Python读取dbf文件UnicodeDecodeError解决方案(2021)
版权申诉
48 浏览量
更新于2024-08-26
收藏 143KB PDF 举报
在Python编程中,处理DBF(dBASE III)文件时常遇到UnicodeDecodeError的问题。DBF文件是早期数据库格式,存储的是ASCII编码的数据,但在使用Python处理这些文件时,由于默认编码可能与DBF文件的字符集不符,可能导致解码错误。本文档针对2021年的Python新手遇到的该问题,记录了三种不同的尝试方法和结果。
首先,尝试使用`dbfread`模块。作者最初导入DBF类并试图读取文件,但遇到UnicodeDecodeError,因为DBFread默认使用ASCII编码。通过设置`encoding`参数,作者尝试了`GBK`和`UTF-8`,但都未能解决问题。最终,通过设置`char_decode_errors='ignore'`,允许对无法解码的字符进行忽略,得以进入文件读取数据,但发现数据可能不准确,表明编码问题仍未完全解决。
其次,尝试了`dbfpy`模块,但似乎因为兼容性问题,与Python 2.x存在冲突,导致作者选择了放弃。这提示在选择DBF处理库时,需要考虑其对不同Python版本的支持情况。
最后,作者转向了`dbf`模块。这个模块是在网络上找到的,可能是作为其他方法失败后的替代方案。然而,文档并未详细说明在这个模块中的具体操作,只是暗示这种方法可能是解决UnicodeDecodeError的一个途径,但作者并未深入探究或成功解决。
总结来说,解决Python读取DBF文件时的UnicodeDecodeError问题的关键在于正确识别和设置文件的字符编码。对于新手来说,这可能涉及到对不同编码标准的理解以及对模块设置的细致调整。在选择处理库时,需要考虑库的兼容性和文档支持,同时可能需要根据实际情况试错,或者寻找更高级、更适应现代数据库处理的库,比如`pandas`配合`dbf4py`等。如果DBF文件的字符集未知,可能需要预处理或尝试多种编码来确定正确的解码方式。
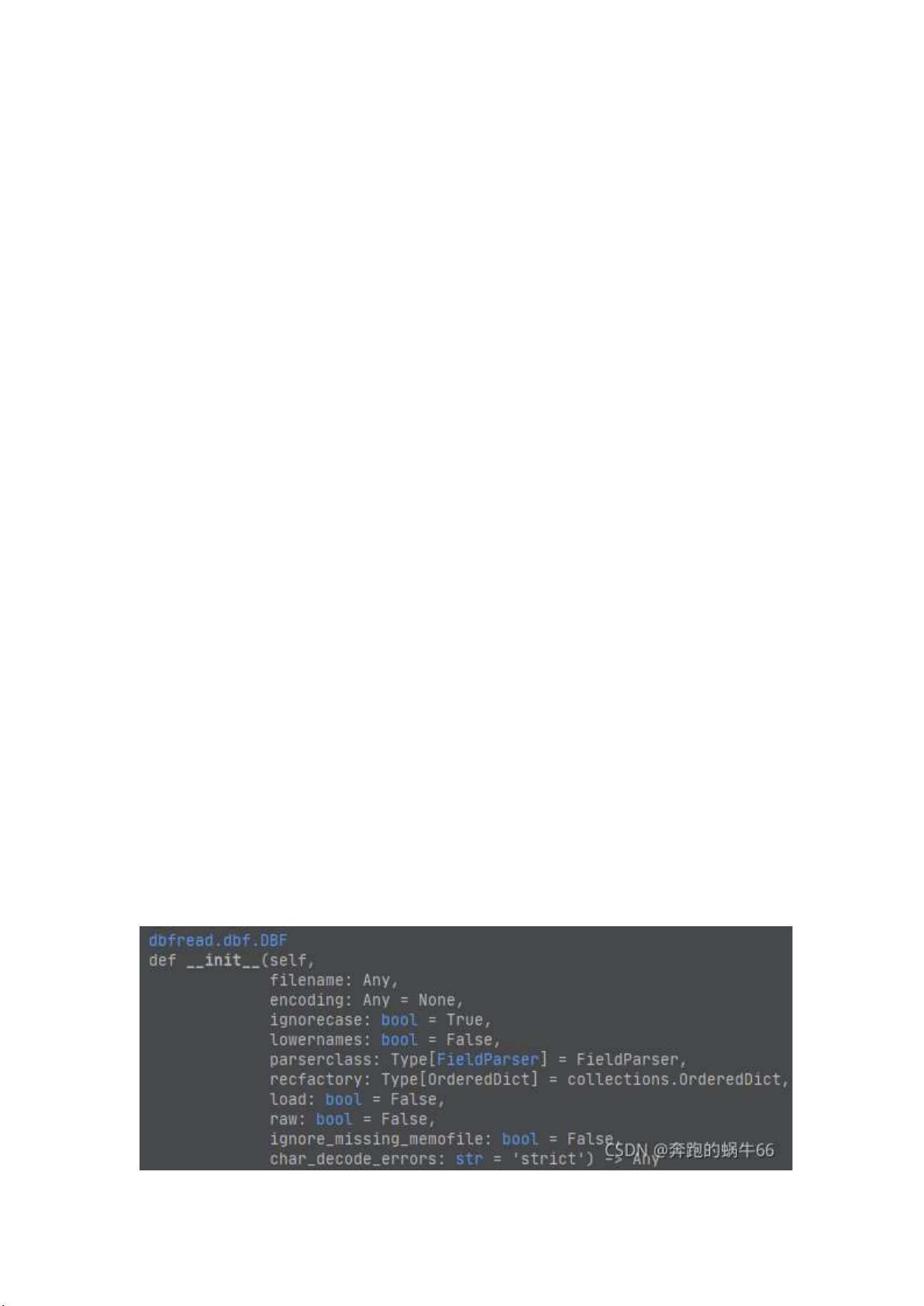
背景:本人 Python 新手,方法很低级,也不背后原理和机制,整好有个 dbf 文
件需要读取,尝试了很多方法模块(dbfread,dbfpy)等模块,出现了
UnicodeDecodeError,一直没有解决方法。最后用 dbf 模块打开了。
方法:
我看了一些帖子,最后瞎整了一番终于读取了,有几个方法总结
一下,我觉得可以分享,若说明不准确或有误,还请各位看到这篇破文的大侠
多多指导,不胜感激。
(1)先说 dbfread 模块
最开始我是这样干的
from dbfread import DBF
table = DBF('21-047.dbf',load=True)
list1=table.fields
list2=table.records
print(type(list1),len(list1))
print(type(list2),len(list2))
提示错误:UnicodeDecodeError: 'ascii' codec can't decode byte 0xd5 in
position 346: ordinal not in range(128)
我把 encoding 改成如:
table = DBF('21-047.dbf',load=True,encoding='gbk')
提示错误:UnicodeDecodeError: 'gbk' codec can't decode byte 0xcd in
position 265: incomplete multibyte sequence
后来改为 utf8 也不行......
最后我看了下 dbfread.dbf
下载后可阅读完整内容,剩余4页未读,立即下载
2010-04-06 上传
2018-10-17 上传
168 浏览量
2023-09-14 上传
2023-06-08 上传
2023-07-31 上传
2023-06-08 上传
2024-09-25 上传
2023-04-18 上传

一诺网络技术
- 粉丝: 0
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
