Hadoop MapReduce:大数据并行处理模型解析
132 浏览量
更新于2024-08-28
1
收藏 1.3MB PDF 举报
"Hadoop MapReduce是一种用于大规模数据集处理的并行编程模型,它将复杂的分布式计算过程简化为两个主要步骤:map和reduce。MapReduce的设计目标是处理和存储海量数据,尤其适合于大数据环境中的批处理任务。"
在MapReduce模型中,map阶段是数据处理的起点。数据首先被分割成多个块,并分配到集群的不同节点上。每个map任务接收这些数据块,并对其中的每一行或每个记录进行独立处理。在这个过程中,开发者定义的map函数将原始数据转化为中间键值对的形式。例如,在天气数据的案例中,map函数可以从每条观测记录中提取年份和温度,生成(年份,温度)的键值对。
接下来,MapReduce框架会对所有map任务的输出进行排序和分区,这个过程被称为shuffle。在shuffle阶段,具有相同key的键值对会被分到同一个reduce任务中,这样可以确保所有与特定key相关的数据都会被同一reduce实例处理。在天气数据的例子中,这意味着所有同一年份的温度数据会被分组在一起。
reduce阶段是MapReduce流程的关键环节。reduce函数负责对分组后的数据进行聚合操作,如求和、最大值或最小值等。在找出历年最高气温的例子中,reduce任务会接收所有属于同一年份的温度列表,找出并返回每个年份的最大温度。
MapReduce的这种工作模式允许任务并行化,极大地提高了处理效率。在实际应用中,map和reduce任务可以跨多台机器执行,使得计算能力随着硬件资源的增加而扩展。例如,如果有一组天气数据分布在多个文件中,MapReduce会自动将任务拆分,并根据集群的资源情况将任务分配给不同的节点执行。
在上述示例中,假设有一个包含5年天气数据的集群,数据分散在3个文件里,集群由3台机器组成,设有3个map任务和2个reduce任务。MapReduce框架会自动决定哪个map任务处理哪个数据块,然后将map的输出通过网络传输给reduce任务。值得注意的是,数据可能会跨越文件和机器,因此reduce任务可能需要处理来自不同map任务的数据,这就是shuffle阶段的作用。
Hadoop MapReduce提供了一种强大的工具,使开发者能够方便地处理大规模数据集,而不必关心底层的分布式计算细节。通过定义map和reduce函数,开发者可以专注于业务逻辑,而Hadoop则负责处理数据的分布、并行处理和结果聚合。这种模型已经广泛应用于各种大数据场景,如搜索引擎索引构建、数据分析、日志处理等。
HadoopMapReduce原理及实例原理及实例
MapReduce是用于数据处理的一种编程模型,简单但足够强大,专门为并行处理大数据而设计。
1. 通俗理解MapReduce
MapReduce的处理过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自
行指定。map阶段对切分好的数据进行并行处理,处理结果传输给reduce,由reduce函数完成最后的汇总。
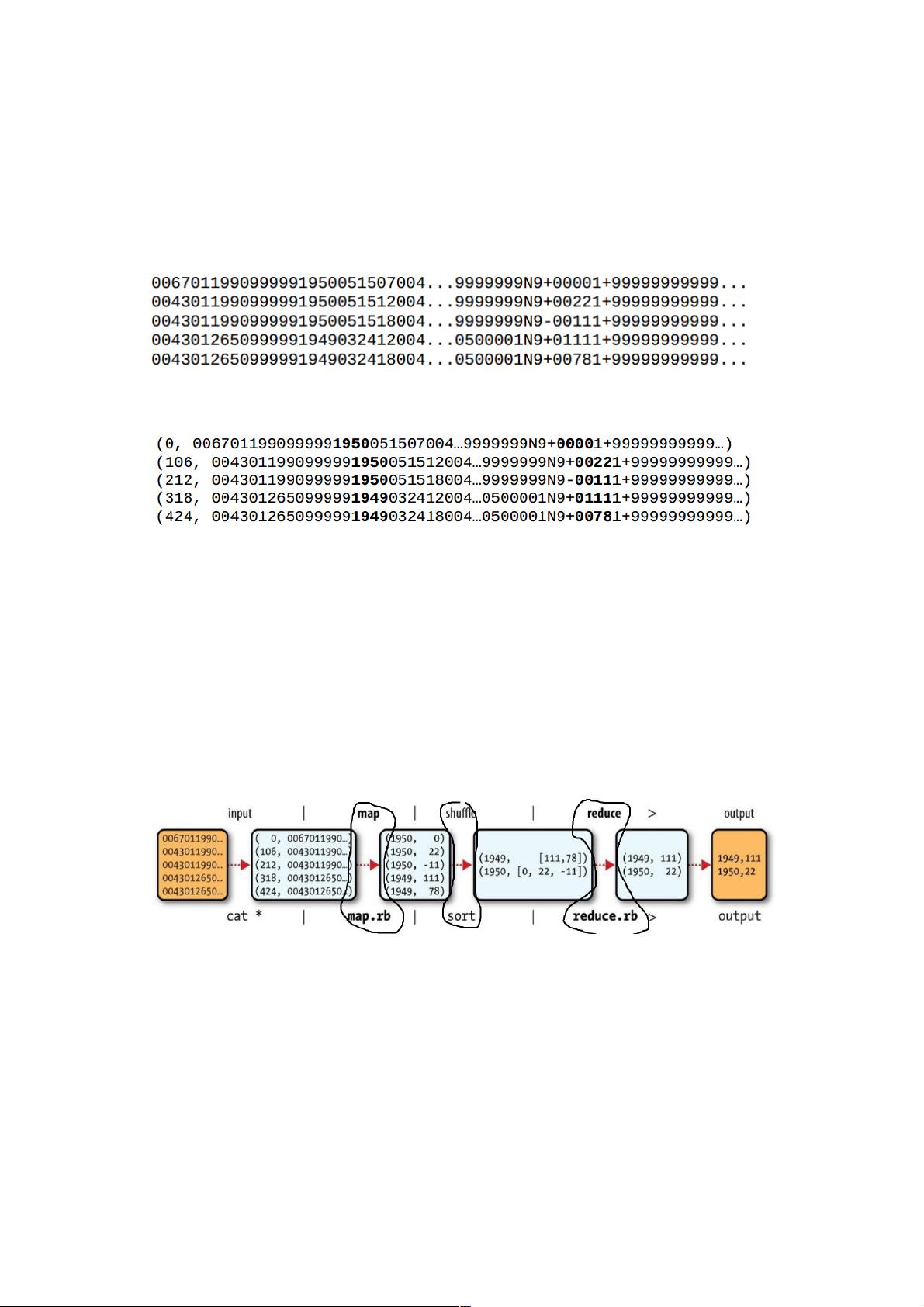
例如从大量历史数据中找出往年最高气温,NCDC公开了过去每一年的所有气温等天气数据的检测,每一行记录一条观测记
录,格式如下:
为了使用MapReduce找出历史上每年的最高温度,我们将行数作为map输入的key,每一行的文本作为map输入的value:
上图中粗体部分分别表示年份和温度。map函数对每一行记录进行处理,提取出(年份,温度)形式的键值对,作为map的输
出:
很明显,有些数据是脏的,因此map也是进行脏数据处理和过滤的好地方。在map输出被传输到reduce之前,MapReduce框
架会对键值对进行排序,根据key进行分组,甚至在key相同的一组内先统计出最高气温,所以reduce收到的数据格式像这
样:
如果有多个map任务同时运行(通常都是这样),那么每个map任务完成后,都会向reduce发送上面格式的数据,发送数据的
过程叫shuffle。
map的输出会作为reduce的输入,reduce收到的是key加上一个列表,然后对这个列表进行处理,天气数据的例子中,就是找
出最大值作为最高气温。最后reduce输出即为每年最高气温:
整个MapReduce数据流如下图:
其中的3个黑圈圈分别为map,shuffle和reduce过程。在Hadoop中,map和reduce的操作可以由多种语言来编写,例如
Java、Python、Ruby等。
在实际的分布式计算中,上述过程由整个集群协调完成,我们假设现在有5年(2011-2015)的天气数据,分布存放在3个文件
中: weather1.txt,weather2.txt,weather3.txt。再假设我们现在有一个3台机器的集群,b并且map任务实例数量为3,reduce
实例数量2。那么实际运行MapReduce做作业时,整个流程类似于这样:
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-10 上传
2021-06-04 上传
2021-05-08 上传
点击了解资源详情
2024-12-22 上传

weixin_38701312
- 粉丝: 8
- 资源: 947
 我的内容管理
展开
我的内容管理
展开







最新资源
- LaraminLTE:带有 adminLTE 模板的 Laravel
- Eclipse Java Project Creation Customizer-开源
- 尼古拉斯-tsioutsiopoulos-itdev182
- 管理系统系列--运用SSM写的停车场管理系统,加入了车牌识别和数据分析.zip
- datasets:与学术中心上托管数据集相关的文档
- userChromeJS:Firefox 用户 ChromeJS 脚本
- Mini51 单片机开发板资料汇总(原理图+PCB源文件+CPLD方案等)-电路方案
- python实例-08 抖音表白.zip源码python项目实例源码打包下载
- node-learning
- 各种清单
- 【采集web数据Python实现】附
- Android谷歌Google Talk网络会话演示源代码
- goit-markup-hw-07
- 管理系统系列--游戏运营管理系统SpringMVC.zip
- 【转】Mini51精简版数字示波器原理图、源码+模拟信号调理电路-电路方案
- Python库 | ephysiopy-1.5.94.tar.gz
