C++实现数据结构:特殊线性表——栈、队列与串
需积分: 9 28 浏览量
更新于2024-08-02
收藏 1.62MB DOC 举报
"这是一份关于数据结构的C++版电子笔记,主要讲解了特殊线性表中的栈、队列和串的概念与实现。笔记详细介绍了栈的逻辑结构、抽象数据类型定义以及顺序存储结构,同时也探讨了两栈共享空间的问题及其解决方案。"
在数据结构的学习中,栈是一种基础且重要的数据结构,它被称为“后进先出”(LIFO)的数据组织形式。栈的定义是仅允许在表的一端,即栈顶进行插入和删除操作的线性表。栈的另一端称为栈底,当栈中没有元素时,我们称之为空栈。栈的操作通常包括初始化、销毁、入栈(Push)、出栈(Pop)、查看栈顶元素(GetTop)和判断栈是否为空(Empty)。
在C++中,我们可以使用抽象数据类型(ADT)来定义栈,其基本操作包括:
- InitStack():用于初始化一个空栈,确保栈不存在时可以安全地创建。
- DestroyStack():销毁已存在的栈,释放其所占用的内存空间。
- Push():在栈顶插入元素,如果操作失败,应抛出异常。
- Pop():删除栈顶元素,成功则返回被删除元素的值,失败同样抛出异常。
- GetTop():读取栈顶元素,栈不空时返回栈顶元素值,栈空时不做任何操作。
- Empty():检查栈是否为空,返回1表示空栈,0表示非空栈。
栈的顺序存储结构,也叫顺序栈,是通过数组来实现的。例如,我们可以定义一个模板类SeqStack,利用C++的模板机制,适用于各种数据类型。数组的大小可以根据实际需求动态调整,例如常量StackSize可以设置为10或100。
在某些场景下,可能需要在一个程序中同时使用两个栈。一种解决方案是为每个栈分配独立的数组空间,但这样会浪费存储空间。另一种更为节省空间的方案是使用一个共享数组,让两个栈分别从数组的两端开始增长,直到它们在中间相遇。这种方法要求预先确定数组的大小,以确保两个栈的容量需求总和不超过这个大小。
在实际应用中,栈常用于表达式求解(如括号匹配)、函数调用堆栈、深度优先搜索(DFS)等。掌握栈的基本概念和操作,以及其在不同场景下的应用,对于理解和解决复杂问题至关重要。通过深入学习和实践,我们可以更好地利用栈这一数据结构来优化算法和提高代码效率。
第 3 章 特殊线性表——栈、队列和串 2
};
3. 两栈共享空间
提出问题:在一个程序中如果需要同时使用具有相同数据类型的两个栈时,如何处理呢?
解决方案一:为每个栈开辟一个数组空间;
解决方案二:使用一个数组来存储两个栈,让一个栈的栈底为该数组的始端,另一个栈的栈底为该
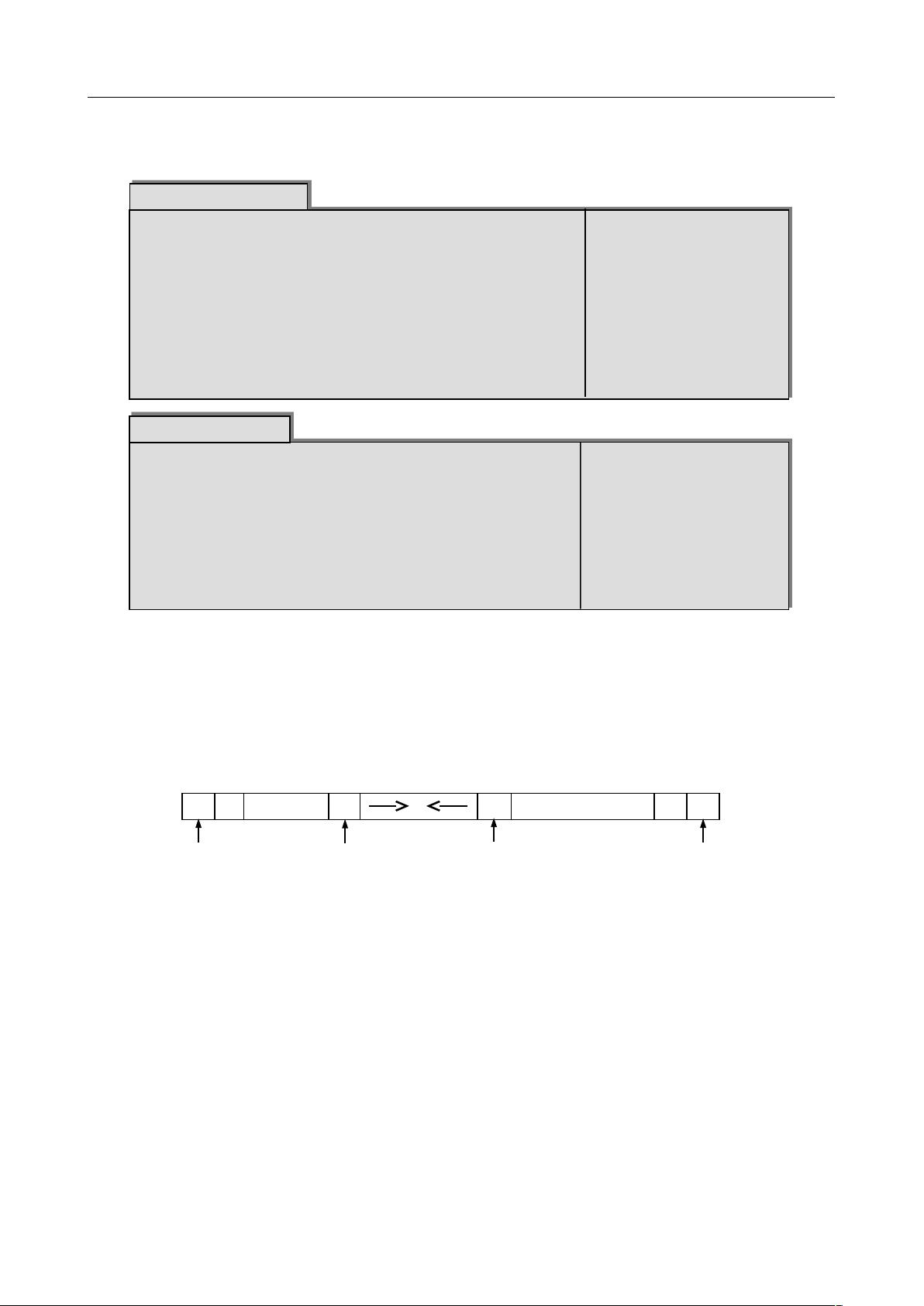
数组的末端,每个栈从各自的端点向中间延伸,如图 3-3 所示。
其中,top1 和 top2 分别为栈 1 和栈 2 的栈顶指针,StackSize 为整个数组空间的大小,栈 1 的底固定
在下标为 0 的一端;栈 2 的底固定在下标为 StackSize-1 的一端。
const int StackSize=100; //100 只是示例数据,需根据具体问题定义
template <class T>
class BothStack
{
public:
下标: 0 1 i-1
a
1
a
2
…… a
i
b
j
…… b
2
b
1
栈 1 底 top1 top2 栈 2 底
StackSize-1
template <class T> 札记:
void SeqStack::Push(T x)
{
}
顺序栈入栈算法 Push
template <class T> 札记:
T SeqStack:: Pop( )
{
}
顺序栈出栈算法 Pop
剩余14页未读,继续阅读
2010-12-28 上传
2023-08-23 上传
2023-08-31 上传
2023-07-29 上传
2024-03-23 上传
2023-11-01 上传
2024-01-29 上传

steven5210
- 粉丝: 5
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
