2022搜狐文本匹配算法大赛:NLP实战与策略解析
需积分: 0 196 浏览量
更新于2024-08-03
收藏 3.82MB PDF 举报
在2022年10月12日的搜狐文本匹配算法大赛方案总结中,我们了解到这个比赛聚焦于自然语言理解和推理的挑战,特别是在自然语言推理(Natural Language Inference, NLI)领域。NLI要求机器理解文本的深层语义,并根据上下文进行逻辑推断,判断两个句子之间的关系。搜狐主办的这场校园算法大赛旨在通过30万条人工标注的数据,提供实战经验,提升参赛者在文本匹配方面的技能。
赛题设计非常细致,分为宽泛和严格两个颗粒度的匹配标准。宽泛的A文件匹配标准只要求两段文字属于同一话题就算匹配,而严格的B文件则需要判断两段文字是否描述的是同一个事件。每个参赛选手需要处理的数据包括两个文件,A和B,其中A文件包含18万条数据,复赛阶段有3万条,决赛阶段有9万条,数据格式为JSON,每条记录都包含source(第一段文字)、target(第二段文字)以及对应的labelA和labelB,用于表示在不同文件下的匹配状态。
比赛的数据来源于人工标注,具有较高的质量和真实性,这对于参与者来说既是机遇也是挑战,因为机器需要具备高级的语义理解能力,不仅识别主题,还要深入分析事件的一致性。此次大赛不仅促进了机器学习和深度学习技术的发展,也为人工智能咨询提供了实战案例,让参赛者有机会将理论知识应用于实际问题解决中。
通过参与这场比赛,参赛者可以提升以下技能:
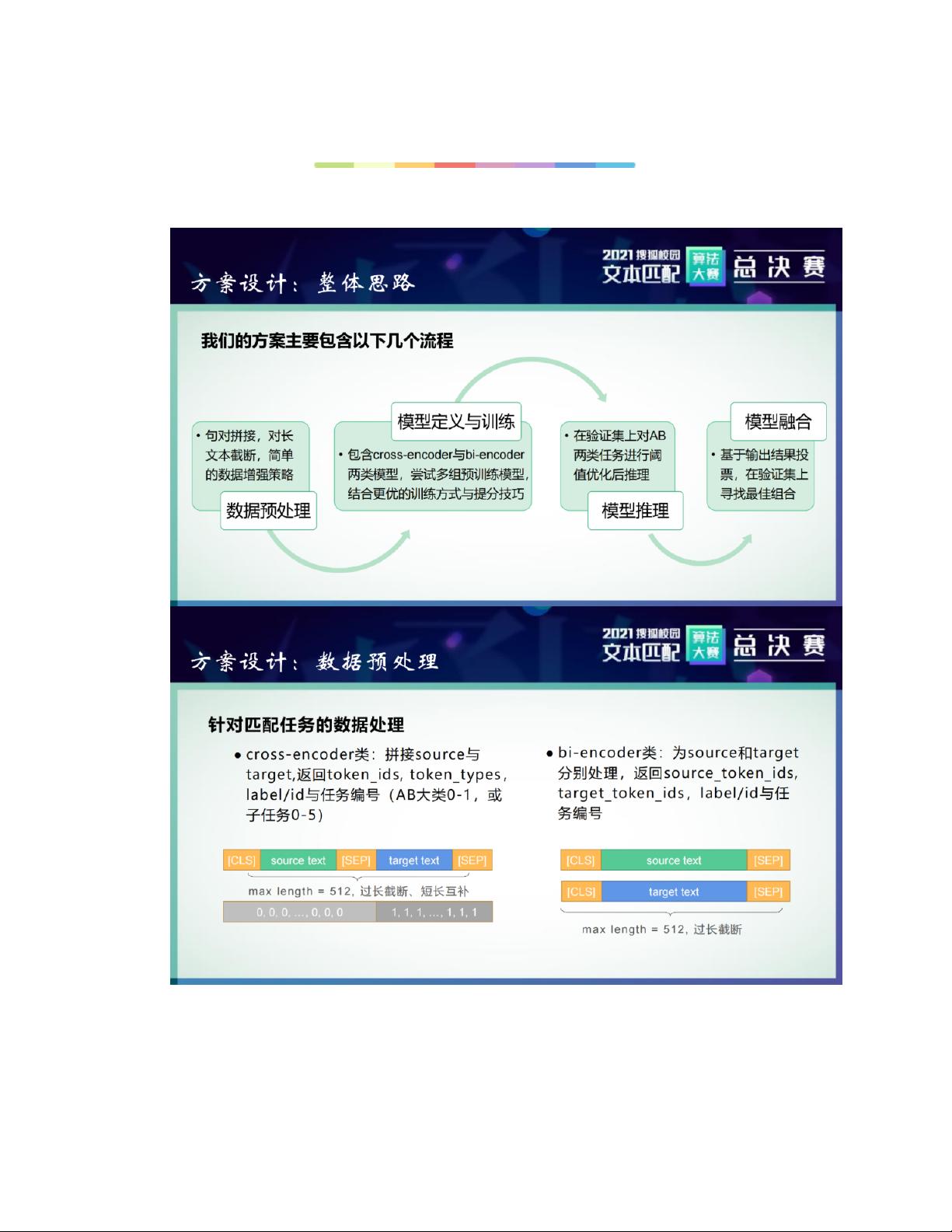
1. 自然语言处理(NLP)技术:包括文本预处理、特征提取、模型训练等,如BERT、RoBERTa等模型在文本匹配任务中的应用。
2. 语义理解与推理:如何解析和理解句子的深层含义,以及如何进行有效的推理来判断文本关系。
3. 数据分析与挖掘:通过处理大量标注数据,学习如何分析文本模式和特征,优化算法性能。
4. 模型评估与调优:理解不同匹配标准下的模型性能差异,学会调整模型参数以适应不同任务需求。
这次搜狐文本匹配算法大赛是一次集理论与实践于一体的机器学习和人工智能盛宴,为参与者提供了一个锻炼和提升专业技能的平台,同时也推动了该领域在实际应用中的发展。
优胜方案
第2名
剩余13页未读,继续阅读
2024-01-14 上传
2021-04-16 上传
2024-01-14 上传
3394 浏览量
2474 浏览量
1085 浏览量
2304 浏览量
点击了解资源详情

毕业小助手
- 粉丝: 2761
- 资源: 5583
 我的内容管理
展开
我的内容管理
展开







最新资源
- cumpositiontyp,c语言聊天软件源码详解,c语言
- 1click Paintbrush-crx插件
- private_party
- tiffread2.m:读取 tiff 文件,包括带有信息的堆栈-matlab开发
- yipay:易支付
- pdi-ce-9.5.0.1-261.zip
- bond-cni:Bond-cni用于实现云编排中的故障转移和网络的高可用性
- 软硬
- 猫和老鼠主题的简单网页(HTML+CSS)
- ASO –适用于初学者的应用商店优化
- 940383,c语言的源码不能跨平台,c语言
- 互联网IT科技互联网站模板
- node_mysql_retrogaming:一个带有NodeJS,Express和MySQL的附带项目
- project_code_print:打印源代码到word文档里面,方便纸质阅读。简易树形图,压缩代码行间距,尽量节省纸张
- 社交媒体策略:在获得客户的Facebook和Twitter帐户访问权限并从其帖子下载参与度指标后,为其创建了社交媒体策略。 步骤包括数据清理和新变量的特征工程,将每个帖子分类为不同的主题,创建视觉效果,自然语言处理和回归分析,所有这些操作均使用Python完成
- MinecraftChat:基于Minecraft的网络聊天客户端
