Spark MLlib项目流行度预测:操作指南与Zeppelin安装
需积分: 0 60 浏览量
更新于2024-08-05
收藏 535KB PDF 举报
"本实验是基于Spark MLlib的开源软件项目流行度预测,涉及Spark的安装、配置环境变量、Zeppelin的安装与配置,以及问题修复。实验旨在使用Spark进行大数据分析,预测软件项目的流行度。"
在进行大数据分析时,Spark是一个关键的工具,它提供了高效的数据处理能力。Spark的基本原理包括弹性分布式数据集(Resilient Distributed Datasets, RDD)、数据并行性和任务调度。RDD是Spark的核心概念,它是一个容错的、不可变的数据集,可以在集群中分布式存储。Spark通过RDD支持高效的批处理、交互式查询(例如,通过Spark SQL)以及流处理。
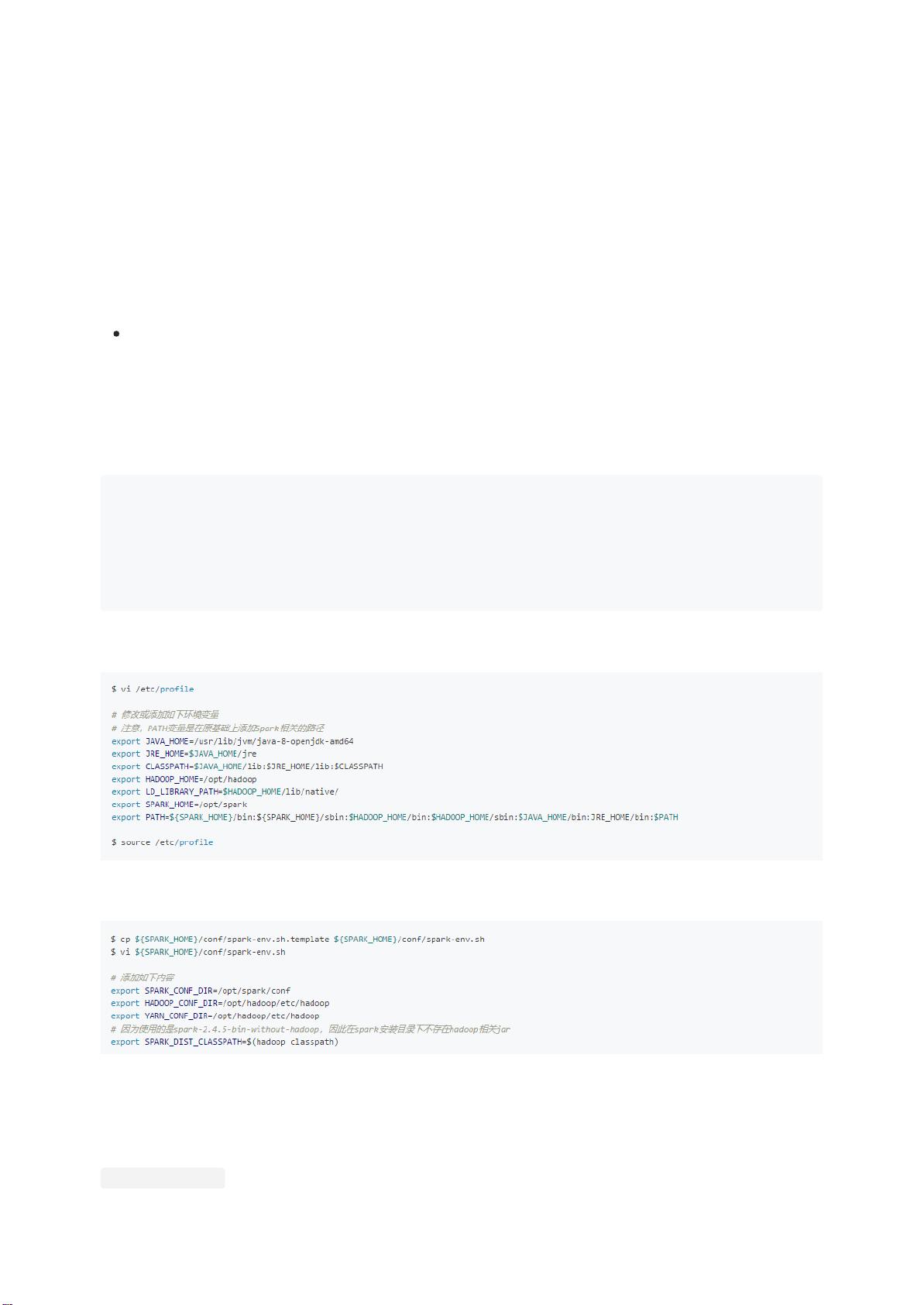
Spark的安装通常在Hadoop分布式集群环境中进行,特别是在YARN(Yet Another Resource Negotiator)模式下。在这种模式下,Spark应用作为客户端提交到YARN,由YARN负责集群资源的管理和调度。安装Spark时,只需在集群中的任意节点执行下载、解压和移动操作,无需在整个集群上安装。确保下载对应版本的Spark,例如Spark 2.4.5,并将其移动到指定目录,然后创建软链接以简化路径引用。
配置环境变量是运行Spark的关键步骤,需要设置`SPARK_HOME`指向Spark的安装目录,并将`PATH`变量添加到Spark的bin目录。此外,对于Spark on YARN模式,还需要配置`spark.yarn.jars`以指定公共JAR包的位置,这样可以避免每次提交任务时重复提交相同的库。
Apache Zeppelin是一款基于Web的交互式笔记本,支持SQL、Scala和其他语言,用于数据驱动的交互式数据分析和协作文档。在Zeppelin的安装过程中,需要下载对应版本的Zeppelin,如0.8.2,解压后移动到指定目录,并配置环境变量。安装完成后,Zeppelin可以在指定的主机上启动,提供可视化界面供用户编写和运行数据分析脚本。
在进行问题修复时,可能需要处理各种问题,如网络连接错误、依赖冲突或配置不正确等。这些问题可以通过检查日志、更新配置或重新安装解决。确保所有组件都能正常通信,并且所有必要的依赖都已经正确配置。
这个实验涵盖了Spark的基础部署和使用,以及与之配合的Zeppelin的安装,这些都是大数据分析和机器学习项目中常见的工作流程。通过这样的实践,参与者可以深入理解Spark的运行机制,以及如何利用Zeppelin进行交互式数据分析,为开源软件项目的流行度预测提供有效的工具和平台。
1.Spark基本原理
参见课程PPT
2.Spark安装配置(SparkonYARN模式)
安装主机:
bdcourse-0001
注意:SparkonYARN运行模式,只需要在Hadoop分布式集群中任选一个节点安装配置Spark即
可,不要集群安装。因为Spark应用程序提交到YARN后,YARN会负责集群资源的调度。
安装
$wgethttps://archive.apache.org/dist/spark/spark‐2.4.5/spark‐2.4.5‐bin‐without‐
hadoop.tgz
$tar‐zxvfspark‐2.4.5‐bin‐without‐hadoop.tgz
$mvspark‐2.4.5‐bin‐without‐hadoop/opt/
$ln‐s/opt/spark‐2.4.5‐bin‐without‐hadoop/opt/spark
配置环境变量
配置SparkonYARN模式
配置公共JAR包
Hadoop集群下提交任务时,会将jar包提交到HDFS上,为防止每次提交任务时都提交,所以在
HDFS上上传一份公共的(将spark安装包下的jars文件夹下的jar文件全部上传上去)。并配置
spark.yarn.jars 为该文件夹位置(如hdfs://bdcourse-0001:9000/spark/jars/*)
下载后可阅读完整内容,剩余6页未读,立即下载
2022-08-08 上传
2021-08-10 上传
2023-10-23 上传
2023-06-06 上传
2023-06-07 上传
2023-06-06 上传
2023-12-15 上传
2024-06-26 上传
2023-06-06 上传

设计师马丁
- 粉丝: 21
- 资源: 299
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
