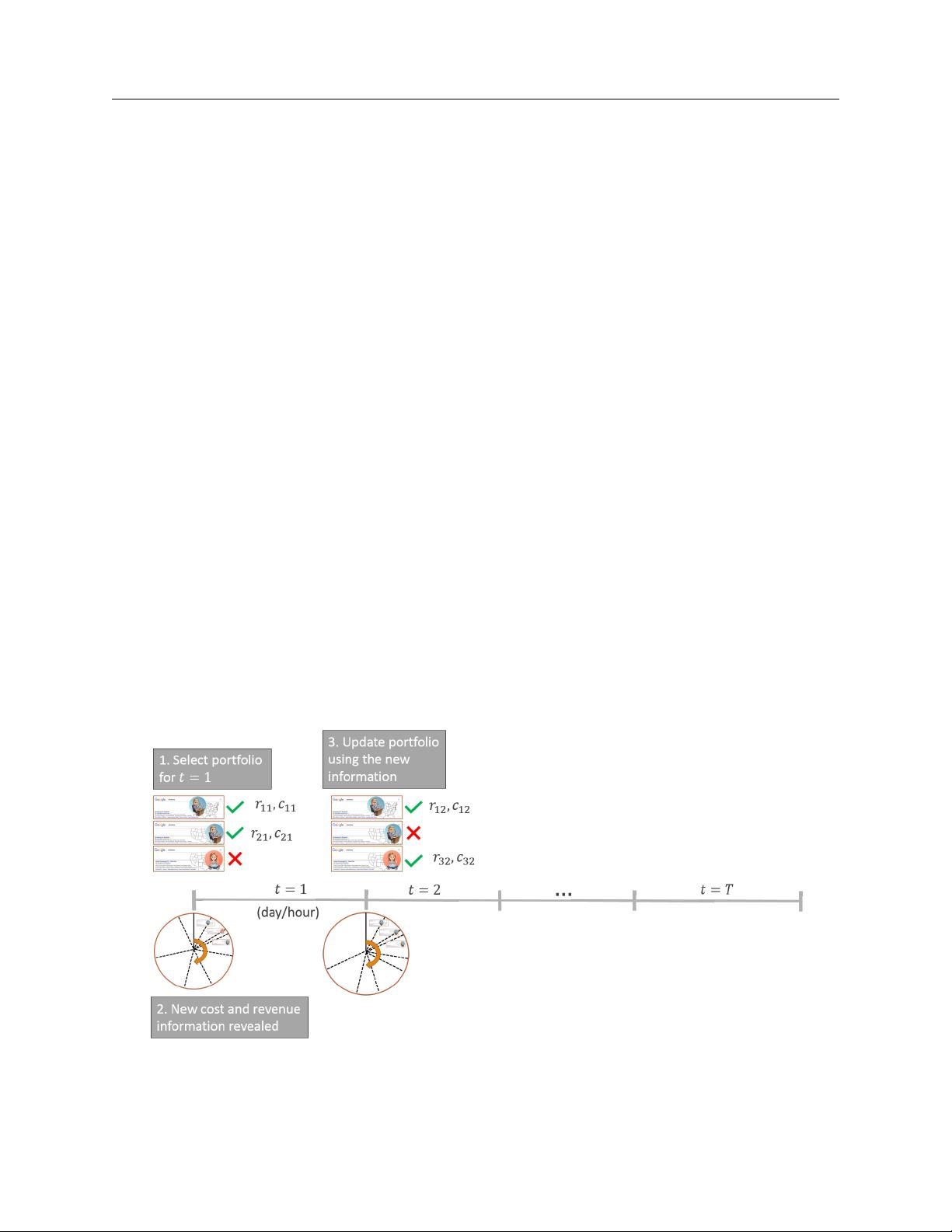
of targets given estimates of the revenue and cost (offline decision-making) and Figure 2 describes
how the new revenue and cost data is used to update their estimates (online learning).
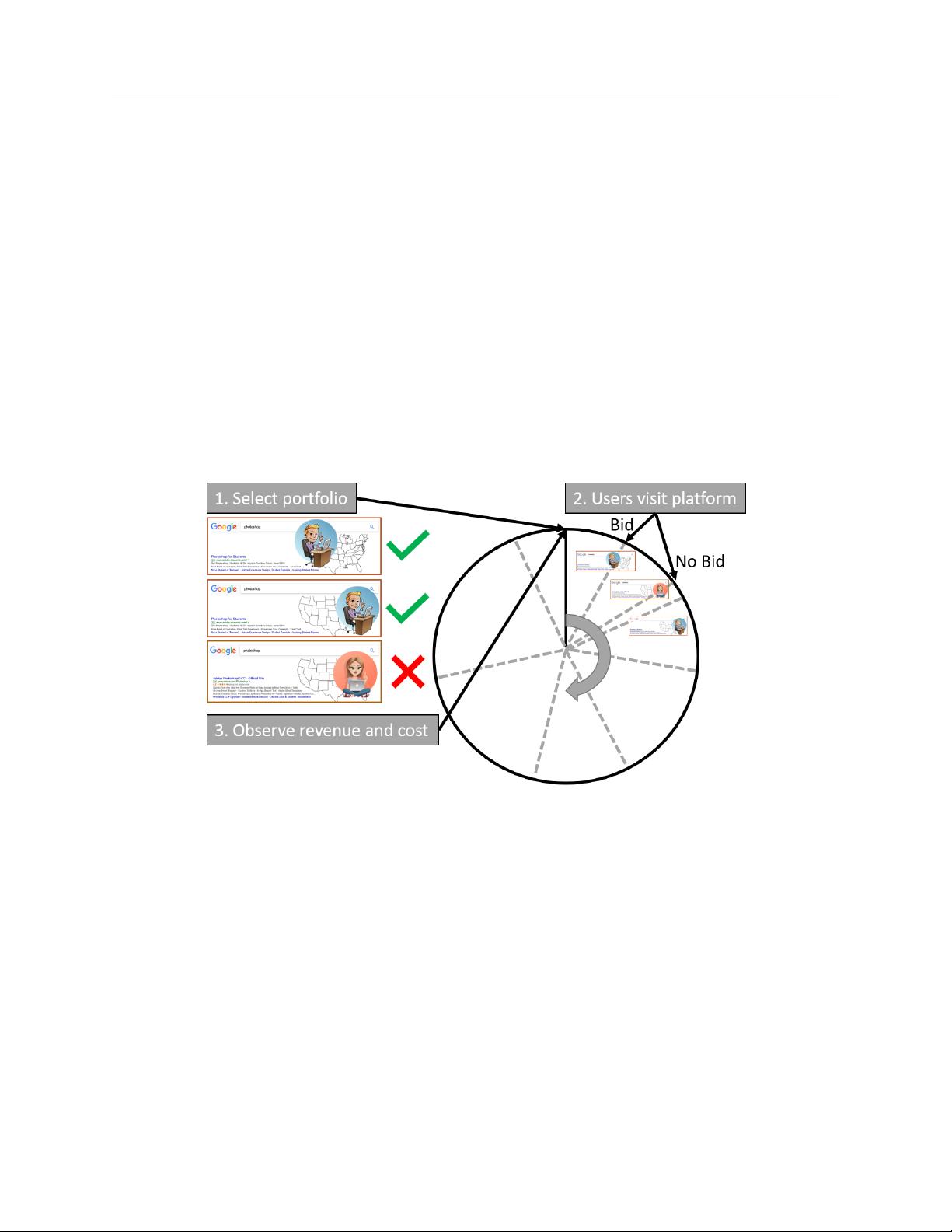
Figure 1 Process of online advertising portfolio optimization on an advertising platform during one time period:
a portfolio of targets is selected at the beginning of the period, bids are placed on selected targets if
they appear during the period, and the resulting revenue and cost are observed at the end of the period.
In Figure 1, the clock represents a period, which is often an hour or a day long. At the beginning
of the period, the advertiser decides on a portfolio of targets to bid on and communicates these
to the platform. During the period, users visit the platform and if a visiting user is among the
targets in the portfolio, the platform will place a bid for the advertiser. Inherently, the revenue
and cost from each user is random to the advertiser, and hence, the period’s revenue and cost
for each target is random as well. The period’s revenue of a target depends on the number of
visiting users, whether the auctions are won, whether the customers click the ad, and whether the
customers purchase the item. The period’s cost of a target depends on the number of visiting users,
Electronic copy available at: https://ssrn.com/abstract=3346642
剩余40页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-08 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38677472
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高效便捷的屏幕捕捉小工具介绍与使用
- QT多线程源码解析:主窗口子线程启动与暂停机制
- 利用CVPR 2020论文实现高效盲图像降噪
- EPSON L101/L100清零软件及图解使用指南
- zDialog弹出框插件:用户体验升级,兼容性广,轻量设计
- VBA代码封装成可执行EXE文件的实现方法
- jQuery图片剪裁插件jquery.cropit.js深入解析
- ProE液压泵变量活塞零件工装设计全套资料
- 深入浅出嵌入式系统设计基础教程
- 电子商务技术新发展:从压缩包子文件谈起
- 镜面旋转模拟:体验OPPO Finder旋转解锁效果
- C++实现屏幕截图功能的源码解析
- PHP实现多图九宫格合并教程与实例代码
- 钢板弹簧吊耳设计:工艺、工装及机械毕业论文指导
- C#彩票选号器源码发布:二维码与条形码功能
- 在Visual studio 2008中实践读者写者操作系统练习











