操作系统存储器管理:从装入链接到虚拟存储
版权申诉
161 浏览量
更新于2024-07-03
收藏 3.81MB PPT 举报
"操作系统课件:Chapter-04存储器管理.ppt"
在计算机科学中,存储器管理是操作系统的核心功能之一,它涉及到程序如何在内存中有效地存储和访问。本课件主要涵盖了存储器管理的多个重要方面,包括程序的装入和链接,以及多种存储分配策略。
首先,我们讨论程序的装入和链接。装入是将编译后的程序加载到内存的过程,而链接则是将多个目标模块组合成一个可执行文件的过程。课程中提到了三种装入方式:
1. 绝对装入方式:程序按照其在编译时确定的地址直接装入内存,程序中的逻辑地址与物理地址一致,无需进一步的地址转换。
2. 可重定位装入方式:程序装入时,所有逻辑地址都会根据其在内存的实际位置进行调整,即重定位。这种调整一次性完成,且在程序运行期间不再改变。
3. 动态运行时装入方式:在程序运行时才进行地址转换,允许程序在内存的任意位置装入,提供了更大的灵活性。
接下来,课件介绍了几种存储分配方式:
1. 连续分配方式:包括单一连续分配(所有程序都在一个连续区域)、固定分区分配(预先划分固定的内存区域)和动态分区分配(根据程序大小动态创建分区)。
2. 分页存储管理方式:将内存划分为固定大小的页,同时将程序分割为同样大小的页框。这种方式可以有效解决内部碎片问题,但可能产生外部碎片。
3. 分段存储管理方式:以逻辑段为单位分配内存,每个段代表程序的一个逻辑部分,如数据结构或函数。这种方式更适合于多道程序设计,但可能导致外部碎片。
4. 虚拟存储器:通过结合主存和辅存,使得程序可以使用超过实际主存容量的地址空间。虚拟存储器的关键在于页替换算法,例如LRU(最近最少使用)、FIFO(先进先出)等,它们决定了何时将哪些页面从主存交换到辅存。
5. 请求分页和分段存储管理:在虚拟存储器基础上,只有当程序真正需要某部分代码或数据时,才将其调入主存。这样减少了对主存的需求,提高了系统效率。
存储器的分级结构是现代计算机系统中常见的设计,由高速缓存、主存和磁盘等组成,以提供不同速度和容量的存储层次,优化性能和成本。
这节课件详细讲解了存储器管理的多个关键概念,对于理解操作系统如何管理和优化内存资源具有重要意义。学习这些知识有助于我们更好地设计和分析高效的计算机系统。
11
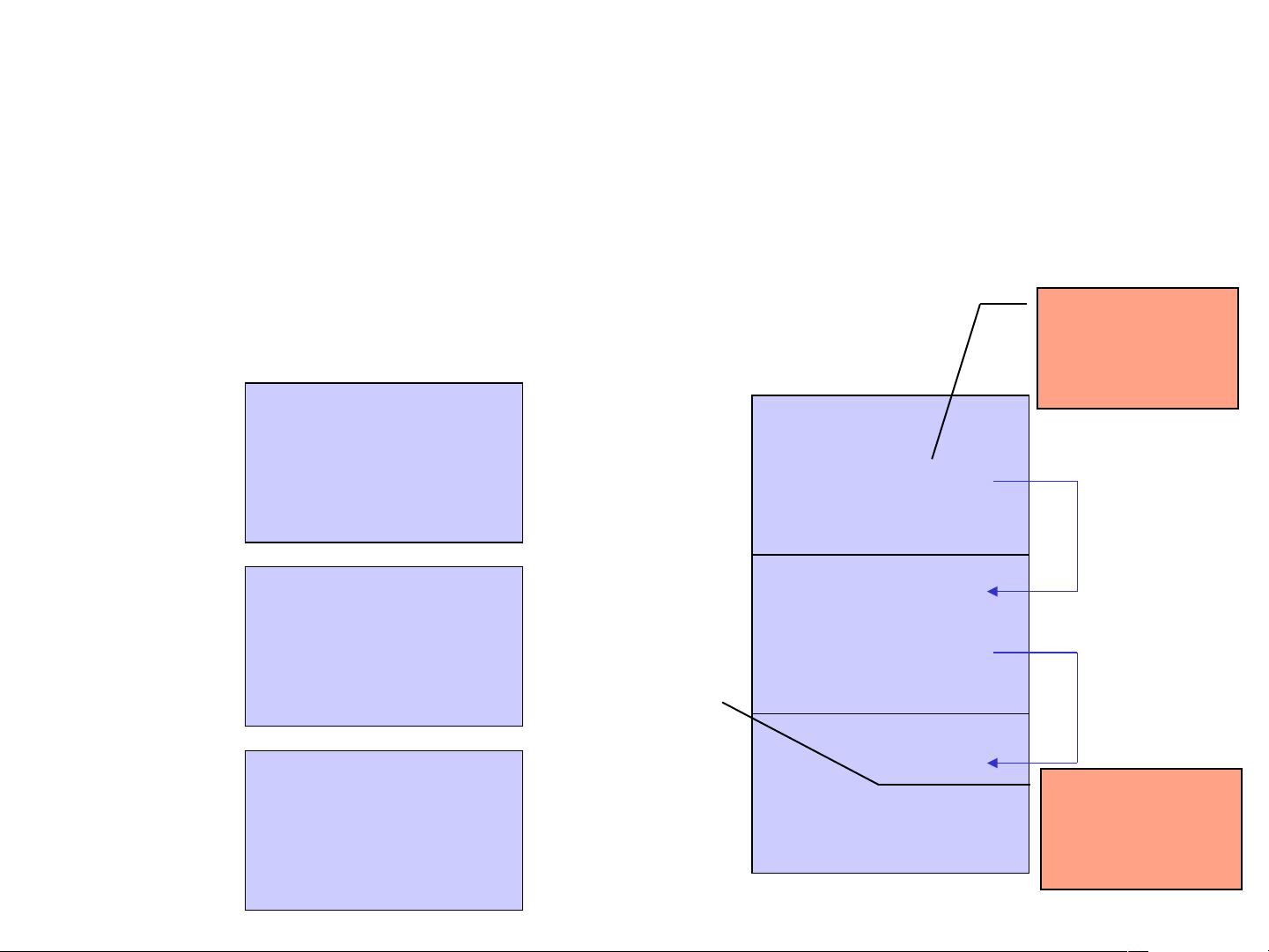
程序的装入与链接( 9 )
•
程序的链接
–
1. 静态链接方式 (Static Linking)
模块 A
CALL B;
Return;
模块 B
CALL C;
Return;
模块 C
Return;
0
0
0
L-1
M-1
N-1
模块 A
JSR’L’;
Return;
模块 B
JSR’L+M’;
Return;
模块 C
Return;
0
L-1
L
L+M-1
L+M
L+M+N-1
变换外部
调用符号
相对地址
发生变化


剩余63页未读,继续阅读
2022-06-17 上传
2022-06-09 上传
2022-06-09 上传
2024-10-29 上传
2024-09-11 上传
154 浏览量
409 浏览量
117 浏览量
140 浏览量

智慧安全方案
- 粉丝: 3845
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 英语常用3500词音频+PDF文件(含音频).zip
- 老板计时器
- Honey Boo Boo的算法和功能分解
- ember-addon-config
- 1.8wUA库.zip
- reading-notes:在这里您可以找到我的阅读资料库,主要用于总结我在编程方面的学习历程,希望您能找到一些有用的信息<3
- 视频播放可弹出弹幕,关闭弹幕
- simple-spawner:生成一个命令并将输出通过管道返回到 std{in,out,err}
- CSS_Assignment_2
- 使用注释将JDBC结果集映射到对象
- curious-blindas-api:CuriousCat克隆
- PRO-C21-BULLETS-AND-WALLS
- ff35mm:Flickr 的全画幅 (35mm) 焦距
- C#解析HL7消息的库
- 将Java System.out定向到文件和控制台的快速简便方法
- 库索逻辑-葡萄牙语
