"基于MapReduce的K-Means并行算法及应用实例"
 已收录资源合集
已收录资源合集
需积分: 0 80 浏览量
更新于2023-12-27
收藏 3.09MB PDF 举报
本文论述了数据挖掘中的基础算法K-Means聚类算法及其在MapReduce并行计算中的应用。首先介绍了K-Means聚类算法的原理和特点,包括其基本的工作流程和算法思想。随后详细阐述了基于MapReduce的K-Means并行算法的设计思路和实现方法,分析了其并行计算的优势和应用场景。接着给出了实验结果和对算法的评估,总结了该并行算法的性能和效果。最后给出了K-Means聚类算法在实际应用中的示例,并探讨了数据挖掘并行算法研究的重要性,以及基于MapReduce的分类算法和频繁项集挖掘算法的相关内容。在文章结尾,特别感谢Google (北京)与Intel公司中国大学合作部精品课程计划的资助。
数据挖掘是一种通过对大规模数据集进行分析,寻找其中隐藏信息和事实的过程。其中,K-Means聚类算法是数据挖掘中的基础算法之一。它通过将数据分成不同的簇,每个簇包含距离最近的数据点,从而实现对数据的聚类。而在海量数据的情况下,传统的K-Means算法往往面临着计算速度慢、内存占用大等问题。因此,基于MapReduce的并行算法设计成为了一种重要的解决途径。
本文主要围绕K-Means聚类算法在MapReduce并行计算中的应用展开,首先介绍了海量数据对于数据挖掘的重要性和挑战,阐述了并行计算在大规模数据处理中的重要作用。然后,对K-Means聚类算法的原理和特点进行了详细的介绍,包括算法流程、收敛条件和局限性等方面。在此基础上,结合MapReduce的特点,提出了基于MapReduce的K-Means并行算法的设计思路和实现方法,重点分析了其在并行计算中的优势和适用性。通过对实验结果的分析和总结,验证了基于MapReduce的K-Means并行算法在大规模数据处理中的可行性和效果。
此外,文章还给出了K-Means聚类算法在实际应用中的示例,探讨了数据挖掘并行算法的研究意义和发展方向。特别是基于MapReduce的分类算法和频繁项集挖掘算法,为读者提供了更为全面的数据挖掘知识体系。最后,特别感谢Google (北京)与Intel公司中国大学合作部精品课程计划的资助,为本文的顺利完成提供了重要支持。
综上所述,本文不仅系统地介绍了K-Means聚类算法以及基于MapReduce的并行算法设计,还结合了实际应用和实验结果进行了深入分析,为读者提供了一份全面、具体的数据挖掘技术文献。同时也展现了数据挖掘并行算法研究的重要性和发展前景,为相关领域的研究者和从业人员提供了有益的参考和启发。
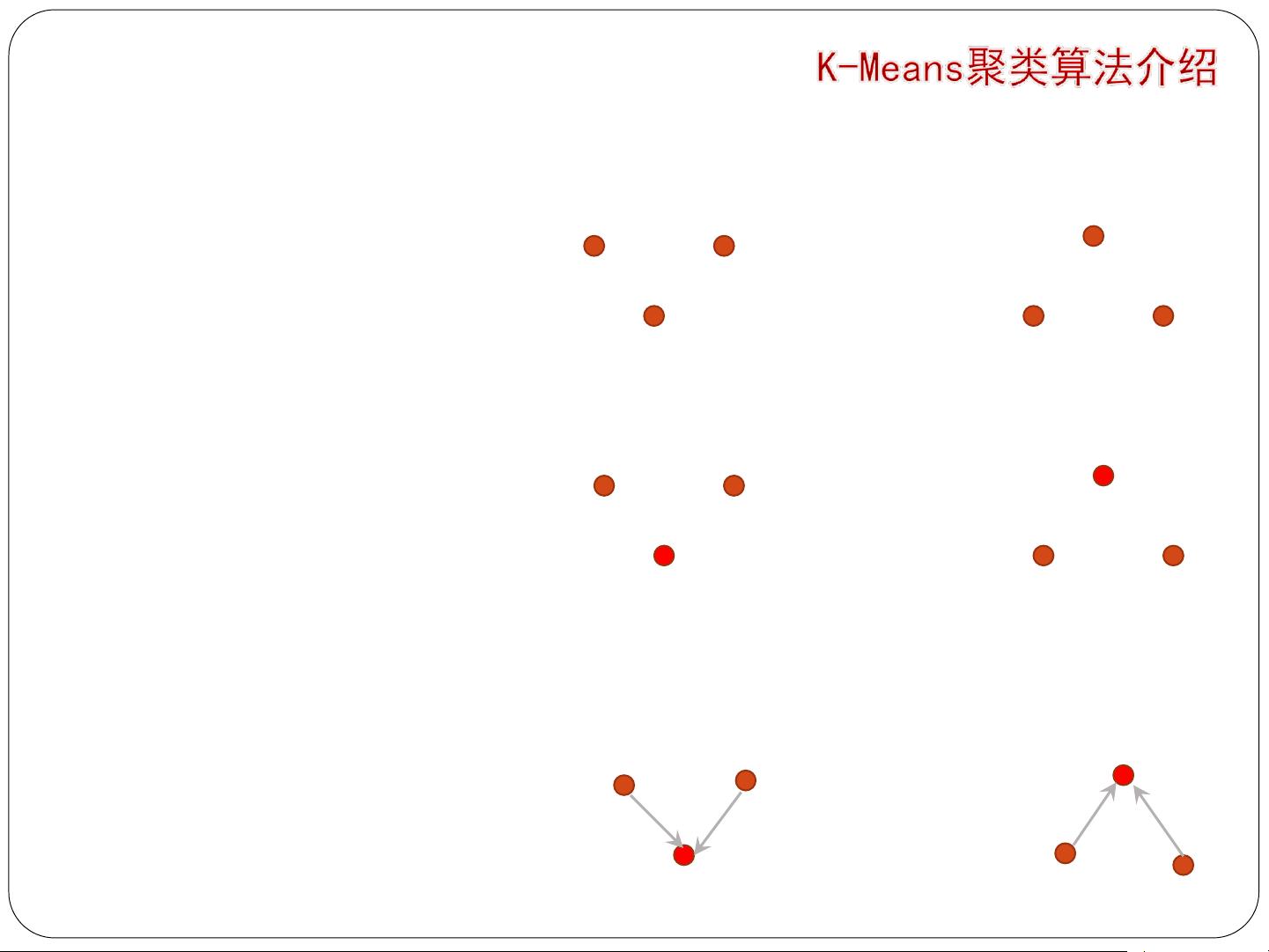
初始数据
K = 2
选择初始中心
-----------------------------------------------
-----------------------------------------------
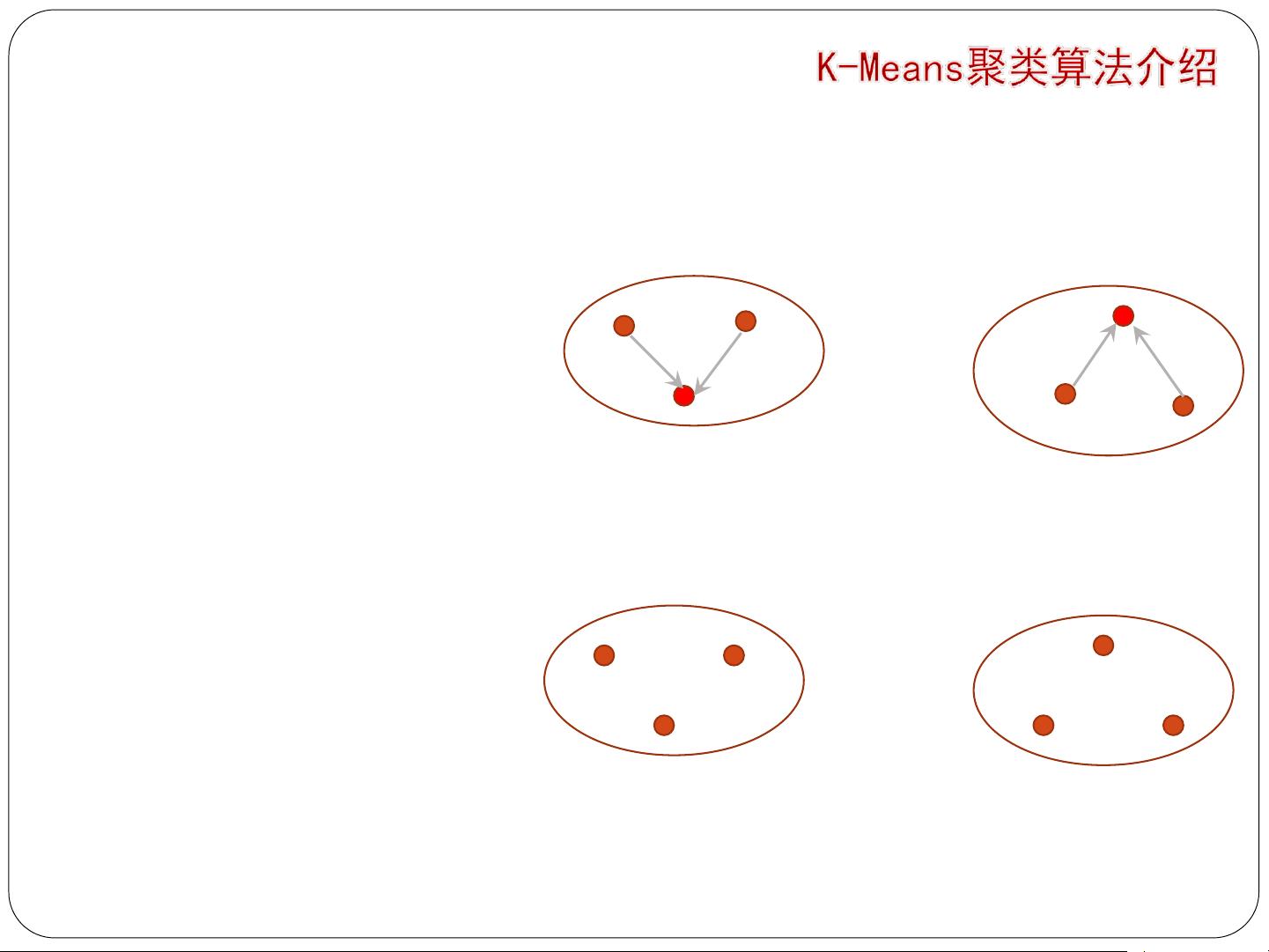
第1次聚类:计算距离
+
+
过程示例


剩余80页未读,继续阅读
2021-10-06 上传
2019-01-15 上传
2021-10-06 上传
1041 浏览量
2023-05-28 上传
2023-07-16 上传
422 浏览量
2023-06-12 上传
932 浏览量
2023-06-07 上传

杜拉拉到杜拉拉
- 粉丝: 26
- 资源: 325
 我的内容管理
展开
我的内容管理
展开







最新资源
- C/C++灵巧指针与内存回收
- 电力电子 MATLAB
- Linux学习笔记(主要是命令)
- mysql的使用和开发教程
- MyEclipse 6 Java 开发中文教程
- VB[1].NET的MP3播放器的论文
- the knowlege of the basic computer network
- 24c02中文官方资料手册pdf[1].pdf
- J2MEAPI Nokia手机界面API函数
- java学习入门资料(学习大纲)
- Ajax4jsf白皮书
- 差分方程及差分方法相关知识
- ----===============gyggvgj
- 游戏编程指南 C++
- Atmel DOC8199芯片资料
- Atmel DOC8200资料
