Python爬虫统计BBS性别分布:30万用户案例分析
14 浏览量
更新于2024-08-31
收藏 489KB PDF 举报
本文档详细介绍了如何使用Python实现一个爬虫来统计学校BBS上的用户性别比例,同时包括了项目的背景、需求、实现思路和数据存储策略。首先,项目的目标是统计约30万BBS用户中男、女及保密的性别分布,并记录用户的最后活跃时间,这些信息将被保存在文本文件中,以减少数据量和防止意外中断后的重爬。
实现过程中,关键步骤如下:
1. **项目需求**:
- BBS用户的id与性别信息关联,通常通过点击个人主页链接获取,如`http://rs.xidian.edu.cn/home.php?mod=space&uid=256730&do=profile`。
- 需要抓取所有用户的性别和活跃时间,筛选出2015年活跃的用户。
2. **数据获取**:
- 通过网页源代码分析,性别信息通常在`<li><em>性别</em>女</li>`这样的HTML结构中,使用正则表达式`sexRe`来匹配性别部分。
- 活动时间同样在HTML中,可能格式为`<li><em>上次发表时间</em>2015-11-420:04</li>`,通过`timeRe`正则表达式提取。
3. **数据处理**:
- 存储方案考虑了效率和稳定性,采用分文件存储,每1000条数据为一个文件,例如`correct1-1001.txt`到`correct47001-48001.txt`,便于管理和避免因意外中止而丢失数据。
4. **异常处理**:
- 遇到用户空间不存在的情况,使用`notexistRe`正则表达式进行识别。
5. **技术选型**:
- 选择Python作为实现语言,利用其强大的网络爬虫库(如BeautifulSoup或Scrapy)进行网页抓取。
- 数据存储可以选择文本文件,虽然不适用于大数据量,但对于小规模的数据处理足够高效且易于维护。
总结,此篇文章为初学者提供了一个Python爬虫的基础示例,展示了如何通过网页解析、正则表达式和分文件存储等方式,实现对学校BBS用户性别人数和活跃时间的统计。对于学习Python爬虫和数据处理的同学,这是一个很好的实践案例。
python实现爬虫统计学校实现爬虫统计学校BBS男女比例(一)男女比例(一)
主要介绍了python实现爬虫统计学校BBS男女比例,,需要的朋友可以参考下
一、项目需求一、项目需求
前言:BBS上每个id对应一个用户,他们注册时候会填写性别(男、女、保密三选一)。
经过检查,BBS注册用户的id对应1-300000,大概是30万的用户
笔者想用Python统计BBS上有多少注册用户,以及这些用户的性别分布
顺带可以统计最近活动用户是多少,其中男、女、保密各占多少
活动用户的限定为“上次活动时间”为 2015年
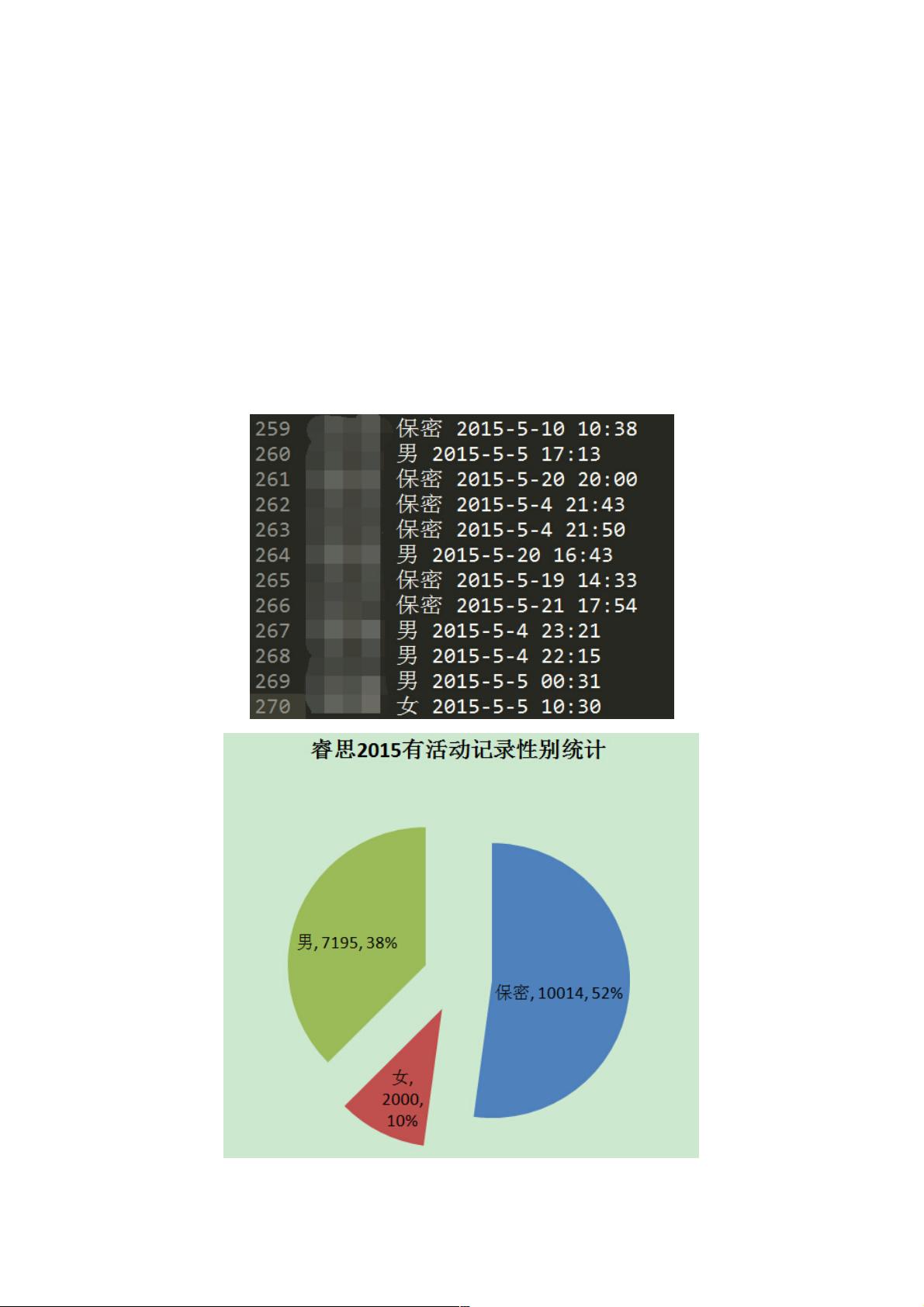
二、最终结果二、最终结果
性别信息保存在文本里,一行表示一个用户的信息,各列分别表示
【行数,id(涂掉了),性别,最后活跃时间】
下载后可阅读完整内容,剩余4页未读,立即下载
2020-09-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-23 上传
2024-11-23 上传

weixin_38588854
- 粉丝: 11
- 资源: 958
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
