Cassandra分布式模型详解与源码洞察
需积分: 0 10 浏览量
更新于2024-07-31
收藏 1.77MB DOCX 举报
Cassandra分布式模型与源代码分析深入探讨了这个高效且灵活的NoSQL数据库系统。Cassandra由Facebook开发并广泛应用于如Twitter、Facebook这样的大型企业,用于处理海量数据。其核心特点是分布式、基于列的结构化存储和高伸缩性。
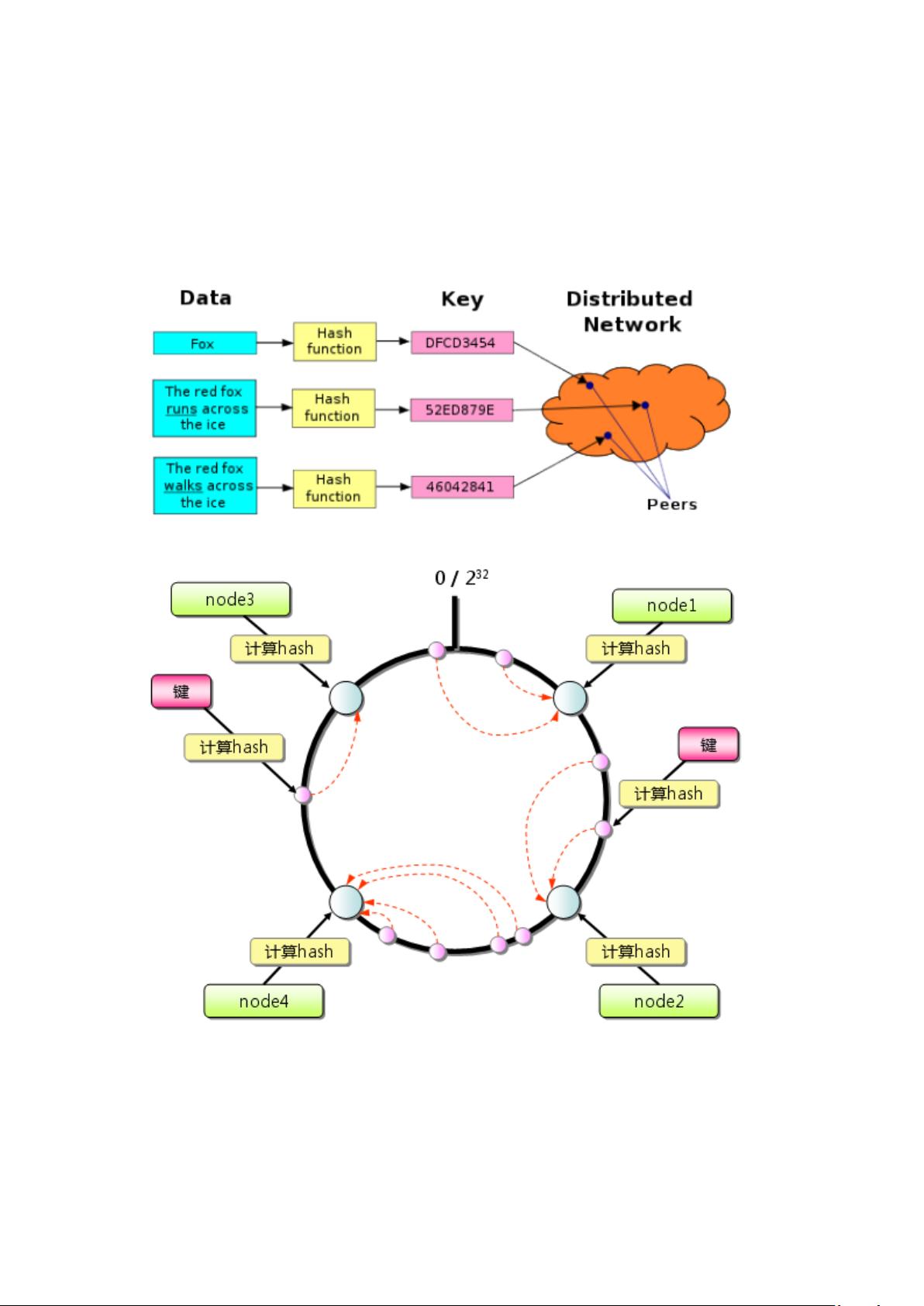
首先,Cassandra的分布式模型是其关键优势之一。它采用了一种分布式网络服务架构,数据被分散存储在多个节点上,通过一致性哈希算法实现数据的负载均衡和故障容错。每个写入操作不仅写入主节点,还会复制到其他节点,确保冗余备份,而读取则通过节点间的路由机制找到相应的数据。这种设计使得Cassandra能够避免单点故障,提升系统的可靠性。
其次,Cassandra的灵活性体现在其schema设计上。它支持on-the-fly schema变更,即用户无需在创建表之前预设固定的字段,可以根据实际需求动态添加或删除,这极大地方便了开发者和数据模型的管理。
高可用性和可扩展性也是Cassandra的重要特性。当需要增加存储容量时,只需要向集群中添加新节点,无需停机或改变应用程序。这种纯粹的水平扩展方式允许Cassandra轻松应对不断增长的数据量,同时保证服务的连续性。
Cassandra还支持范围查询,这对于处理时间序列数据或者地理位置信息尤其有用,只需设置特定的键范围,即可获取相关的数据集合。此外,它提供了列表数据结构,能够在混合模式下处理复杂的多维度数据,例如将超级列添加到四维或五维的Hash中。
源代码分析方面,Cassandra的设计注重一致性与分区容错,它的Paxos和Raft协议在确保分布式一致性的同时,也实现了高效的节点间通信和数据同步。Cassandra的核心组件包括 SSTable、Memtable、Ring gossip 等,这些都反映在源码中,为理解和优化其性能提供了重要的依据。
应用层面上,Cassandra常用于存储和查询大规模、实时更新的数据,比如日志、用户行为数据、社交网络数据等。其分布式特性和高效的数据模型使得Cassandra在处理大规模数据挑战时表现出色。
Cassandra分布式模型的精髓在于其分布式网络服务、灵活的schema、范围查询能力以及高度的可扩展性,这些特性使其成为现代大数据场景中的重要选择。源代码分析则有助于深入理解其内部工作机制,以优化部署和使用效果。

2.8.5.7Existing Cluster (Upgrade from 0.6)
To provide some backwards compatibility, we've provided a JMX method in
the StorageServiceMBean that can be used to manually load schema definitions
from storage-conf.xml. This is a one-shot operation though, and will only work
on a system that contains no existing migrations. If you are upgrading a cluster,
you will probably only have to do this for one node (a seed). Gossip will take
care of promulgating the changes to the rest of the nodes as they come online.
For those who dont know how to do it (like me):
ps aux | grep cassandra # get pid of cassandra
jconsole PID
MBeans -> org.apache.cassandra.service -> StorageService -> Operations ->
loadSchemaFromYAML
2.8.5.8Concurrency
It is entirely possible and expected that a node will receive migration pushes
from multiple nodes. Because of this, all migrations are applied on a
single-threaded stage and versions are checked throughout to make sure that
no migration is applied twice, and no migration is applied out of sync.
Each migration knows the version UUID of the migration that immediately
precedes it. If a node is asked to apply a migration and its current version
UUID does not match the last version UUID of the migration, the migration is
discarded.
One weakness of this model is that it is vulnerable if a new update starts
before another update is promulgated to all live nodes--only one migration can
be active within a cluster at any time. One way to get around this is to choose
one node and only initiate migrations through it.



剩余100页未读,继续阅读
2023-06-11 上传
2023-05-24 上传
2023-05-17 上传
2023-03-20 上传
2023-06-08 上传
2023-06-11 上传
2023-07-11 上传
2023-05-05 上传
2023-03-30 上传

sxz20041919
- 粉丝: 3
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 明日知道社区问答系统设计与实现-SSM框架java源码分享
- Unity3D粒子特效包:闪电效果体验报告
- Windows64位Python3.7安装Twisted库指南
- HTMLJS应用程序:多词典阿拉伯语词根检索
- 光纤通信课后习题答案解析及文件资源
- swdogen: 自动扫描源码生成 Swagger 文档的工具
- GD32F10系列芯片Keil IDE下载算法配置指南
- C++实现Emscripten版本的3D俄罗斯方块游戏
- 期末复习必备:全面数据结构课件资料
- WordPress媒体占位符插件:优化开发中的图像占位体验
- 完整扑克牌资源集-55张图片压缩包下载
- 开发轻量级时事通讯活动管理RESTful应用程序
- 长城特固618对讲机写频软件使用指南
- Memry粤语学习工具:开源应用助力记忆提升
- JMC 8.0.0版本发布,支持JDK 1.8及64位系统
- Python看图猜成语游戏源码发布
