Hive技术文档:配置与授权指南
需积分: 0 112 浏览量
更新于2024-06-30
收藏 1.52MB PDF 举报
"Hive使用手册1 - 2015年夏版本"
Apache Hive 是一个数据仓库工具,它允许用户使用SQL-like的语言HiveQL来查询、管理和处理存储在分布式存储系统(如Hadoop HDFS)中的大规模数据集。Hive由Facebook开发并开源,它将SQL查询转化为MapReduce作业在Hadoop集群上执行。Hive的设计目标是为数据分析提供便捷、可扩展的结构化数据处理能力。
Hadoop基本配置是确保Hive稳定运行的关键。Hive依赖于HDFS、Yarn以及Zookeeper。Yarn负责资源调度,HDFS提供分布式存储,而Zookeeper则用于协调集群服务。Cloudera推荐的配置包括调整Yarn、HDFS的角色并发性和任务资源配置。例如,增加Zookeeper的并发连接数以应对高并发场景,优化HDFS的NameNode和SecondaryNameNode内存,以及提升DataNode的Handler数量以提高处理能力。
Zookeeper的基本配置中,建议增加并发连接数至2000,以防止因默认限制导致的连接失败问题。这有助于提高集群的响应能力和稳定性。
HDFS的配置主要涉及NameNode和DataNode。NameNode的内存应至少调整到4GB,DataNode的Handler数量推荐提升到32或64,以增强处理能力。此外,启用HDFS ACLs可以提供更细粒度的文件访问控制。
Yarn的配置关乎到MapReduce作业的执行效率。推荐增加MapContainer和ReduceContainer的内存使用量,分别从1GB提升到2GB和4GB,以适应大数据处理的需求。同时,调整相应的Java堆栈大小以避免内存不足的问题。对于Map/Reduce任务的内存缓冲区大小,也需要适当调整以优化排序性能。
除了这些基础配置,Hive手册还涵盖了高级主题,如Yarn的调度算法,可能涉及到公平调度器或容量调度器,它们决定了资源如何在不同的应用程序间分配。Yarn的动态资源池允许资源分配随着工作负载的变化而自动调整。Sentry授权机制则提供了细粒度的安全控制,Sentry授权模型和实例说明了如何实施权限管理。Kerberos认证用于提供身份验证,而LDAP认证则允许集成企业级的目录服务,增强系统的安全性。最后,Hive与Impala的互操作性使得不同工具之间可以无缝协作,共享数据和查询结果。
Hive使用手册1提供了全面的配置指导和关键知识点,帮助用户理解并优化Hive在Hadoop生态系统中的工作方式,以实现高效的数据处理和分析。
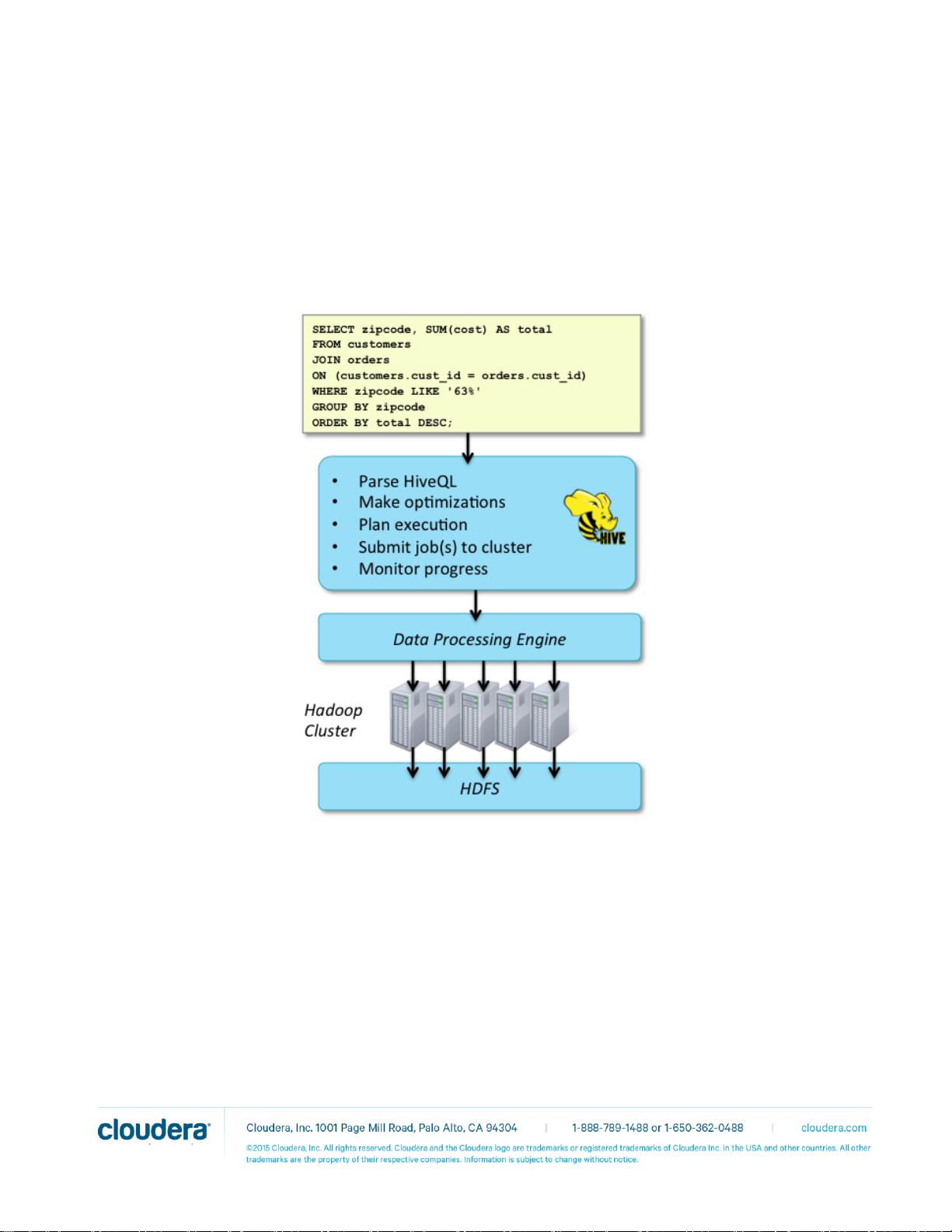
Hive 基本概念
Apache Hive 在 MapReduce 上提供了一个 SQL 引擎层,是 Facebook 开发并开源的一个 Apache 项
目。Apache Hive 支持 HiveQL 语言,是 SQL-92 的一个子集。Hive 只是提供了一个 SQL 的解析,
具体的执行依赖于底层的执行引擎,比如 MapReduce。Hive 将 HiveQL 查询转换为一系列的
MapReduce 作业,提交到集群中运行,如下图所示:
Hadoop 基本配置
Hive 依赖的组件包括 Yarn、HDFS 与 Zookeeper。为了 Hive 的正常工作,Cloudera 对相关组件有
一些推荐配置,主要包括角色并发性、任务资源配置等。
剩余17页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-14 上传
2019-04-01 上传
2019-04-07 上传
2021-10-04 上传

开眼旅行精选
- 粉丝: 19
- 资源: 327
 我的内容管理
展开
我的内容管理
展开







