Hadoop Server的线程模型与Listener机制解析
142 浏览量
更新于2024-08-29
收藏 305KB PDF 举报
"Hadoop的Server及其线程模型分析"
在Hadoop的服务器架构中,线程模型的设计至关重要,因为它直接影响到服务器的并发处理能力和效率。本文主要探讨了Listener线程和Reader线程的角色以及它们如何协同工作以处理客户端的连接请求。
首先,Listener线程是服务器的核心组件,它的主要任务是监听来自客户端的连接请求。它使用Select模式来处理这些请求,这是一种高效的网络I/O多路复用技术,能够同时监控多个套接字的事件。当有新的连接请求到达时,Listener线程会被唤醒并调用doAccept方法处理这些事件。值得注意的是,Listener线程在select操作时可能会被阻塞,这允许其他线程有机会执行,从而确保系统的并发性。
Listener线程还维护了一个空闲连接处理例程,通过计时器检查并关闭过期的空闲连接,以避免资源浪费。这一机制有助于保持服务器的高效运行,及时释放不再使用的资源。
在连接建立后,Listener线程会将新连接设置为非阻塞模式,这是出于性能优化的考虑。非阻塞模式使得Reader和Responder线程在读取和发送数据时不会因等待I/O操作完成而阻塞,减少了线程上下文切换的频率,从而提高了CPU利用率。
接下来,新建立的连接会被分配给Reader线程。服务器通常会配置多个Reader线程以提高并发处理能力。Reader线程会从一个名为pendingConnections的缓冲队列中获取连接,然后注册READ事件并采用select模式等待数据接收通知。当数据可用时,Reader线程会尽可能多地读取数据,避免Listener线程因缺乏执行机会而陷入饥饿状态,从而保持服务器的并发性能。
Reader线程使用LinkedBlockingQueue的take方法从队列中获取连接,这可能导致线程在队列为空时阻塞,但这种阻塞设计是为了确保系统在没有数据可处理时能有效地平衡资源,防止过度消耗。
Hadoop的Server线程模型巧妙地利用了多线程和非阻塞I/O策略,实现了高效且高并发的客户端连接处理。Listener线程的监听和连接管理,以及Reader线程的数据接收,共同构建了一个能够应对大规模并发连接的服务器架构。这种设计对于大数据处理环境下的Hadoop服务来说,至关重要,因为它能够保证服务的稳定性和高性能。
Hadoop的的Server及其线程模型分析及其线程模型分析
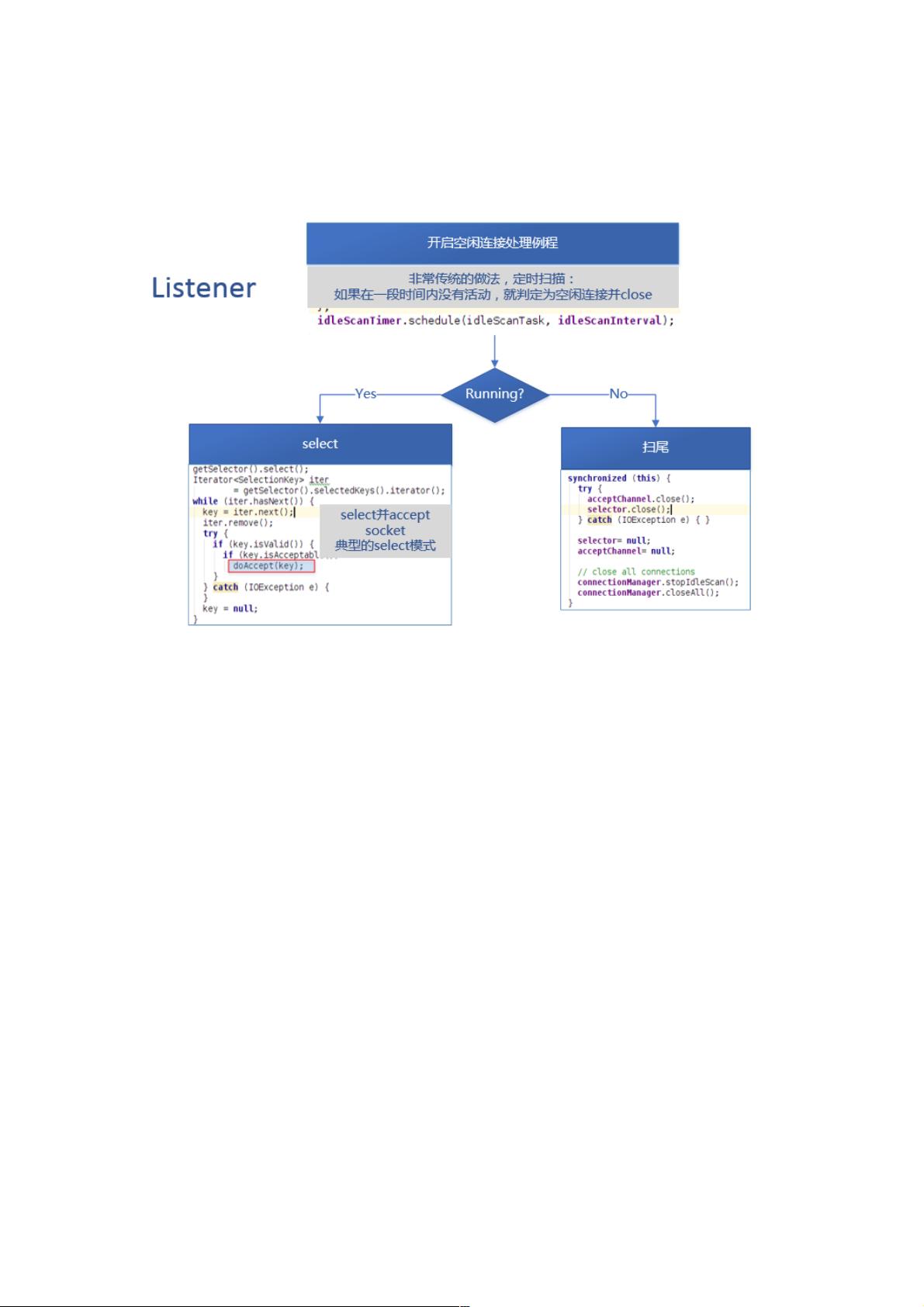
一、Listener
Listener线程,当Server处于运行状态时,其负责监听来自客户端的连接,并使用Select模式处理Accept事件。
同时,它开启了一个空闲连接(Idle Connection)处理例程,如果有过期的空闲连接,就关闭。这个例程通过一个计时器来实
现。
当select操作调用时,它可能会阻塞,这给了其它线程执行的机会。当有accept事件发生,它就会被唤醒以处理全部的事件,
处理事件是进行一个doAccept的调用。
doAccept:
由于多个连接可能同时发起申请,所以这里采用了while循环处理。
这里最关键的是设置了新建立的socket为非阻塞,这一点是基于性能的考虑,非阻塞的方式尽可能的读取socket接收缓冲区中
的数据,这一点保证了将来会调用这个socket进行接收的Reader和进行发送的Responder线程不会因为发送和接收而阻塞,如
果整个通讯过程都比较繁忙,那么Reader和Responder线程的就可以尽量不阻塞在I/O上,这样可以显著减少线程上下文切换
的次数,提高cpu的利用率。
最后,获取了一个Reader,将此连接加入Reader的缓冲队列,同时让连接管理器监视并管理这个连接的生存期。
获取Reader的方式如下:
二、Reader
当一个新建立的连接被加入Reader的缓冲队列pendingConnections之后,Reader也被唤醒,以处理此连接上的数据接收。
Server中配置了多个Reader线程,显然是为了提高并发服务连接的能力。
下面是Reader的主要逻辑:
当Server还在运行时,Reader线程尽可能多地处理缓冲队列中的连接,注册每一个连接的READ事件,采用select模式来获取
连接上有数据接收的通知。当有数据需要接收时,它尽最大可能读取select返回的连接上的数据,以防止Listener线程因为没
有运行时间而发生饥饿(starving)。
如果Listener线程饥饿,造成的结果是并发能力急剧下降,来自客户端的新连接请求超时或无法建立。
注意在从缓冲队列中获取连接时,Reader可能会发生阻塞,因为它采用了LinkedBlockingQueue类中的take方法,这个方法在
队列为空时会阻塞,这样Reader线程得以阻塞,以给其它线程执行的时间。
Reader线程的唤醒时机有两个:
Listener建立了新连接,并将此连接加入1个Reader的缓冲队列;
下载后可阅读完整内容,剩余3页未读,立即下载
2013-03-09 上传
点击了解资源详情
2012-03-17 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38687199
- 粉丝: 4
- 资源: 924
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
