电信大数据分析:Spark在实时KPI与用户行为洞察中的应用
"杭州spark meetup PPT资料--2014-08-31,主要讨论了在电信场景下如何利用Spark构建一站式分析平台,涵盖了电信大数据的关键技术和具体应用案例。"
在2014年8月31日的杭州Spark Meetup活动中,演讲者夏命榛分享了电信行业中Spark技术的应用,构建了一个能够应对各种分析需求的一站式平台。该平台的核心在于利用Spark的强大处理能力,解决电信大数据的实时分析和存储问题。
在电信大数据场景中,一个关键的应用是实时KPI(关键性能指标)计算。当前的系统能够以15分钟的间隔生成KPI报表,但通过Spark可以优化这一过程,实现秒级甚至毫秒级的KPI更新,从而提高决策效率。此外,Spark还用于处理来自探针的实时上报事件,进行详单查询和仪表盘展示,满足从分钟到小时,再到天级的各类报表需求。
在数据模型方面,Spark处理的详单数据经过过滤生成,用于实时KPI计算和复杂事件处理(CEP)。这些数据模型支持对用户行为的快速响应,例如通过实时KPI报表优化服务。HDFS(Hadoop分布式文件系统)在数据入库和高性能实时流处理上面临挑战,而Spark作为更高效的计算框架,能够有效缓解这些问题。
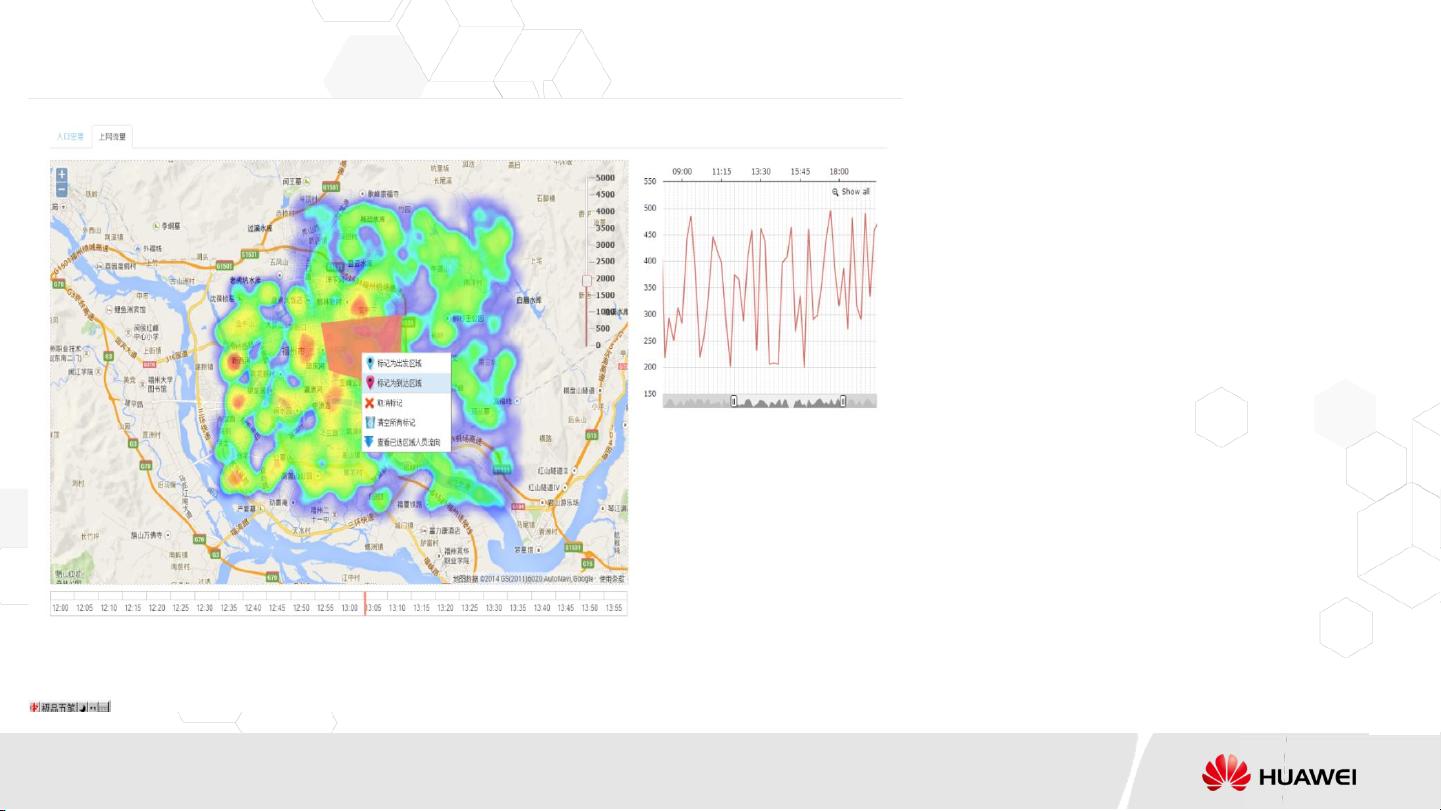
此外,平台展示了多种基于位置的应用。区域人数分布热力图和区域流量分布热力图提供了对人口流动和流量使用情况的深入洞察,有助于城市规划、广告策略制定和网络优化。通过用户相似度计算,可以进行个性化套餐推荐,提升运营商的销售业绩。这涉及到基于用户上网流量的协同推荐算法,以挖掘潜在的商业价值。
电信行业的核心数据资产包括用户ID、网络交互和移动位置,这些数据共同构成了用户的“数字足迹”。通过对这些数据的深度分析,可以构建用户、网络和社会的数字化映射,推动精准营销、道路规划、灾难救援、店铺选址等多个领域的创新应用。
在演示部分,数据显示每天有超过12亿条位置记录,对应80GB的数据量,这强调了大数据处理的规模和复杂性。通过Spark的实时监控和数据关联分析,可以实现对用户行为的深入洞察,进一步优化业务策略,促进电信行业的智能化和精细化管理。
HISILICON SEMICONDUCTOR
HUAWEI TECHNOLOGIES CO., LTD.
Page 6
Page 6
区域人数分布热力图直观的显示居住
区、 CBD 、旅游点、软件园等区域各时
段人数变化情况。 OD 图与算法(区域
间人口流动)与地图的结合,使用者可
自由指定感兴趣的区域 ,查询指定功能
区域间人口流动情况,如高档住宅区及
CBD 间的人口流动情况,为城市规划,
广告屏和店面选址等应用提供宏观参考
数据。
区域流量分布热力图直观的显示出区域
内用户对视频流量的使用,确定价值客
户挖掘区域范围,同时也为后继的网规
网优、路网规划、广告推广等提供宏观
参考数据。
用户相似度计算分析和对应的数据套餐
推荐:结合用户上网的流量使用信息,
挖掘出相似性用户,把用户使用套餐多
的选择推荐给其他相关类似用户,期望
扩大运营商的销售收入。(基于个性化
的协同推荐算法)
场景二:用户流量使用的关联分析
剩余27页未读,继续阅读
2014-09-12 上传
2018-12-27 上传
3222 浏览量
168 浏览量
2024-09-03 上传
131 浏览量
174 浏览量
222 浏览量

ibigdatas
- 粉丝: 4
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







