Kafka深度解析:分布式流式处理平台与实战
需积分: 45 114 浏览量
更新于2024-07-16
收藏 4.49MB PDF 举报
"《图解 Kafka 之实战指南》PDF"
Kafka 是一个由LinkedIn最初开发,现由Apache基金会维护的分布式消息系统,它使用Scala编程语言构建,并依赖ZooKeeper进行协调。作为一款高性能、可持久化的分布式流处理平台,Kafka在业界广泛应用,与众多开源分布式处理系统如Cloudera、Storm、Spark、Flink等有着良好的集成。
Kafka的核心特性使其在消息传递领域独具优势。它扮演着消息系统、存储系统和流式处理平台的三重角色:
1. **消息系统**:Kafka提供了解耦系统、冗余存储、流量控制、缓冲、异步通信和扩展性等传统消息中间件的功能。此外,它还支持消息顺序性和回溯消费,这是许多消息系统难以实现的特性。
2. **存储系统**:Kafka的消息持久化到硬盘,增强了数据安全性。通过多副本机制,Kafka可作为长期数据存储,只需调整数据保留策略或启用日志压缩。
3. **流式处理平台**:Kafka不仅是流式处理框架的数据源,还提供了一套完整的流处理操作,如窗口、连接、转换和聚合等。
在Kafka的基本架构中,有四个关键组件:
- **Producer**:生产者负责生成消息并将其发送到Kafka集群。它们决定了消息的生产和发布策略。
- **Broker**:服务代理节点,存储和转发消息。每个Broker都是独立的服务实体,通常部署在单独的服务器上,负责接收和处理来自Producer的消息,同时向Consumer提供消息。
- **Consumer**:消费者从Broker订阅主题并消费消息。它们可以是单个实例或消费者组的一部分,用于处理和分析数据。
- **ZooKeeper**:作为协调工具,ZooKeeper管理Kafka集群的元数据,执行控制器选举,确保集群的高可用性和一致性。
Kafka体系结构中的几个关键概念还包括:
- **Topic**:主题是消息的分类,Producer将消息发布到特定主题,Consumer则订阅这些主题来消费消息。
- **Partition**:分区是主题的逻辑细分,每个分区在所有Broker之间分配。分区保证了消息的顺序性,并且在同一分区内的消息是有序的。
- **Offset**:偏移量是消息在分区中的位置,Consumer通过offset追踪已读消息,以便下次从上次读取的位置继续。
- **Consumer Group**:消费者组是一组消费者,每个主题的分区只能被组内的一个消费者消费,实现负载均衡和容错。
理解这些核心概念和架构原理,将有助于开发者更有效地利用Kafka进行数据处理和传输,构建可靠的分布式系统。在《图解 Kafka 之实战指南》中,读者可以深入学习Kafka的配置、部署、性能优化以及实际应用案例,从而更好地掌握这一强大的技术。
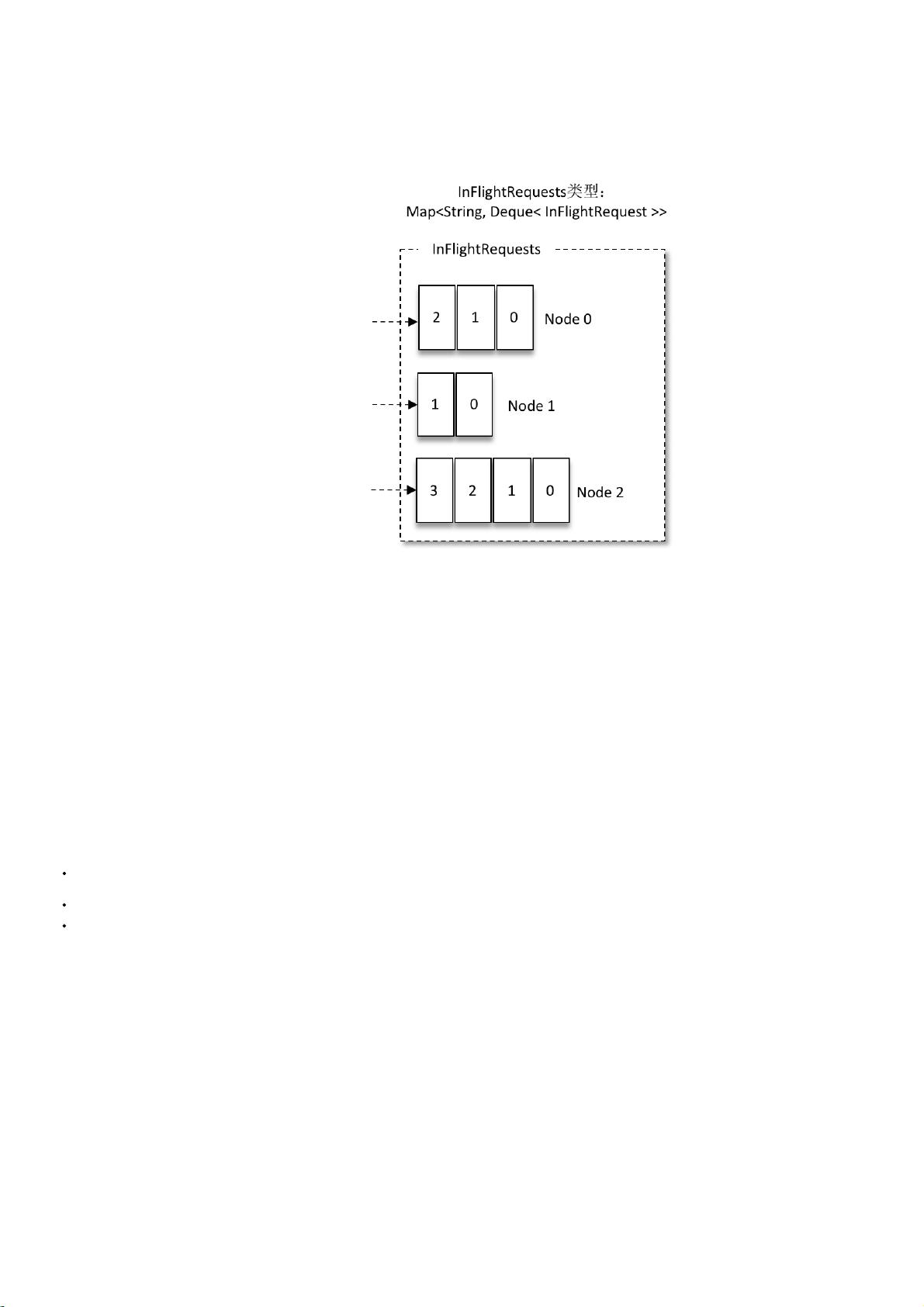
是⼀个String类型,表⽰节点的id编号)。与此同时,InFlightRequests还提供了许多管理类的⽅法,并且通过配置参数还可以限制每个连接(也就是客户端与Node之间的连接)最多缓存的请求数。这
个配置参数为max.in.flight.requests.per.connection,默认值为5,即每个连接最多只能缓存5个未响应的请求,超过该数值之后就不能再向这个连接发送更多的请求了,除⾮有缓存的请求收到了响应
(Response)。通过⽐较Deque的size与这个参数的⼤⼩来判断对应的Node中是否已经堆积了很多未响应的消息,如果真是如此,那么说明这个Node节点负载较⼤或⽹络连接有问题,再继续向其发送
请求会增⼤请求超时的可能。
元数据的更新
前⾯提及的InFlightRequests还可以获得leastLoadedNode,即所有Node中负载最⼩的那⼀个。这⾥的负载最⼩是通过每个Node在InFlightRequests中还未确认的请求决定的,未确认的请求越多则认为负
载越⼤。对于下图中的InFlightRequests来说,图中展⽰了三个节点Node0、Node1和Node2,很明显Node1的负载最⼩。也就是说,Node1为当前的leastLoadedNode。选择leastLoadedNode发送请求可以
使它能够尽快发出,避免因⽹络拥塞等异常⽽影响整体的进度。leastLoadedNode的概念可以⽤于多个应⽤场合,⽐如元数据请求、消费者组播协议的交互。
我们使⽤如下的⽅式创建了⼀条消息ProducerRecord:
ProducerRecord<String, String> record =
new ProducerRecord<>(topic, "Hello, Kafka!");
我们只知道主题的名称,对于其他⼀些必要的信息却⼀⽆所知。KafkaProducer要将此消息追加到指定主题的某个分区所对应的leader副本之前,⾸先需要知道主题的分区数量,然后经过计算得出(或者
直接指定)⽬标分区,之后KafkaProducer需要知道⽬标分区的leader副本所在的broker节点的地址、端⼜等信息才能建⽴连接,最终才能将消息发送到Kafka,在这⼀过程中所需要的信息都属于元数据
信息。
在第3节中我们了解了bootstrap.servers参数只需要配置部分broker节点的地址即可,不需要配置所有broker节点的地址,因为客户端可以⾃⼰发现其他broker节点的地址,这⼀过程也属于元数据相关的
更新操作。与此同时,分区数量及leader副本的分布都会动态地变化,客户端也需要动态地捕捉这些变化。
元数据是指Kafka集群的元数据,这些元数据具体记录了集群中有哪些主题,这些主题有哪些分区,每个分区的leader副本分配在哪个节点上,follower副本分配在哪些节点上,哪些副本在AR、ISR等
集合中,集群中有哪些节点,控制器节点又是哪⼀个等信息。
当客户端中没有需要使⽤的元数据信息时,⽐如没有指定的主题信息,或者超过metadata.max.age.ms时间没有更新元数据都会引起元数据的更新操作。客户端参数metadata.max.age.ms的默认值为
300000,即5分钟。元数据的更新操作是在客户端内部进⾏的,对客户端的外部使⽤者不可见。当需要更新元数据时,会先挑选出leastLoadedNode,然后向这个Node发送MetadataRequest请求来获取具
体的元数据信息。这个更新操作是由Sender线程发起的,在创建完MetadataRequest之后同样会存⼊InFlightRequests,之后的步骤就和发送消息时的类似。元数据虽然由Sender线程负责更新,但是主线
程也需要读取这些信息,这⾥的数据同步通过synchronized和final关键字来保障。
重要的⽣产者参数
在KafkaProducer中,除了第3节提及的3个默认的客户端参数,⼤部分的参数都有合理的默认值,⼀般不需要修改它们。不过了解这些参数可以让我们更合理地使⽤⽣产者客户端,其中还有⼀些重要的参
数涉及程序的可⽤性和性能,如果能够熟练掌握它们,也可以让我们在编写相关的程序时能够更好地进⾏性能调优与故障排查。下⾯挑选⼀些重要的参数进⾏讲解。
1.acks
这个参数⽤来指定分区中必须要有多少个副本收到这条消息,之后⽣产者才会认为这条消息是成功写⼊的。acks是⽣产者客户端中⼀个⾮常重要的参数,它涉及消息的可靠性和吞吐量之间的权衡。acks
参数有3种类型的值(都是字符串类型)。
acks=1。默认值即为1。⽣产者发送消息之后,只要分区的leader副本成功写⼊消息,那么它就会收到来⾃服务端的成功响应。如果消息⽆法写⼊leader副本,⽐如在leader副本崩溃、重新选举新
的leader副本的过程中,那么⽣产者就会收到⼀个错误的响应,为了避免消息丢失,⽣产者可以选择重发消息。如果消息写⼊leader副本并返回成功响应给⽣产者,且在被其他follower副本拉取之
前leader副本崩溃,那么此时消息还是会丢失,因为新选举的leader副本中并没有这条对应的消息。acks设置为1,是消息可靠性和吞吐量之间的折中⽅案。
acks=0。⽣产者发送消息之后不需要等待任何服务端的响应。如果在消息从发送到写⼊Kafka的过程中出现某些异常,导致Kafka并没有收到这条消息,那么⽣产者也⽆从得知,消息也就丢失
了。在其他配置环境相同的情况下,acks设置为0可以达到最⼤的吞吐量。
acks=-1或acks=all。⽣产者在消息发送之后,需要等待ISR中的所有副本都成功写⼊消息之后才能够收到来⾃服务端的成功响应。在其他配置环境相同的情况下,acks设置为-1(all)可以达到
最强的可靠性。但这并不意味着消息就⼀定可靠,因为ISR中可能只有leader副本,这样就退化成了acks=1的情况。要获得更⾼的消息可靠性需要配合min.insync.replicas等参数的联动,消息可靠性
分析的具体内容可以参考《图解Kafka之核⼼原理》。
注意acks参数配置的值是⼀个字符串类型,⽽不是整数类型。举个例⼦,将acks参数设置为0,需要采⽤下⾯这两种形式:
properties.put("acks", "0");
# 或者
properties.put(ProducerConfig.ACKS_CONFIG, "0");
⽽不能配置成下⾯这种形式:
properties.put("acks", 0);
# 或者
properties.put(ProducerConfig.ACKS_CONFIG, 0);
这样会报出如下的异常:
org.apache.kafka.common.config.ConfigException: Invalid value 0 for configuration acks: Expected value to be a string, but it was a java.lang.Integer.
2.max.request.size
这个参数⽤来限制⽣产者客户端能发送的消息的最⼤值,默认值为1048576B,即1MB。⼀般情况下,这个默认值就可以满⾜⼤多数的应⽤场景了。
笔者并不建议读者盲⽬地增⼤这个参数的配置值,尤其是在对Kafka整体脉络没有⾜够把控的时候。因为这个参数还涉及⼀些其他参数的联动,⽐如broker端的message.max.bytes参数,如果配置错误可
能会引起⼀些不必要的异常。⽐如将broker端的message.max.bytes参数配置为10,⽽max.request.size参数配置为20,那么当我们发送⼀条⼤⼩为15B的消息时,⽣产者客户端就会报出如下的异常:
org.apache.kafka.common.errors.RecordTooLargeException: The request included a message larger than the max message size the server will accept.
3.retries和retry.backoff.ms
retries参数⽤来配置⽣产者重试的次数,默认值为0,即在发⽣异常的时候不进⾏任何重试动作。消息在从⽣产者发出到成功写⼊服务器之前可能发⽣⼀些临时性的异常,⽐如⽹络抖动、leader副本的选
举等,这种异常往往是可以⾃⾏恢复的,⽣产者可以通过配置retries⼤于0的值,以此通过内部重试来恢复⽽不是⼀味地将异常抛给⽣产者的应⽤程序。如果重试达到设定的次数,那么⽣产者就会放弃重
试并返回异常。不过并不是所有的异常都是可以通过重试来解决的,⽐如消息太⼤,超过max.request.size参数配置的值时,这种⽅式就不可⾏了。

剩余70页未读,继续阅读
2023-10-07 上传
2019-08-19 上传
2021-06-19 上传
点击了解资源详情
点击了解资源详情

小枫小枫
- 粉丝: 1
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
