Hadoop-YARN:从单点故障到资源优化的革新
54 浏览量
更新于2024-08-28
收藏 300KB PDF 举报
Hadoop-YARN是Hadoop框架在Hadoop 2.0版本中的重大改进,旨在解决MapReduce 1.0中存在的问题。MapReduce 1.0存在几个关键缺陷:
1. 单点故障:原有的JobTracker是中心化的,一旦它发生故障,整个系统就会受到影响,这在分布式环境中是不可接受的。YARN通过引入ResourceManager和NodeManager的分层架构,提高了系统的可靠性。
2. 资源管理和负载过大:JobTracker承担了过多职责,当任务数量增加时,内存消耗巨大,且有上限限制(4000个节点),这导致资源分配效率低下。YARN将资源管理与计算任务分离,使得资源分配更灵活,可以根据实际需求动态调整。
3. 内存溢出问题:原版MapReduce仅关注MapReduce任务的数量,而忽视了CPU和内存的平衡。YARN通过引入更智能的资源分配策略,如按需分配,减少了内存溢出的风险。
4. 资源划分不合理:MapReduce 1.0采用固定大小的slot(如Mapslot和Reduceslot)划分资源,限制了应用程序的灵活性。YARN中的容器(Container)模型更为灵活,可以根据实际需要动态调整每个应用程序占用的资源。
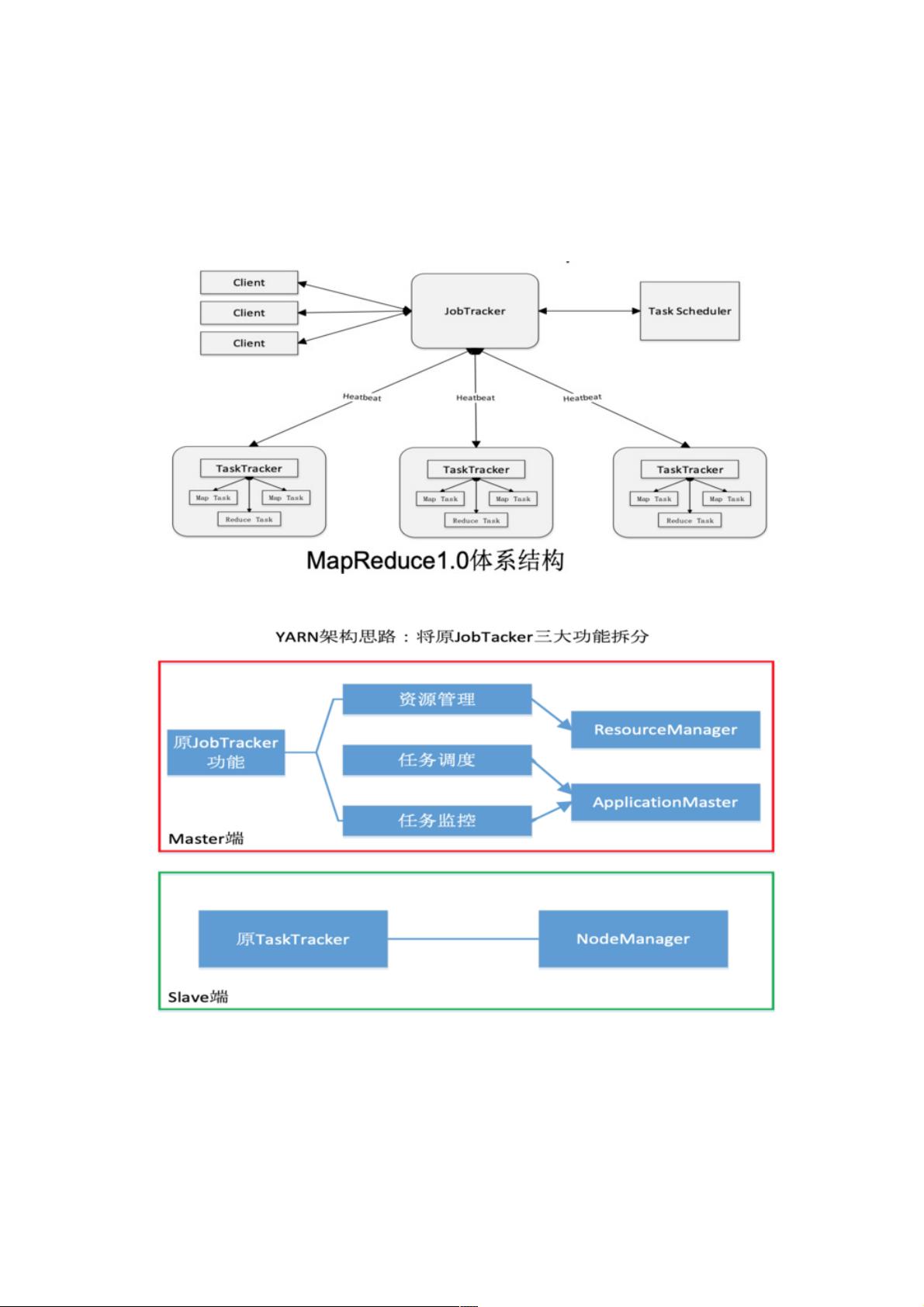
在YARN体系结构中,ResourceManager (RM) 是核心组件之一,它作为全局资源管理者,负责整个系统的资源分配和调度。RM包含调度器和应用程序管理器,其中调度器根据数据位置和策略决定容器的分配,确保计算与数据的紧密配合。容器作为动态资源分配单元,为应用程序提供了更精细的资源控制。
另一个重要组件是ApplicationMaster (AM),它代表一个应用程序向RM申请资源,然后将这些资源分配给内部的任务,同时负责任务调度、监控和错误恢复。NodeManager则在每个节点上执行资源管理,响应来自RM和AM的命令,确保本地资源的有效利用。
通过这些改变,Hadoop-YARN显著提升了系统的扩展性、资源利用率和稳定性,使得Hadoop能够更好地服务于大规模数据处理和分布式计算场景。同时,YARN的设计也为用户提供了更大的定制空间,允许用户根据业务需求选择合适的调度策略。
Hadoop-YARNIntroduce
1. MapReduce1.0缺陷
(1)存在单点故障
(2)JobTracker“大包大揽”导致任务过重(任务多时内存开销大,上限4000节点)
(3)容易出现内存溢出(分配资源只考虑MapReduce任务数,不考虑CPU、内存)
(4)资源划分不合理(强制划分为slot ,包括Map slot和Reduce slot)
2. YARN体系结构
MapReduce1.0既是一个计算框架,也是一个资源管理调度框架
到了Hadoop2.0以后,MapReduce1.0中的资源管理调度功能,被单独分离出来形成了YARN,它是一个纯粹的资源管理调度
框架,而不是一个计算框架
被剥离了资源管理调度功能的MapReduce 框架就变成了MapReduce2.0,它是运行在YARN之上的一个纯粹的计算框架,不
再自己负责资源调度管理服务,而是由YARN为其提供资源管理调度服务
下载后可阅读完整内容,剩余3页未读,立即下载
2017-12-02 上传
2022-05-01 上传
2022-04-23 上传
2023-06-05 上传
starting datanode, logging to /opt/software/hadoop/hadoop-2.9.2/logs/hadoop-root-datanode-node01.out
2023-07-12 上传
2023-06-11 上传
2023-06-08 上传
2024-08-28 上传
2023-02-06 上传
2023-05-16 上传

weixin_38652196
- 粉丝: 2
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
