基于深度学习的文本分类模型融合方法
需积分: 0 197 浏览量
更新于2024-08-04
收藏 264KB DOCX 举报
2017知乎看山杯参赛方案-ye-61
本文总结了2017知乎看山杯参赛方案ye-61的主要内容,涵盖了实验流程、数据预处理、特征提取、模型训练和模型融合等方面。
1. 实验流程
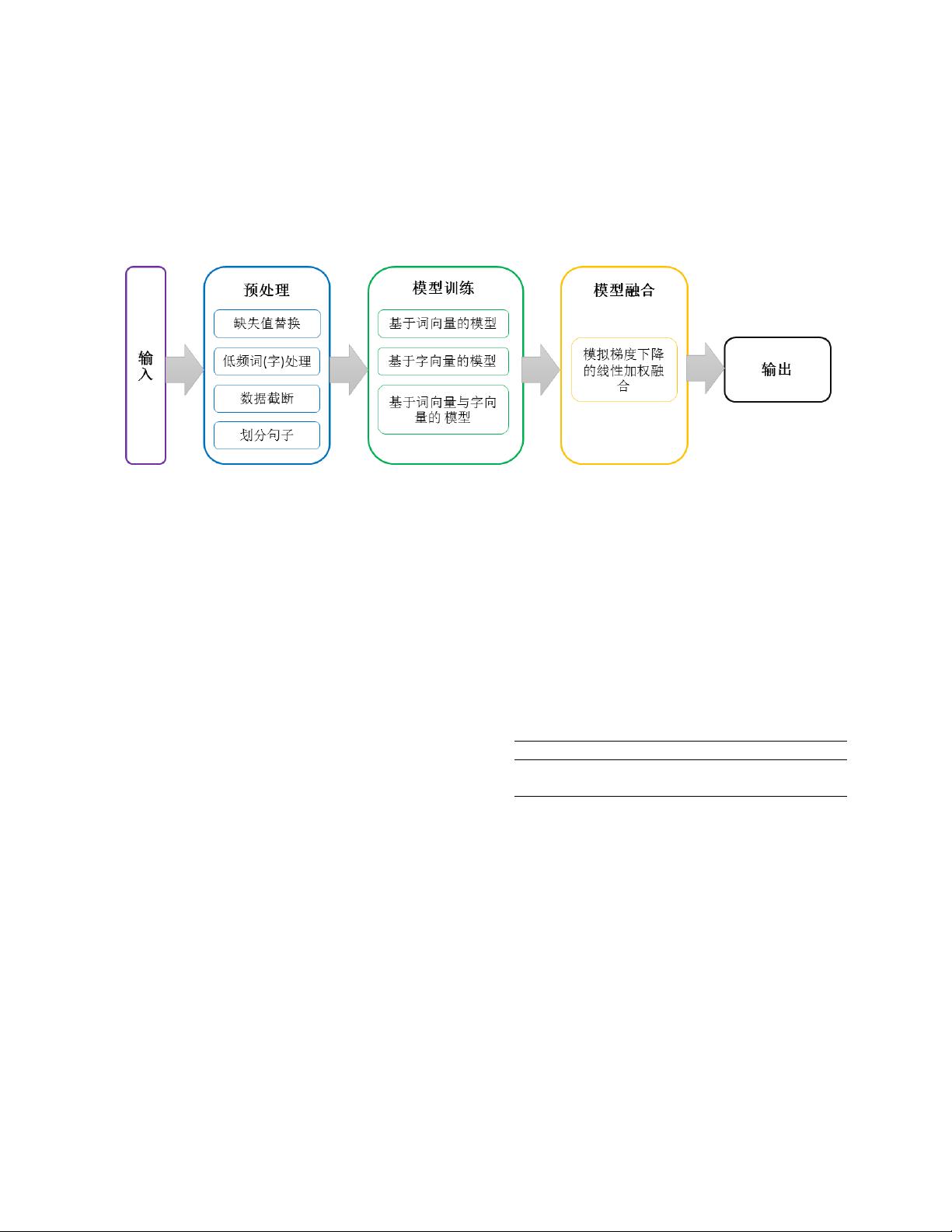
实验流程图1展示了我们方法的主要流程,包括数据预处理、特征提取、模型训练和模型融合四个步骤。在数据预处理中,完成了缺失值处理、低频词(字)处理、数据截断和划分句子等处理。在特征提取中,我们主要利用了赛方提供的词向量和字向量两部分特征。在模型训练部分,根据输入数据的不同,主要训练了三大类型的模型:仅使用词向量的模型、仅使用字向量的模型,同时使用词向量和字向量的模型。在模型融合部分,我们模拟梯度下降的方法进行多个模型的线性加权融合,利用线下验证集的F1值变化来调整各个模型的权重。
2. 数据预处理
数据预处理是整个实验流程的重要一步。在本次比赛中,赛方提供了训练集和测试集两个数据集,其中训练集包含2999967个问题,测试集包含217360个问题。每个问题由问题标题和问题描述两部分组成。在两个数据集中,都有部分问题缺失标题或者缺失描述,因此需要对缺失值进行处理。在测试集中,我们把缺失的标题用该问题的描述进行填充,同理,缺失的描述利用对应问题的标题进行填充。在训练集中,处理方式和对测试集的处理基本相同,只是对于没有标题的15个问题,我们直接丢弃,这样最后用于训练和验证的样本数量为2999952(2999967-15)个。
3. 低频词(字)处理
低频词(字)处理是数据预处理的重要一步。赛方提供了字符级别的256维的embedding向量及词语级别的256维的embedding向量。但是词汇表中省略掉了出现频次为5以下的字符或者词语,因此在训练和验证语料中出现的词汇有可能没有对应的word embedding向量。对于没有出现在词汇表中的词或字,我们统一给定一个随机初始化的向量来表示。
4. 模型训练
模型训练是整个实验流程的核心部分。在本次比赛中,我们主要训练了三大类型的模型:仅使用词向量的模型、仅使用字向量的模型,同时使用词向量和字向量的模型。我们使用深度学习的方法,以文本分类中比较经典的双端GRU模型和TextCNN等模型为基础,构造多个新的模型进行分类。
5. 模型融合
模型融合是整个实验流程的最后一步。在本次比赛中,我们模拟梯度下降的方法进行多个模型的线性加权融合,利用线下验证集的F1值变化来调整各个模型的权重。通过本方法,本组最终在Public排行榜上得分为0.43296,排名第五;在最终得分榜上得分0.43060,排名第六。
关键词:知乎看山杯,文本分类,深度学习,模型融合
2017 知乎看山杯 ye 组参赛方案说明
黄永业
北京邮电大学
yongye@bupt.edu.cn
图 1. 方法流程图
摘要
在本次比赛中,知乎给出了问题与话题标签的绑定关系的训
练数据,通过这些数据训练出能够对未标注的数据自动标注
的模型。我们组主要利用深度学习的方法,以文本分类中比
较经典的双端 GRU 模型和 TextCNN 等模型为基础,构造多个
新的模型进行分类。然后模拟梯度下降的方法对多个模型进
行线性加权融合,得到最优的结果。通过本方法,本组最终
在 Public 排行榜上得分为 0.43296,排名第五;在最终得分
榜上得分 0.43060,排名第六。
关键词
知乎看山杯,文本分类,深度学习,模型融合
1 概述
我们的方法主要包括下面四个步骤:数据预处理,特征提取,
模型训练和模型融合。
在数据预处理中,完成了缺失值处理、低频词(字)处理、
数据截断和划分句子等处理。在特征提取中,我们主要是利
用了赛方提供的词向量和字向量两部分特征,没有引入更多
的特征。在模型训练部分,根据输入数据的不同,主要训练
了三大类型的模型:仅使用词向量的模型,仅使用字向量的
模型,同时使用词向量和字向量的模型。在模型融合部分,
我们模拟梯度下降的方法进行多个模型的线性加权融合,利
用线下验证集的 F1 值变化来调整各个模型的权重。
1.1 实验流程
图 1 展示了我们方法的主要流程。
2 数据预处理
2.1 缺失值处理
赛方提供了训练集和测试集两个数据集,其中训练集包含
2999967 个问题,测试集包含 217360 个问题。每个问题由
问题标题和问题描述两部分组成。在两个数据集中,都有部
分问题缺失标题或者缺失描述,表 1 统计了两个数据集中存
在缺失值的问题数量(基于词进行统计)。
表 1. 缺失数据统计表
数据集
标题缺失
描述缺失
训练集
15
834804
测试集
3
60234
在测试集中,我们把缺失的标题用该问题的描述进行填
充,同理,缺失的描述利用对应问题的标题进行填充。在训
练集中,处理方式和对测试集的处理基本相同,只是对于没
有标题的 15 个问题,我们直接丢弃,这样最后用于训练和验
证的样本数量为 2999952(2999967-15)个。
2.2 低频词(字)处理
赛方提供了字符级别的 256 维的 embedding 向量及词语级别
的 256 维的 embedding 向量。但是词汇表中省略掉了出现频
次为 5 以下的字符或者词语,因此在训练和验证语料中出现
的词汇有可能没有对应的 word embedding 向量。对于没有
出现在词汇表中的词或字,我们统一给定一个随机初始化的
向量来表示。
2.3 数据截断
下载后可阅读完整内容,剩余3页未读,立即下载
371 浏览量
点击了解资源详情
145 浏览量
2022-08-08 上传
380 浏览量
2024-01-15 上传
2024-04-12 上传
125 浏览量

史努比狗狗
- 粉丝: 30
- 资源: 317
 我的内容管理
展开
我的内容管理
展开







最新资源
- Oracle10g系统表视图(高清晰版大图)
- JFFS2文件系统 PDF
- 09年嵌入式系统设计师考试大纲
- 电子书:电子DIY过程详解
- axure rp 原型设计软件教程
- jsp自动设置的若干问题
- 新型高性能开关电源电压型PWM比较器
- UML for Java Programmers中文版
- mpeg4--标准白皮书
- 单相并联型无源_有源混合滤波器的仿真研究
- Spring 开发指南
- 高质量C++编程指南
- Weblogic 8.1中配置JDBC
- 软考信息系统管理工程师考试大纲
- 在 Weblogic 8.1上配置 Hibernate 3.0
- Developing with Google App Engine
