
Chinese Journal of Electronics
Vol.22, No.4 Oct. 2013
Parameterized Integrated Power and Performance
(PIPP) Model for Ultra High-Performance of
TOPS level DSP
∗
YANG Hui, CHEN Shuming and WU Tiebin
(School of Computer Science, National University of Defense Tec hnology, Changsha 410073, China)
Abstract — Amdahl’s law is a simple and fundamen-
tal tool for understanding the evolution of performance
as a function of parallelism. Following a recent trend on
timing and power analysis of general purpose many-core
chip using this law, we develop a nov el PIPP analytical
model for evaluating the performance and power of hier-
archical on-chip large-scale parallel architectures with the
core number, super-node size, processing element number,
and function unit number taken into consideration. We
thereby investigate the influence of workload characteris-
tics (Thread-level parallel TLP, Instruction-level parallel
ILP and Data-level parallel DLP) on resource allocation
with the restriction of p erformance and power. The re-
sults provide some feasible options to design TOPS level
DSP architecture as well as a theoretical basis for making
the design more scalable.
Key words — Hierarchical architecture, Data-level par-
allel (DLP), Thread-level parallel (TLP), Instruction-level
parallel (ILP), Model.
I. Introduction
DSPs are widely used in the embedded field. In order to
meet requirement of software radio
[1]
, DSP performance has
to reach up to 10TIPS by the year of 2020
[2,3]
. Therefore it is
urgent to build TOPS-level DSP on a single chip.
Hierarchical architectures combined of Very long instruc-
tion word (VLIW), Single instruction multiple data (SIMD),
tightly-coupled super-node, and multi-core technique, which
can fully develop the parallelism of applications with lower
hardware cost, has been broadly utilized in current DSPs
[2]
.
But power scales at a higher pace than the performance.
One of main objectives of a system designer is to assess the
impact of certain architecture choices on the variable to be op-
timized, from the highest levels of the design flow downwards.
There are two main strategies for current design methodolo-
gies: firstly, Instruction set simulations ISS and cycle-accurate
simulators
[4,5]
. However these methods are too detailed to
quickly explore the system-level design space. Secondly, ana-
lytical models. These are one approach to quickly identifying
advantageous architectures. But it is not detailed enough.
Hill and Marty introduced an analytical model for processor
performance and the number of cores in symmetric, asym-
metric, and dynamic multi-core chips
[6]
. Another approach
[7]
extended Hill and Marty’s model to include energy. Ge
[8,9]
proposed a power aware speedup model, which is intended to
provide a general form of parallel speedup model that supports
the emerging power aware architecture.
In contrast to all of these works, we present the Param-
eterized integrated power and performance (PIPP) analytical
model that jointly evaluates the tradeoffs between the core
number, super-node size, processing element number, func-
tion unit number, system performance, and power. We also
presented many first-hand experimental results to support
and validate the proposed model, and then explore the in-
fluence of workload characteristics (Thread-level parallel TLP,
Instruction-level parallel ILP and Data-level parallel DLP) on
resource allocation with the restriction of the performance and
power.
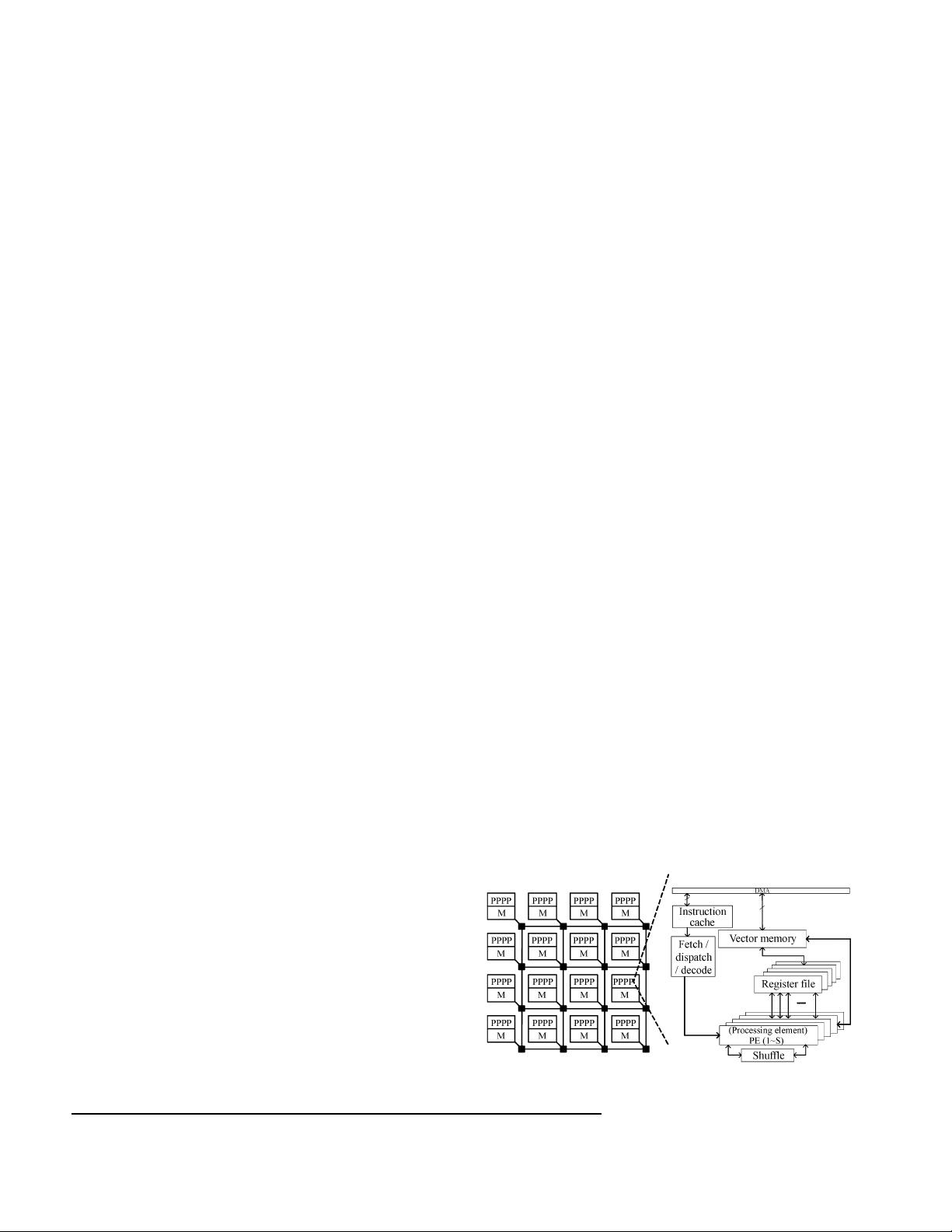
II. System Abstraction
Using Amdahl’s law as the basic analytical timing
model
[10]
, we try to predict the execution time. The abstract
parallel architecture is shown in Fig.1.
Fig. 1. Prototype hierarchical on-chip large-scale parallel ar-
chitectures
∗
Manuscript Received Mar. 2012; Accepted Jan. 2013. This work is supported by the National Natural Science Foundation of China
(No.61070036, No.61133007).
下载后可阅读完整内容,剩余4页未读,立即下载

weixin_38536576
- 粉丝: 6
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


