Cascading2.1用户指南:Hadoop数据处理详解
需积分: 1 47 浏览量
更新于2024-07-27
收藏 437KB PDF 举报
"Cascading用户指南"
Cascading是一个用于构建大数据处理应用程序的开源Java库,它在Apache Hadoop上运行。本用户指南是针对Cascading 2.1版本的详细文档,由Concurrent, Inc.出版,适用于2012年9月发布。
1. 关于Cascading
Cascading是一个数据处理框架,它提供了一种抽象层,使得开发者能够在Hadoop上创建复杂的数据工作流,而无需深入理解Hadoop的底层细节。Cascading的设计目标是提高开发效率、可读性和可维护性,同时保持灵活性和高性能。
1.1 什么是Cascading?
Cascading是一个用于构建和执行数据工作流的应用程序接口(API),它允许开发者用Java或Scala编写数据处理逻辑,这些逻辑可以在分布式计算环境中如Hadoop上执行。
1.2 使用场景
Cascading适用于各种数据分析任务,包括数据清洗、转换、聚合、统计分析和机器学习等。它被广泛应用于商业智能、社交媒体分析和科学研究等领域。
1.3 什么是Apache Hadoop?
Apache Hadoop是一个开源框架,用于存储和处理大规模数据集。它采用分布式计算模型,通过HDFS(Hadoop分布式文件系统)进行数据存储,并通过MapReduce进行并行计算。
2. 开始使用
这部分介绍了如何开始使用Cascading,包括安装、配置和编写第一个Cascading应用。
3. 数据处理
3.1 术语
在Cascading中,了解关键术语如Pipe、Assembly、Tap、Scheme和Field Set等对于理解其工作原理至关重要。
3.2 Pipe和Assemblies
Pipe是数据处理的基本单元,它们可以组合成更复杂的Pipe Assemblies,形成一个数据处理流程。常见的操作如Each、Every、Merge、GroupBy、CoGroup和HashJoin等可以用来定义数据处理逻辑。
3.3 平台
Cascading支持多个平台,包括Hadoop,使得用户可以跨不同的分布式计算环境移植代码。
3.4 Source和Sink Taps
Source Tap用于读取数据,Sink Tap用于写入数据。Schemes定义了数据的格式和读写方式。
3.5 Sink模式
Sink模式控制数据如何写入到输出源,例如是否需要重试或者容错机制。
3.6 Field Sets
Field Sets是数据的结构化表示,定义了数据的字段和类型。
3.7 Flows
Flow是工作流的实例,将Pipe Assemblies转换为可执行的任务。可以配置Flow的属性,如跳过某些Flow步骤,或者从JobConf创建自定义Flow。
3.8 Cascades
Cascades是更高层次的工作流构建块,可以包含多个Flow。
4. 在Hadoop上执行进程
这部分详细解释了如何在Hadoop集群上构建、配置和执行Cascading应用程序。
5. 使用和开发Operations
Operations是Cascading中的自定义功能,如Functions、Filter和Aggregator,它们允许开发者扩展Cascading的功能,实现特定的计算需求。
5.1 Functions
Functions是自定义的逻辑操作,可以用于转换或过滤数据。
5.2 Filter
Filter操作用于根据指定条件筛选数据。
5.3 Aggregator
Aggregator用于对数据进行聚合操作,如求和、平均值或计数。
本用户指南全面覆盖了Cascading的核心概念和使用方法,是开发者深入了解和使用Cascading进行大数据处理的重要参考资料。
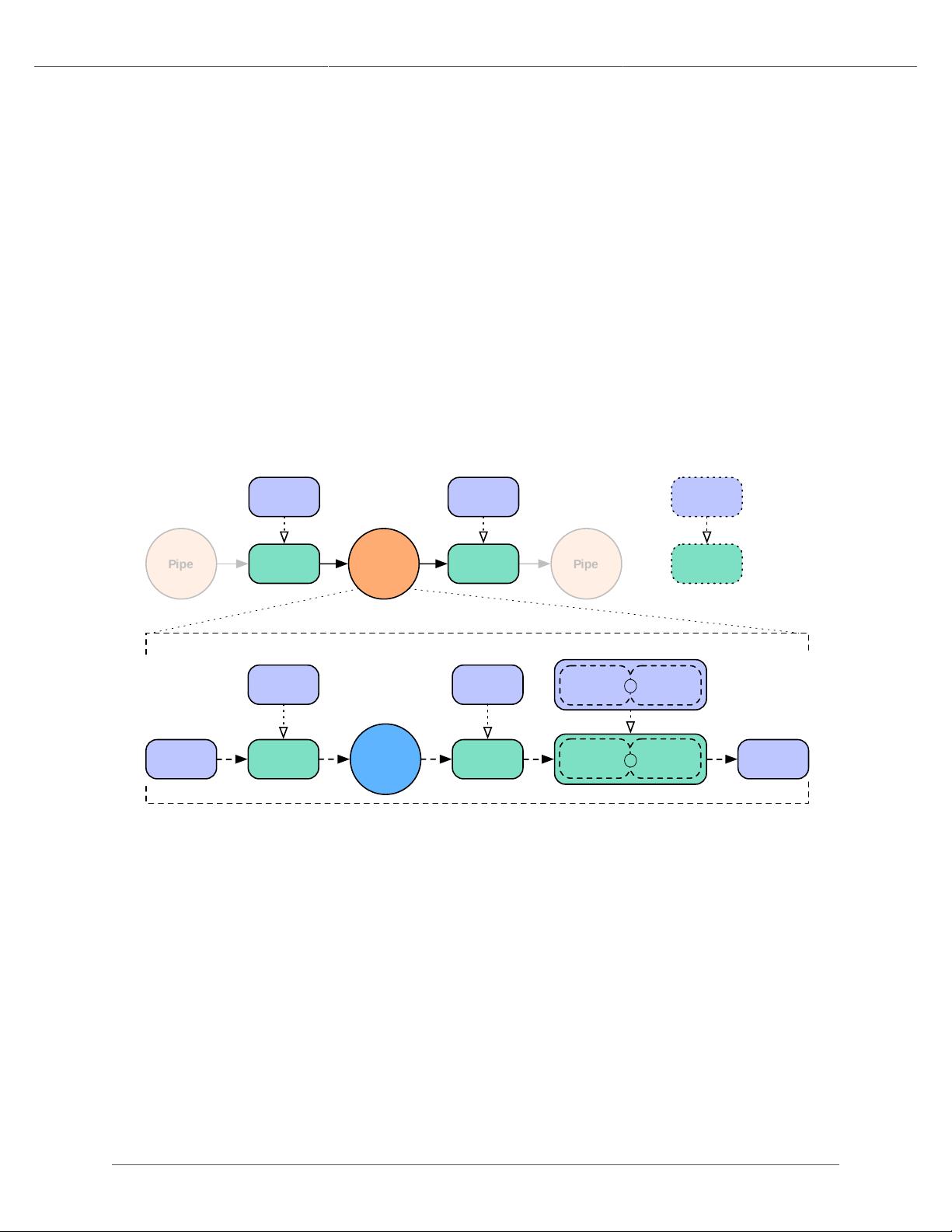
Data Processing
Cascading Cascading 2.1 User Guide 12
• an argument selector
• an Operation instance
• an output selector on the constructor (selectors here are Fields instances)
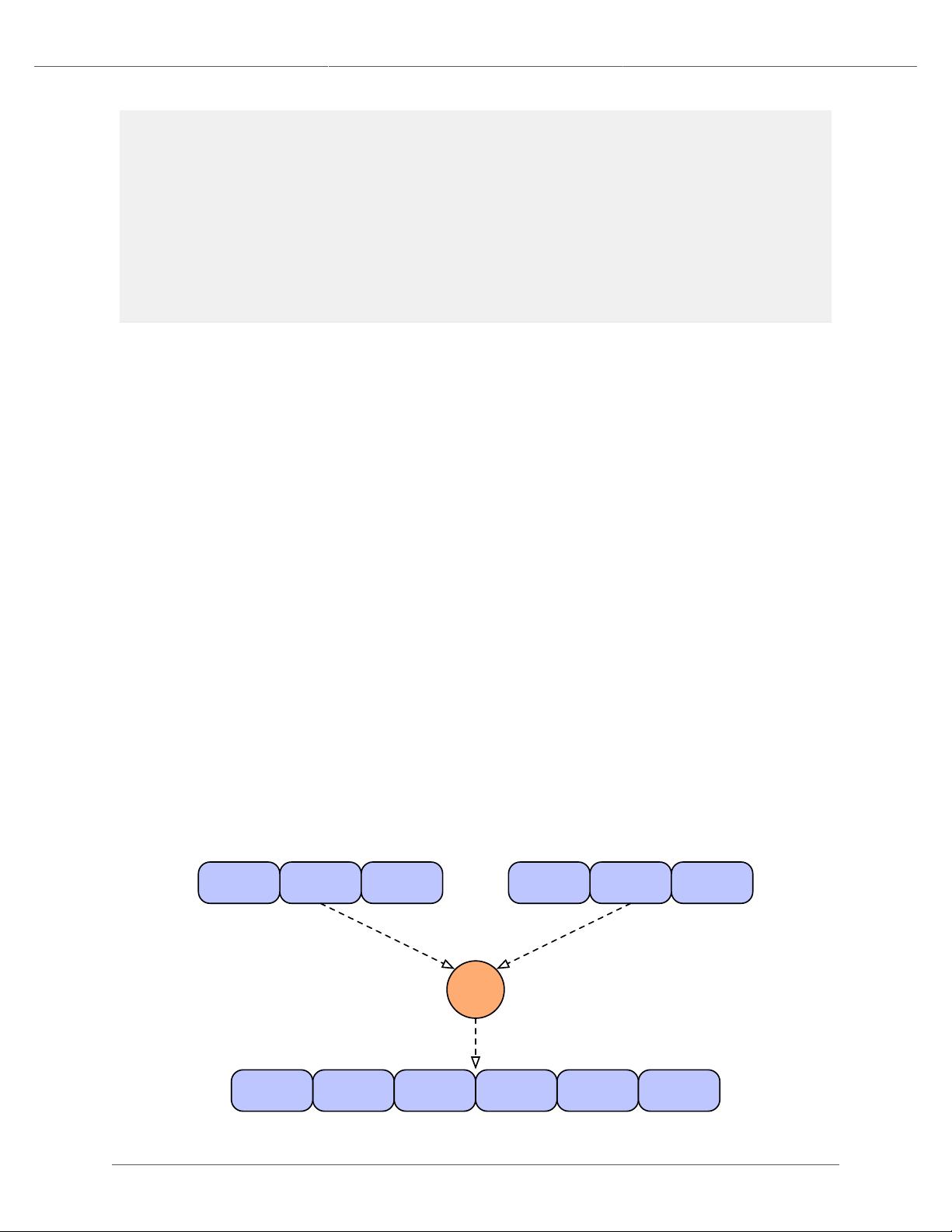
The key difference between Each and Every is that the Each operates on individual tuples, and Every operates
on groups of tuples emitted by GroupBy orCoGroup. This affects the kind of operations that these two pipes can
perform, and the kind of output they produce as a result.
The Each pipe applies operations that are subclasses of Functions and Filters (described in the Javadoc). For
example, using Each you can parse lines from a logfile into their constituent fields, filter out all lines except the HTTP
GET requests, and replace the timestring fields with date fields.
Similarly, since the Every pipe works on tuple groups (the output of a GroupBy or CoGroup pipe), it applies
operations that are subclasses of Aggregators and Buffers. For example, you could use GroupBy to group the
output of the above Each pipe by date, then use an Every pipe to count the GET requests per date. The pipe would
then emit the operation results as the date and count for each group.
Pipe
Operation
argument
Selector
Pipe
output
Selector
result
Tuple
Tuple
Fields
argument
Tuple
declared
Fields
argument
Fields
input
Fields
declared
Fields
+
input
Tuple
result
Tuple
+
input
Fields
output
Fields
Pipe
Pipe
output
Tuple
input
Tuple
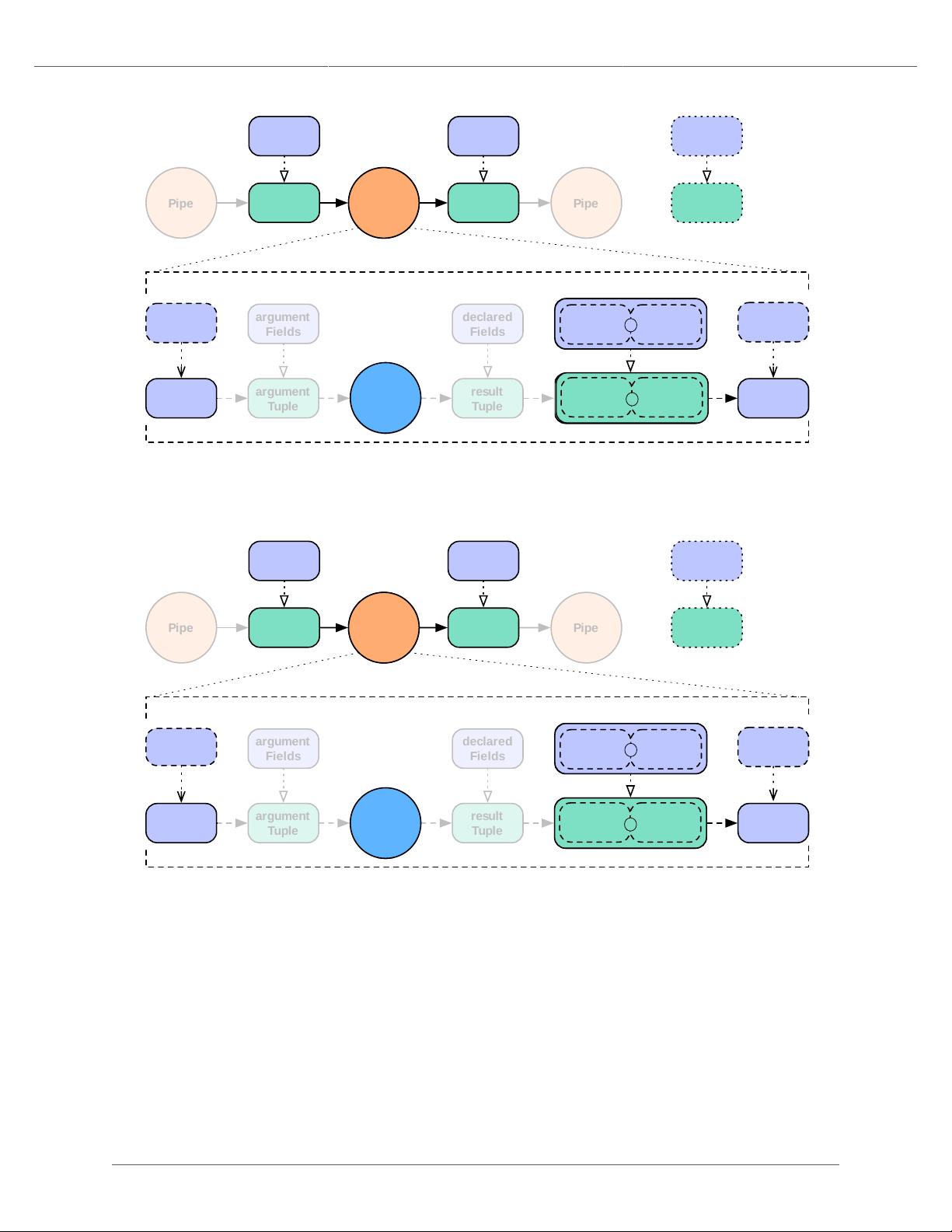
In the syntax shown at the start of this section, the argument selector specifies fields from the input tuple to use as
input values. If the argument selector is not specified, the whole input tuple (Fields.ALL) is passed to the operation
as a set of argument values.
Most Operation subclasses declare result fields (shown as "declared fields" in the diagram). The output selector
specifies the fields of the output Tuple from the fields of the input Tuple and the operation result. This new output
Tuple becomes the input Tuple to the next pipe in the pipe assembly. If the output selector isFields.ALL, the
output is the input Tuple plus the operation result, merged into a singleTuple.
Note that it's possible for a Function or Aggregator to return more than one output Tuple per inputTuple. In
this case, the input tuple is duplicated as many times as necessary to create the necessary output tuples. This is similar
to the reiteration of values that happens during a join. If a function is designed to always emit three result tuples for
every input tuple, each of the three outgoing tuples will consist of the selected input tuple values plus one of the three
sets of function result values.
剩余98页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2011-01-14 上传
2014-07-08 上传
点击了解资源详情
2024-11-21 上传

oTsinghe
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
