专家系统数据仓库构建:实时与离线数据处理
版权申诉
164 浏览量
更新于2024-07-03
收藏 2.47MB PDF 举报
"该数据仓库建设方案详述了如何构建一个高效的数据仓库系统,特别是针对互联网领域的专家系统。方案强调了数据仓库的总体架构、数据采集、数据存储、数据分析以及数据服务等方面的关键要素,旨在实现对列车监控数据的高效处理和智能分析。"
1. 数据仓库总体架构
数据仓库的构建主要包括四个主要部分:数据采集、数据存储、数据分析和数据服务。数据采集负责从各个业务系统中获取数据,而数据存储则利用Hdfs、Hbase和RDBMS的混合模式来处理海量分布式数据。数据分析支持传统的OLAP分析和基于Spark的机器学习算法,以实现深入的数据洞察。最后,数据服务总线提供统一的数据管理和调度,对外提供数据服务接口。
2. 数据采集
数据采集分为外部数据汇集和内部数据提取与加载两大部分。外部数据汇集涉及从如TCMS和车载子系统等外部信息系统收集数据,内部数据提取与加载则涉及数据仓库内部不同存储层之间的数据处理。实时和非实时数据采集是数据采集的两种主要类型,前者针对实时监测指标,后者涉及定期维护数据。
3. 外部数据汇集
数据源包括列车监控系统和车载子系统,采集内容分为实时和非实时两类。考虑到大规模、高频度的数据采集需求,方案采用Flume+Kafka+Storm的架构,其中Flume和ETL工具用于生成Kafka消息,Storm则作为消费者,实现高吞吐量的实时数据处理和预警功能。
4. 数据汇集架构功能
Flume用于从多种源头收集数据,包括控制台、RPC接口等,Kafka作为中间消息队列,保证数据传输的可靠性和高效率,而Storm则处理Kafka中的数据,进行实时分析,以快速响应异常指标。
5. 数据存储
数据存储解决方案结合了Hdfs(分布式文件系统)、Hbase(NoSQL数据库)和RDBMS(关系型数据库管理系统),以适应不同类型的存储需求,支持海量数据的高效存储和查询。
6. 数据分析与服务
数据仓库体系支持传统的在线分析处理(OLAP)和基于Spark的机器学习算法,使得系统能够进行复杂的业务分析和预测。数据服务总线确保了数据资源的统一管理和调度,方便外部系统访问和利用数据。
该数据仓库建设方案旨在建立一个能应对互联网环境下的大数据挑战,提供高效数据处理、智能分析和灵活扩展能力的专家系统,以优化列车监控和故障诊断,提升服务质量。
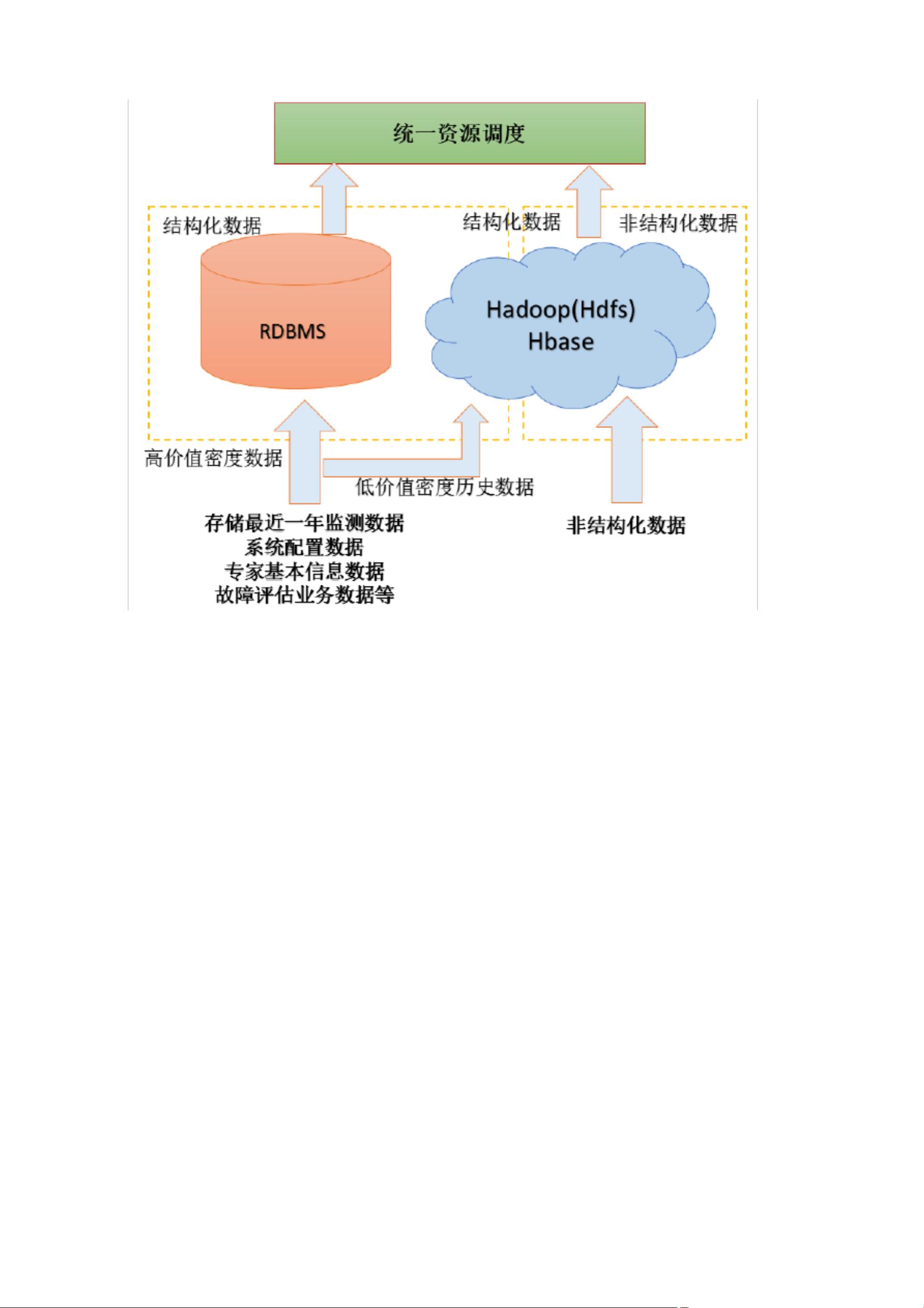
1. RDBMS 数据库,支持专家库核心业务,存储列车近来 1 年监测数据为保
证专家系统安全、稳定运营,在数据库系统上支撑各种记录分析及老式 BI
业务。考虑到操作系统存储、缓存存储、数据库系统存储、日记存储等因
素, RDBMS 数据库服务器预测每台 60T 存储,考虑数据安全及系统稳定
因素 RDBMS 采用双机热备技术互备。
2. 大数据平台规划存储近来监测数据,日记文献备份及历史数据采用大数据
Hadoop 和 HBase 存储,大数据平台数据采用节点间冗余备份,预设数据2
倍冗余存储,
(考虑平台提供压缩技术,压缩存储可以节约 30-55%空间)。
数据量=530T*1.5≈ 800T (2 倍冗余存储)
剩余34页未读,继续阅读
2022-06-06 上传
2021-10-06 上传
2022-06-19 上传
2023-09-06 上传
2023-07-12 上传
2023-07-08 上传
2023-05-18 上传
2023-07-27 上传
2023-08-27 上传

苦茶子12138
- 粉丝: 1w+
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
