
4 Chapter 1. Why should you learn to write programs?
While most of the detail of how thes e components work is best left to computer
builders, it helps to have some terminology so we can talk about these different
parts as we write our programs.
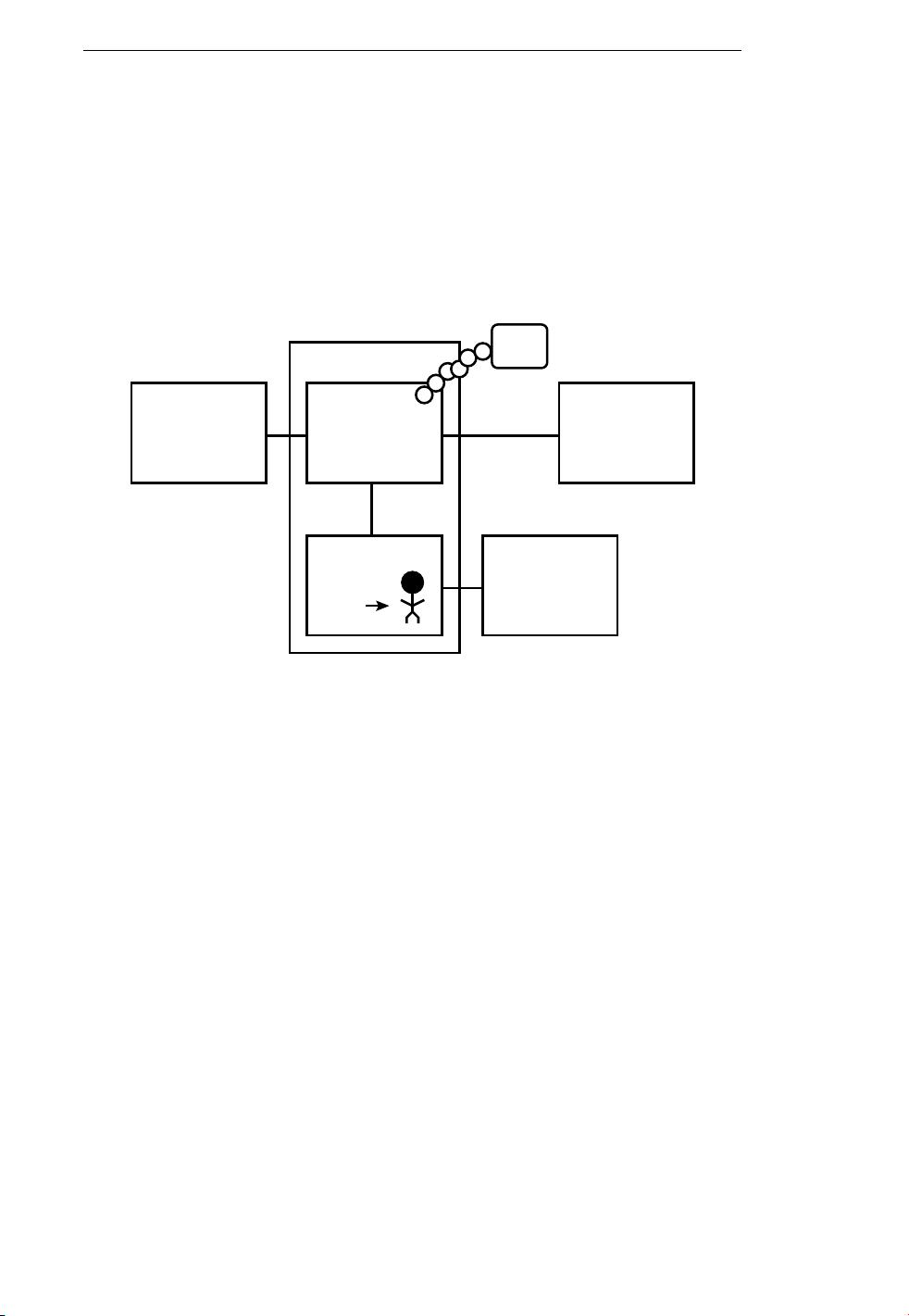
As a programmer, your job is to use and orchestrate each of these resources to
solve the problem that you need to solve and analyze the data you get from the
solution. As a programmer you will mostly be “talking” to the CPU and telling
it what to do next. Sometimes you will tell the CPU to use the main memory,
secondary memory, network, or the input/output devices.
You
Input
Software
Output
Devices
What
Next?
Central
Processing
Unit
Main
Memory
Secondary
Memory
Network
You need to be the person who answers the CPU’s “What next?” question. But it
would be very uncomfortable to shrink you down to 5mm tall and inser t you into
the computer just so you could issue a command three billion times per second. So
instead, you must write down your instructions in advance. We call these stored
instructions a program and the act of writing these instructions down and getting
the instructions to be correct programming.
1.3 Understanding programming
In the rest of this book, we will try to turn you into a person who is skilled
in the art of progr amming. In the end you will be a programmer — perhaps
not a professional programmer, but at least you will have the skills to look at a
data/information analysis problem and develop a program to solve the problem.
In a sense, you need two skills to be a programmer:
• First, you need to know the programming language (Python) - you need
to know the vocabulary and the grammar. You need to be able to spell
the words in this new language properly and know how to construct well-
formed “sentences” in this new language.




剩余243页未读,继续阅读

卖女孩的小滑稽
- 粉丝: 2
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- WebLogic集群配置与管理实战指南
- AIX5.3上安装Weblogic 9.2详细步骤
- 面向对象编程模拟试题详解与解析
- Flex+FMS2.0中文教程:开发流媒体应用的实践指南
- PID调节深入解析:从入门到精通
- 数字水印技术:保护版权的新防线
- 8位数码管显示24小时制数字电子钟程序设计
- Mhdd免费版详细使用教程:硬盘检测与坏道屏蔽
- 操作系统期末复习指南:进程、线程与系统调用详解
- Cognos8性能优化指南:软件参数与报表设计调优
- Cognos8开发入门:从Transformer到ReportStudio
- Cisco 6509交换机配置全面指南
- C#入门:XML基础教程与实例解析
- Matlab振动分析详解:从单自由度到6自由度模型
- Eclipse JDT中的ASTParser详解与核心类介绍
- Java程序员必备资源网站大全
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


