"藏经阁-LEARNINGS USING SPARK STREAMING.pdf"是一份由阿里云的专家Yan Zheng和Nirmal Sharma共同撰写的文档,重点关注在沃尔玛搜索服务中如何利用Apache Spark Streaming进行实时数据分析以提升效率。随着产品目录、价格、库存等数据的快速增长,原有的搜索架构已经无法满足实时性和用户体验的需求。这份报告详细介绍了以下几个关键知识点:
1. 业务需求的增长:
- 随着时间推移,沃尔玛的产品目录、更新频率都在显著增加,这要求搜索引擎能实时处理大量的实时数据,如商品信息、价格变化和库存状态。
- 数据量的爆炸性增长(从TB级别)促使实时分析变得至关重要,以便快速做出商业决策。
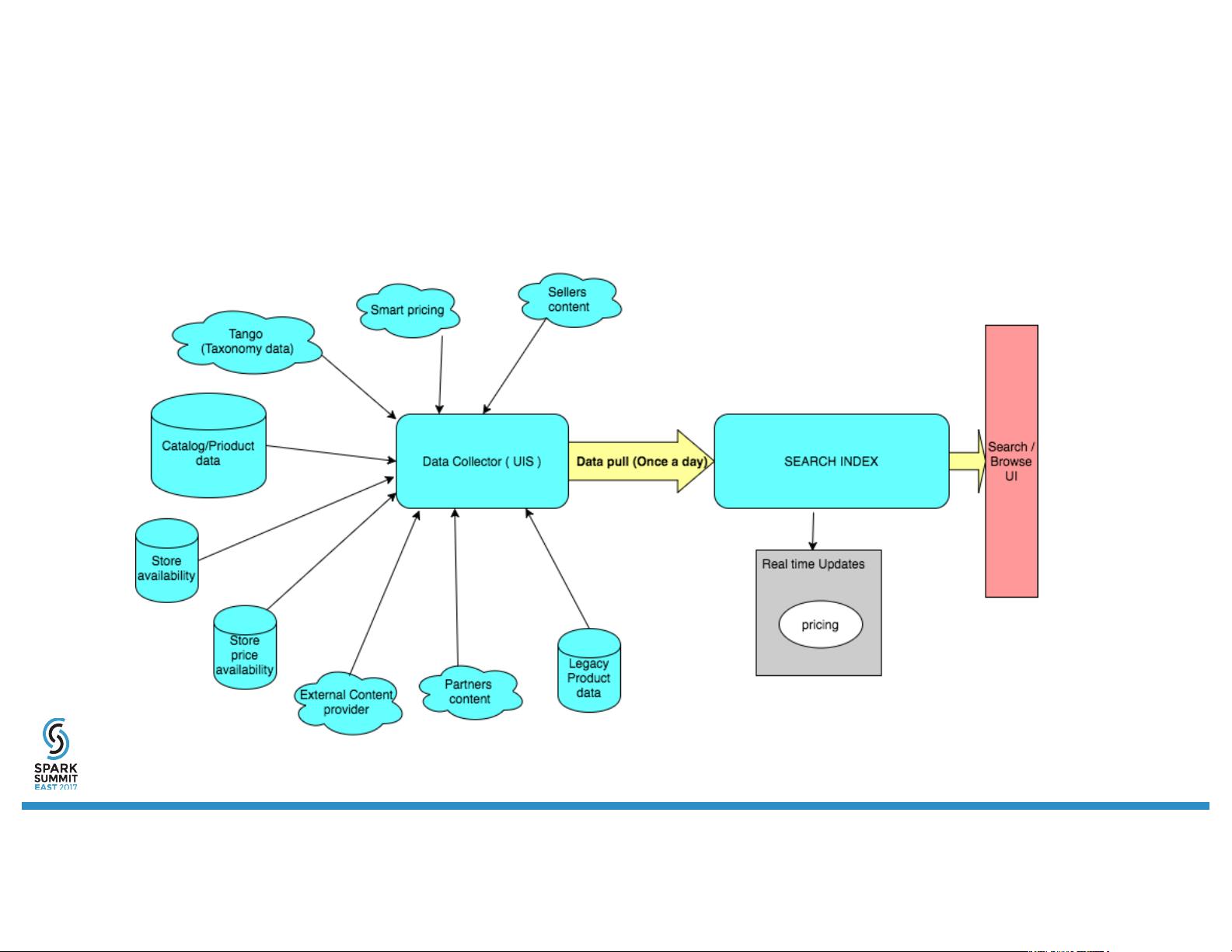
2. 旧搜索架构的问题:
- 在过去的架构中,索引更新每天仅进行一次,导致用户在搜索时可能面临延迟,严重影响了整体的用户体验和业务效果。
3. 新架构的引入:
- 阿里云团队采用了一种新的策略,通过将所有产品目录更新捕获到Kafka消息队列中,然后使用Spark Streaming进行实时处理,能够每秒处理高达10,000个事件。这极大地提高了数据处理速度和响应能力。
4. 技术实施细节:
- 实现过程中,他们利用Spark Streaming的流处理能力,将实时事件转换成可以更新搜索索引的数据,从而保证了搜索结果的即时准确性和个性化。
5. 效益提升:
- 新架构的引入不仅解决了旧架构的延迟问题,还支持了更多的功能和业务场景,提升了搜索的相关性信号,从而优化了用户体验,有助于推动业务发展。
通过这份学习资料,读者可以了解到如何在大规模数据处理背景下,利用Spark Streaming进行高效实时分析,并在实际商业环境中实现性能和用户体验的双重提升。这对于任何寻求在快速变化的市场环境中进行实时数据分析的组织都具有重要的参考价值。