
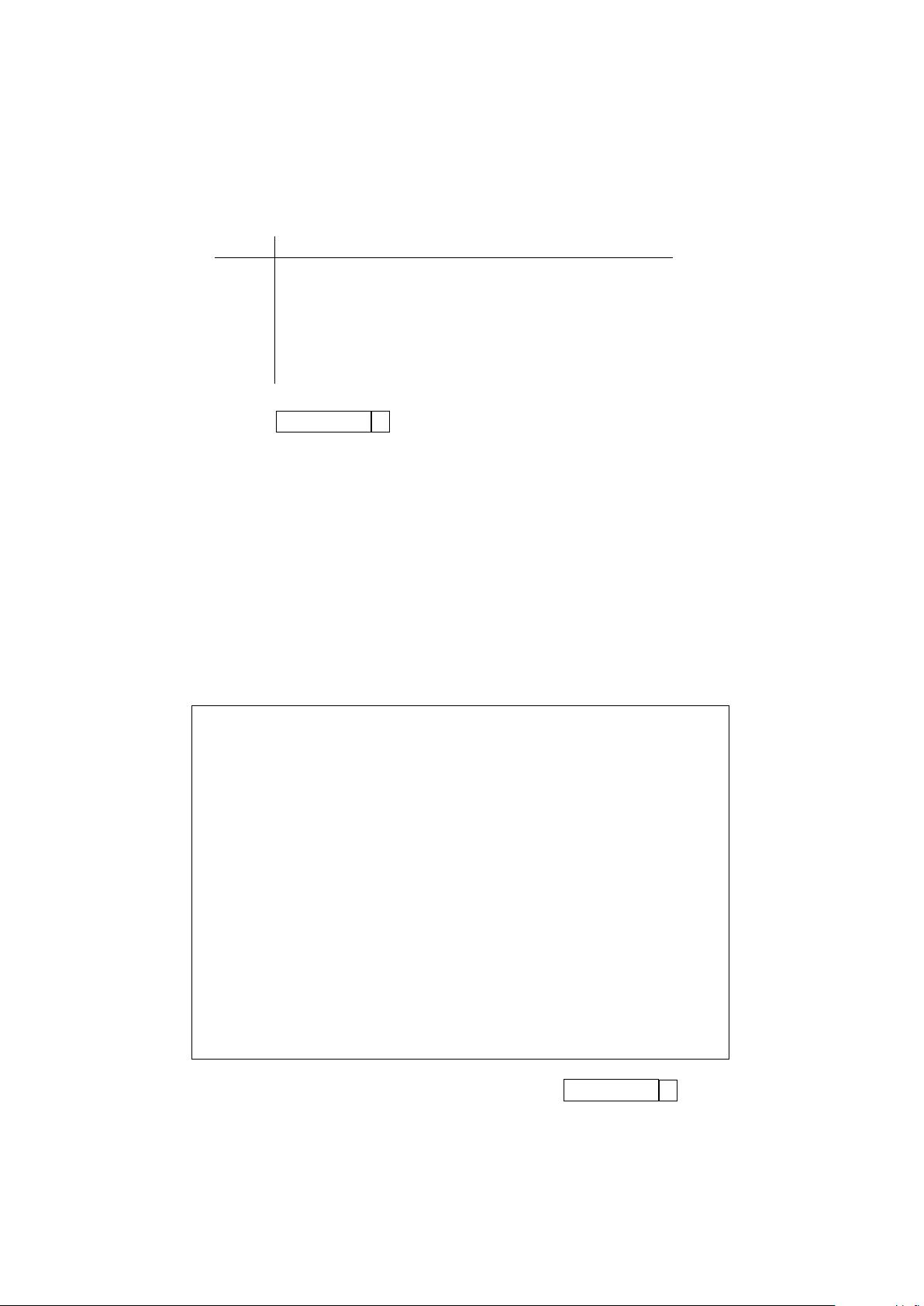
Step 2:
Index F-column L-column
0 A M A P A N
1 A N A M A P
2 A P A N A M
3 M A P A N A
4 N A M A P A
5 P A N A M A
Output: N P M AAA 5
We see in our example that in the output the identical characters are
close together as in the input. The output of these stage is the input for the
next stage, the Move-To-Front Transform.
4 Move-To-Front Transform
As mentioned previously, in this stage the characters of the input get as-
signed a global index value. Therefore, we have in addition to the input
a global list Y . Normally, the global list Y contains all characters of the
ASCII-Code in ascending order. Now we look detailed at the technique of
the Move-To-Front Transform.
Process steps:
1. Save the index value of the global list Y which contains the first
character of the input
2. Move the saved character of the previous step in the global list on
index position 0 and move all characters one position to the right
which are located in the global list before the old position of the
saved character
3. Repeat step 1 and 2 sequentially for the other characters of the
input and use for all repetitions the modified global list from the
previous repetition
The output of this stage consists of all saved index positions and the
index value of the sorted matrix from the Burrows-Wheeler Transform
which contains the original input. This index value won’t processed in
the Move-To-Front Transform.
Now we explain the procedure step by step with NP MAAA 5 (output
of the example from the Burrows-Wheeler Transform) as example input. We
3
剩余11页未读,继续阅读

weixin_38692928
- 粉丝: 6
- 资源: 913
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


