大规模MPI-CUDA并行方法加速无压流计算
需积分: 15 42 浏览量
更新于2024-07-19
收藏 1.13MB PDF 举报
在现代计算机科学中,高性能计算(HPC)和并行计算技术的发展极大地推动了大规模模拟应用的效率。本研究聚焦于将Message Passing Interface (MPI) 和 Compute Unified Device Architecture (CUDA) 结合,以实现并行化在大规模多GPU集群上处理大规模无压缩流体动力学(CFD)模拟的能力。MPI-CUDA的集成是针对当前异构架构的多GPU集群,这种集群拥有深度内存层次结构,对编写可扩展和高效的模拟代码提出了独特挑战。
研究团队在Boise State University的背景下,利用了MPI的高级特性,如数据并行性和通信优化,以及CUDA的并行计算能力,实现了GPU数据传输与MPI通信的同步执行,以提高性能。他们在NCSA Lincoln Tesla集群的64个节点上,利用128个GPU共30,720个处理单元,实现了大约2.4 teraflops(万亿次浮点运算)的计算性能。这表明,通过多GPU集群,可以显著加速CFD模拟的计算速度,尤其是在解决大型复杂问题时,传统CPU集群已无法满足需求,转向混合并行平台成为趋势。
三种策略被探索来评估并优化MPI-CUDA实现的效率和可扩展性:
1. **数据复制优化**:通过智能地管理和复制数据,减少跨GPU和主机之间的数据移动,降低通信开销。
2. **任务并行和流水线调度**:通过精细划分任务并在GPU和CPU之间分配,平衡负载并减少计算阻塞。
3. **通信与计算的协同**:通过使用CUDA streams和MPI的非阻塞I/O,允许数据交换和计算同时进行,提高整体性能。
该研究的成果不仅对于CFD模拟领域具有重要意义,也为其他依赖于大规模并行计算的应用提供了宝贵的实践经验,展示了如何在现代HPC环境中有效地利用GPU资源来提升计算效能。此外,这篇发表在AIAA航天科学会议上的论文还可能启发未来在分布式计算环境下的高性能并行软件开发,特别是在那些对计算速度和规模有严格要求的领域。
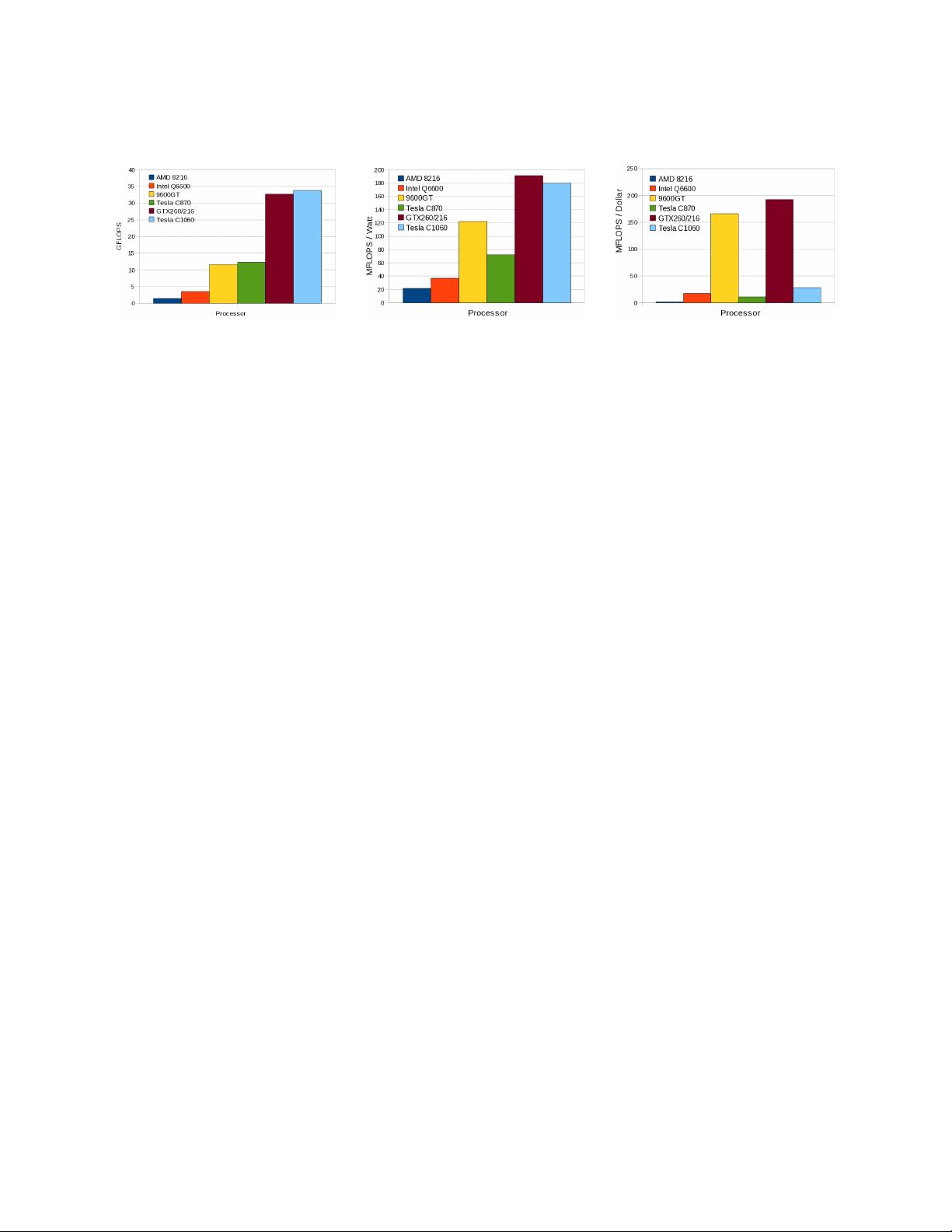
GFLOPS.
a) b) c)
Figure 1. Three performance metrics on six selected CPU and GPU devices based on incompressible flow
computations on a single device. Actual sustained performance is used rather than peak device performance.
a) Sustained GFLOPS, b) MFLOPS/Watt, c) MFLOPS/Dollar
Figure 1a shows three performance metrics on each platform using an incompressible flow CFD code. The GPU
version of the CFD code is clearly an improvement over the Pthreads shared-memory parallel CPU version. Both
of these implementations are written in C and use identical numerical methods
9
. The main impact on individual
GPU performance was the introduction of compute capability 1.3, which greatly reduces the memory latency in some
computing kernels due to the relaxed memory coalescing rules
4
. Compute capability 1.3 also added support for double
precision which is important in many solutions.
Figure 1b shows the performance relative to the peak electrical power of the device. GPU devices show a definite
advantage over the CPUs in terms of energy-efficient computing. The consumer video cards have a slight power
advantage over the Tesla series, partly explained by having significantly less active global memory. The recent paper
by Kindratenko et al.
12
details the measured power use of two clusters built using NVIDIA Tesla S1070 accelerators.
They find significant power usage from intensive global memory accesses, implying CUDA kernels using shared
memory not only can achieve higher performance but can use less power at the same time. Approximately 70%
of the S1070’s peak power is used while running their molecular dynamics program NAMD. Figure 1c shows the
performance relative to the street price of the device which sheds light on the cost effectiveness of GPU computing.
The consumer GPUs are better in this regard, ignoring other factors such as the additional memory present in the
compute server GPUs.
The rationale for clusters of GPU hardware is identical to that for CPU clusters – larger problems can be solved
and total performance increases. Figure 1c indicates that clusters of commodity hardware can offer compelling
price/performance benefits. By spreading the models over a cluster with multiple GPUs in each node, memory size
limitations can be overcome such that inexpensive GPUs become practical for solving large computational problems.
Today’s motherboards can accommodate up to 8 GPUs in a single node
6
, enabling large-scale compute power in
small to medium size clusters. However, the resulting heterogeneous architecture with a deep memory hierarchy cre-
ates challenges in developing scalable and efficient simulation applications. In the following sections, we focus on
maximizing performance on a multi-GPU cluster through a series of mixed MPI-CUDA implementations.
III. Related Work
GPU computing has evolved from hardware rendering pipelines that were not amenable to non-rendering tasks, to
the modern General Purpose Graphics Processing Unit (GPGPU) paradigm. Owens et al.
13
survey the early history
as well as the state of GPGPU computing in 2007. Early work on GPU computing is extensive and used custom
programming to reshape the problem in a way that could be processed by a rendering pipeline, often one without
32-bit floating point support. The advent of DirectX 9 hardware in 2003 with floating point support, combined with
early work on high level language support such as BrookGPU, Cg, and Sh, led to a rapid expansion of the field.
14–19
Brandvik and Pullan
20
show the implementation of 2D and 3D Euler solver on a single GPU, showing 29× speedup
for the 2D solver and 16× speedup for the 3D solver. One unique feature of their paper is the implementation of the
solvers in both BrookGPU and CUDA. Elsen et al.
21
show the conversion of a subset of an existing Navier-Stokes
3
American Institute of Aeronautics and Astronautics
剩余16页未读,继续阅读
2012-07-24 上传
2011-10-24 上传
2021-08-11 上传
2021-06-07 上传
2021-04-30 上传
2021-04-22 上传
2021-03-11 上传

maxfist
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
