揭秘SparkSQL Catalyst PhysicalPlan:从逻辑到物理执行的关键步骤
183 浏览量
更新于2024-08-27
收藏 315KB PDF 举报
在SparkSQL的Catalyst源码分析系列中,物理计划(PhysicalPlan)是整个执行流程的关键环节,它位于优化器(Optimizer)和实际的Spark任务执行之间。物理计划是在逻辑计划(LogicalPlan)经过Analyzer和Optimizer处理后的产物,它是Spark SQL执行Spark作业的最终蓝图,用于指导数据处理的低级别操作。
SparkPlanner是这一阶段的核心组件,它的作用是将已经优化过的逻辑计划(OptimizedLogicalPlan)转换为物理计划。在代码中,首先调用optimizer方法对逻辑计划进行优化,然后通过planner对象执行转换,生成物理计划。SparkPlanner继承了SparkStrategies,这是一个策略容器,包含了多个策略类(如CommandStrategy, TakeOrdered, PartialAggregation等),这些策略类各自负责处理不同类型的逻辑操作,比如命令执行、排序、部分聚合等。
CommandStrategy负责处理基本的SQL命令,如SELECT、INSERT等;TakeOrdered则关注于对结果集进行排序;PartialAggregation处理部分聚合操作,而不是全部汇总;LeftSemiJoin用于处理左半连接;HashJoin则是用于执行哈希连接,提高数据关联性能;InMemoryScans处理内存中的数据扫描;ParquetOperation则针对Parquet文件格式进行操作。
SparkPlanner的实例化时,会依赖SparkContext和SQLContext,同时也设置了一个默认的分区数(numPartitions)。这些参数的选择对Spark任务的并行性和性能有着重要影响。例如,合理的分区数可以确保数据的有效分布,从而提升分布式计算的效率。
物理计划阶段是将抽象的逻辑操作转化为具体执行步骤的过程,每个策略都在这个过程中发挥关键作用,确保Spark SQL能够高效地执行SQL查询并返回结果。理解这些内部机制对于深入学习Spark SQL的运行原理和优化至关重要。
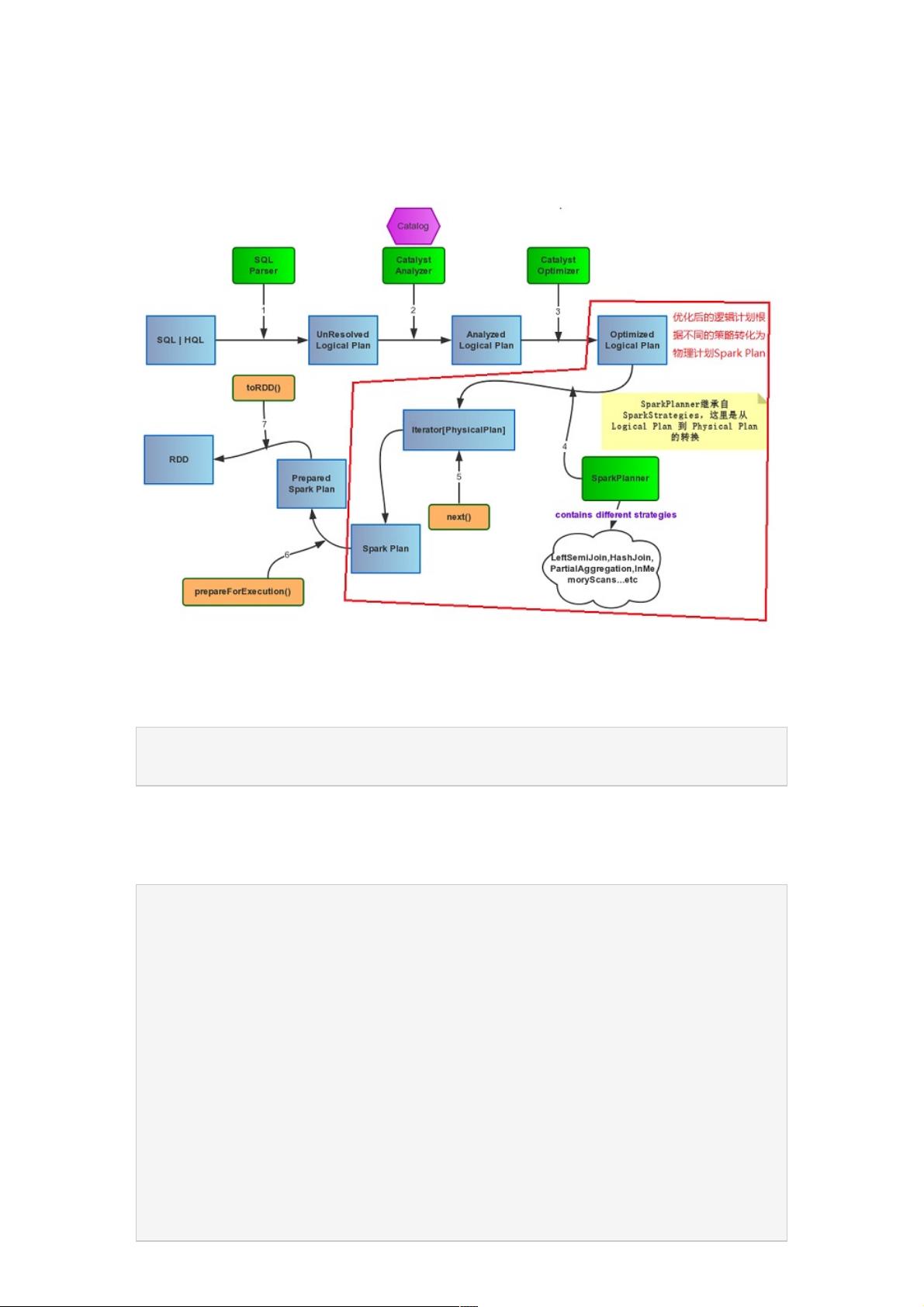
SparkSQLCatalyst源码分析之源码分析之PhysicalPlan
前面几篇文章主要介绍的是spark sql包里的的spark sql执行流程,以及Catalyst包内的SqlParser,Analyzer和Optimizer,最
后要介绍一下Catalyst里最后的一个Plan了,即Physical Plan。物理计划是Spark SQL执行Spark job的前置,也是最后一道计
划。
如图:
一、SparkPlanner
话接上回,Optimizer接受输入的Analyzed Logical Plan后,会有SparkPlanner来对Optimized Logical Plan进行转换,生成
Physical plans。
lazy val optimizedPlan = optimizer(analyzed)
// TODO: Don't just pick the first one...
lazy val sparkPlan = planner(optimizedPlan).next()
SparkPlanner继承了SparkStrategies,SparkStrategies继承了QueryPlanner。
SparkStrategies包含了一系列特定的Strategies,这些Strategies是继承自QueryPlanner中定义的Strategy,它定义接受一个
Logical Plan,生成一系列的Physical Plan
@transient
protected[sql] val planner = new SparkPlanner
protected[sql] class SparkPlanner extends SparkStrategies {
val sparkContext: SparkContext = self.sparkContext
val sqlContext: SQLContext = self
def numPartitions = self.numShufflePartitions //partitions的个数
val strategies: Seq[Strategy] = //策略的集合
CommandStrategy(self) ::
TakeOrdered ::
PartialAggregation ::
LeftSemiJoin ::
HashJoin ::
InMemoryScans ::
ParquetOperations ::
BasicOperators ::
CartesianProduct ::
BroadcastNestedLoopJoin :: Nil
etc......
}
下载后可阅读完整内容,剩余9页未读,立即下载
2021-01-30 上传
2021-03-03 上传
2024-09-13 上传
2024-09-13 上传
2024-09-13 上传

weixin_38612304
- 粉丝: 4
- 资源: 924
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
