Python爬取动态加载数据实战教程:实例解析与代码实现
版权申诉
在Python中实现爬取网页中的动态加载数据是一项常见的任务,特别是在数据抓取和分析领域。动态加载的数据通常是指那些在页面首次加载时并未显示,而是通过JavaScript或其他后端技术在用户交互或页面刷新后加载的数据。这类数据对于静态爬虫(仅依赖HTTP响应)来说是不可见的,因为它们并不包含在最初的HTML文档中。
1. **理解动态加载数据**:
- 动态加载的数据是通过额外的网络请求(如AJAX、API调用)获取的,而不是直接从HTML源代码中。这种数据可能隐藏在服务器端,只有在用户的操作触发特定事件时才会发送请求获取。
2. **检测动态加载**:
- 使用浏览器的开发者工具(如Chrome的F12或Firefox的Web Developer Tools)可以帮助识别动态加载。检查请求列表中的网络请求,如果某个请求返回的数据与你期望的动态数据匹配,则说明数据是动态加载的。
3. **获取动态数据的方法**:
- 首先,通过开发者工具定位到动态请求,观察其请求URL和参数。然后,使用Python的requests库发送相同类型的请求,比如GET或POST,根据具体情况设置相应的请求头和数据。
- 例如,代码片段展示了如何使用requests库发送请求并处理返回的JSON数据,通过`json.loads()`函数将服务器返回的JSON字符串转换成Python对象,以便进一步解析商品价格等信息:
```python
import requests
import json
def get_dynamic_data(url, params=None):
response = requests.get(url, params=params)
data = response.json() # 假设数据是JSON格式
product_price = data['product']['price']
return product_price
# 示例用法
url = 'https://example.com/api/products?category=dynamic' # 动态加载数据的API URL
price = get_dynamic_data(url)
print(price)
```
4. **注意事项**:
- 爬虫行为需要遵守网站的robots.txt协议,不要对目标网站造成过大的负载,确保在合法范围内抓取数据。
- 可能需要处理各种异常情况,如请求失败、API认证、反爬虫策略等。
- 随着现代网站的复杂性增加,某些动态加载数据可能会受到同源策略(CORS)的限制,此时可能需要使用代理服务器或修改请求头。
Python爬虫面对动态加载数据时,关键在于理解和模拟浏览器的行为,跟踪并发送正确的请求,解析返回的异构数据。通过深入了解HTTP协议、JavaScript的网络请求以及相关库(如requests和BeautifulSoup)的使用,可以有效地解决这类问题。
Python实现爬取网页中动态加载的数据实现爬取网页中动态加载的数据
主要介绍了Python实现爬取网页中动态加载的数据,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习
学习吧
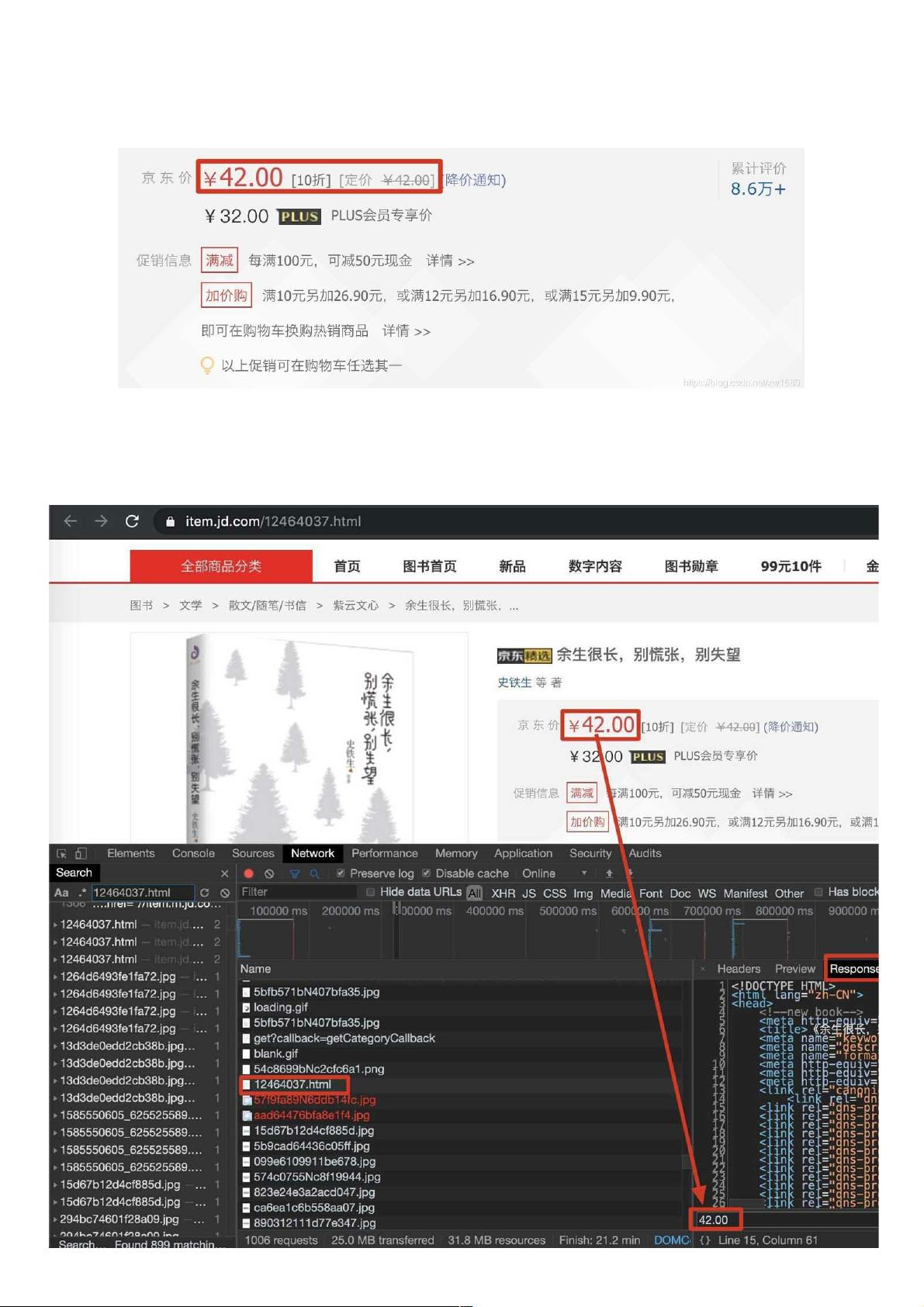
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中,无法抓取动态加载的可用数据。例如,获取某网页中,商品价格时就会出现此类现象。如下图所示。本文将实现爬取网页中类似
的动态加载的数据。
1. 那么什么是动态加载的数据那么什么是动态加载的数据?
我们通过requests模块进行数据爬取无法每次都是可见即可得,有些数据是通过非浏览器地址栏中的url请求得到的。而是通过其他请求请求到的数据,那么这些通过其他请求请求到的数据就是动态加载的数
据。(猜测有可能是js代码当咱们访问此页面时就会发送得get请求,到其他url中获取数据)
2. 如何检测网页中是否存在动态加载得数据如何检测网页中是否存在动态加载得数据?
在当前页面中打开抓包工具,捕获到地址栏中的url对应的数据包,在该数据包的response选项卡搜索我们想要爬取的数据,如果搜索到了结果则表示数据不是动态加载的,否则表示数据为动态加载的。如
图所示:
下载后可阅读完整内容,剩余3页未读,立即下载
2020-09-18 上传
2020-06-12 上传
2023-05-14 上传
2023-10-27 上传
2023-06-12 上传
2023-07-11 上传
2023-09-13 上传
2024-05-16 上传

weixin_38518518
- 粉丝: 6
- 资源: 959
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
