Google MapReduce模型:大规模数据处理的关键
需积分: 50 26 浏览量
更新于2024-07-18
收藏 1.05MB PDF 举报
MapReduce是一种革命性的编程模型和实现,由Google提出,用于高效处理大规模数据集。该模型的核心思想是将复杂的并行和分布式计算任务分解为两个主要阶段:map和reduce。在map阶段,用户编写一个函数,负责处理输入数据(key/value对),将其转换为一系列中间结果。这些中间结果按照key进行分组,然后进入reduce阶段,用户再次定义一个函数,用于合并具有相同key的所有值,生成最终的汇总结果。
通过MapReduce,程序员只需关注业务逻辑,而不必深入底层的并行调度、数据分布、错误处理等复杂问题。Google的MapReduce实现能在大规模的普通机器集群上运行,即使涉及TB级别的数据处理,也能实现高效的并行执行。这种灵活性使得即使是没有分布式处理经验的开发者也能够利用这种强大的计算资源。
在过去五年中,Google内部已经成功应用MapReduce处理大量数据,例如网页爬取、文档分析、日志处理等,生成诸如倒排索引、网络结构表示等多种派生数据。每个MapReduce作业都可以轻松扩展到数千台机器上,这极大地提高了数据处理的效率和可伸缩性。
MapReduce的设计灵感来源于函数式编程中的map和reduce概念,这两个核心操作在很多计算任务中都非常常见,如数据清洗、聚合和变换。通过封装这些复杂性,MapReduce简化了数据处理流程,使得原本繁琐的并行计算工作变得直观易用,极大地推动了大数据时代的到来。
MapReduce是大数据处理领域的重要里程碑,它不仅提供了一种通用的编程框架,还降低了大规模数据处理的门槛,促进了云计算和大数据分析技术的发展。
reduce 函数不改变任何的对。这个计算依
赖分割工具(在 4.1 描述)和排序属性(在 4.2
描述)。
3 实现
MapReduce 接口可能有许多不同的实
现。根据环境进行正确的选择。例如,一
个实现对一个共享内存较小的机器是合适
的,另外的适合一个大 NUMA 的多处理器
的机器,而有的适合一个更大的网络机器
的集合。
这部分描述一个在 Google 广泛使用的
计算环境的实现:用交换机连接的普通 PC
机的大集群。我们的环境是:
1. Linux 操作系统、双处理器、2-4GB
内存的机器。
2. 普通的网络硬件、每个机器的带宽
或者是百兆或者千兆、但是平均小于全部
带宽的一半。
3. 因为一个机群包含成百上千的机
器,所有机器会经常出现问题。
4. 存储用直接连到每个机器上的廉价
IDE 硬盘。一个从内部文件系统发展起来
的分布式文件系统被用来管理存储在这些
磁盘上的数据。文件系统用复制的方式在
不可靠的硬件上来保证可靠性和有效性。
5. 用户提交工作给调度系统。每个工
作包含一个任务集,每个工作被调度者映
射到机群中一个可用的机器集上。
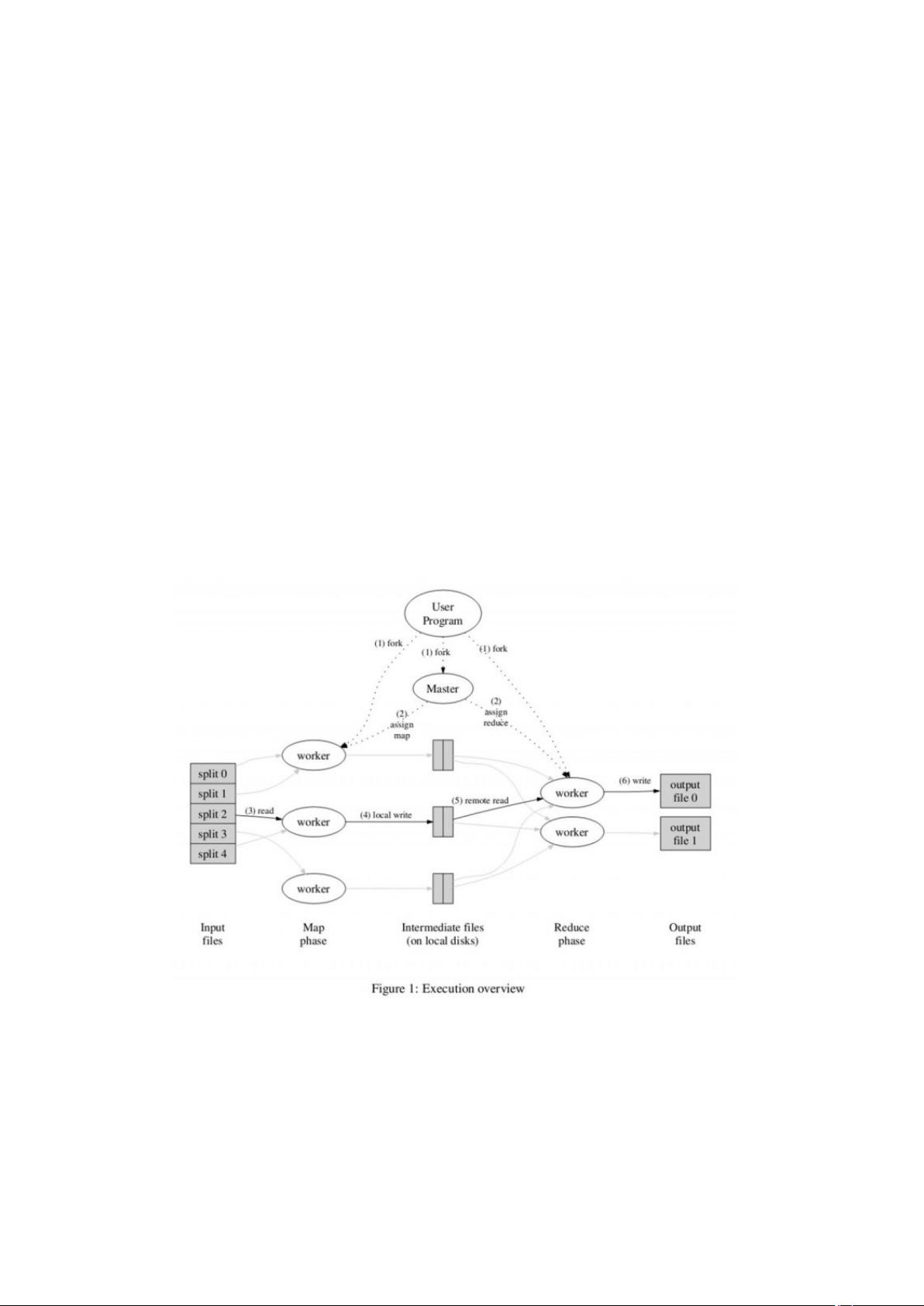
3.1 执行预览
通过自动分割输入数据成一个有 M 个
split 的集,map 调用被分布到多台机器
上。输入的 split 能够在不同的机器上被并
行处理。通过用分割函数分割中间 key,
来形成 R 个片(例如,hash(key) mod R),
reduce 调用被分布到多台机器上。分割数
量(R)和分割函数由用户来指定。
图 1 显示了我们实现的 MapReduce
操作的全部流程。当用户的程序调用
MapReduce 的函数的时候,将发生下面的
一系列动作(下面的数字和图 1 中的数字标
签相对应):
1. 在用户程序里的 MapReduce 库首先
分割输入文件成 M 个片,每个片的大小一
般从 16 到 64MB(用户可以通过可选的参
数来控制)。然后在机群中开始大量的拷贝
程序。
2. 这些程序拷贝中的一个是 master,其
他的都是由 master 分配任务的 worker。
有 M 个 map 任务和 R 个 reduce 任务将
剩余14页未读,继续阅读
153 浏览量
541 浏览量
116 浏览量
184 浏览量
804 浏览量
352 浏览量
130 浏览量

snowleopard331
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows编程之API函数大全
- 89s51 好程序 各种
- TOGAF-tutorial-presentation
- 89s51数字钟 程序
- GCC 中文用户手册
- mobile phone
- The Implement of Remote Control Software by using Java
- 自己整理的websphere portal主题皮肤开发资料
- websphere portal6.1主题皮肤开发资料
- VB入门实用教程(全)
- VMware Workstation使用手册
- 计算机专业英语教材计算机专业英语教材
- 000-960 的资料
- Flash读取数据库技术4
- Flash读取数据库技术3
- Flash读取数据库技术2
