

Multi-Agent Actor-Critic for Mixed
Cooperative-Competitive Environments
Ryan Lowe
∗
McGill University
OpenAI
Yi Wu
∗
UC Berkeley
Aviv Tamar
UC Berkeley
Jean Harb
McGill University
OpenAI
Pieter Abbeel
UC Berkeley
OpenAI
Igor Mordatch
OpenAI
Abstract
We explore deep reinforcement learning methods for multi-agent domains. We
begin by analyzing the difficulty of traditional algorithms in the multi-agent case:
Q-learning is challenged by an inherent non-stationarity of the environment, while
policy gradient suffers from a variance that increases as the number of agents grows.
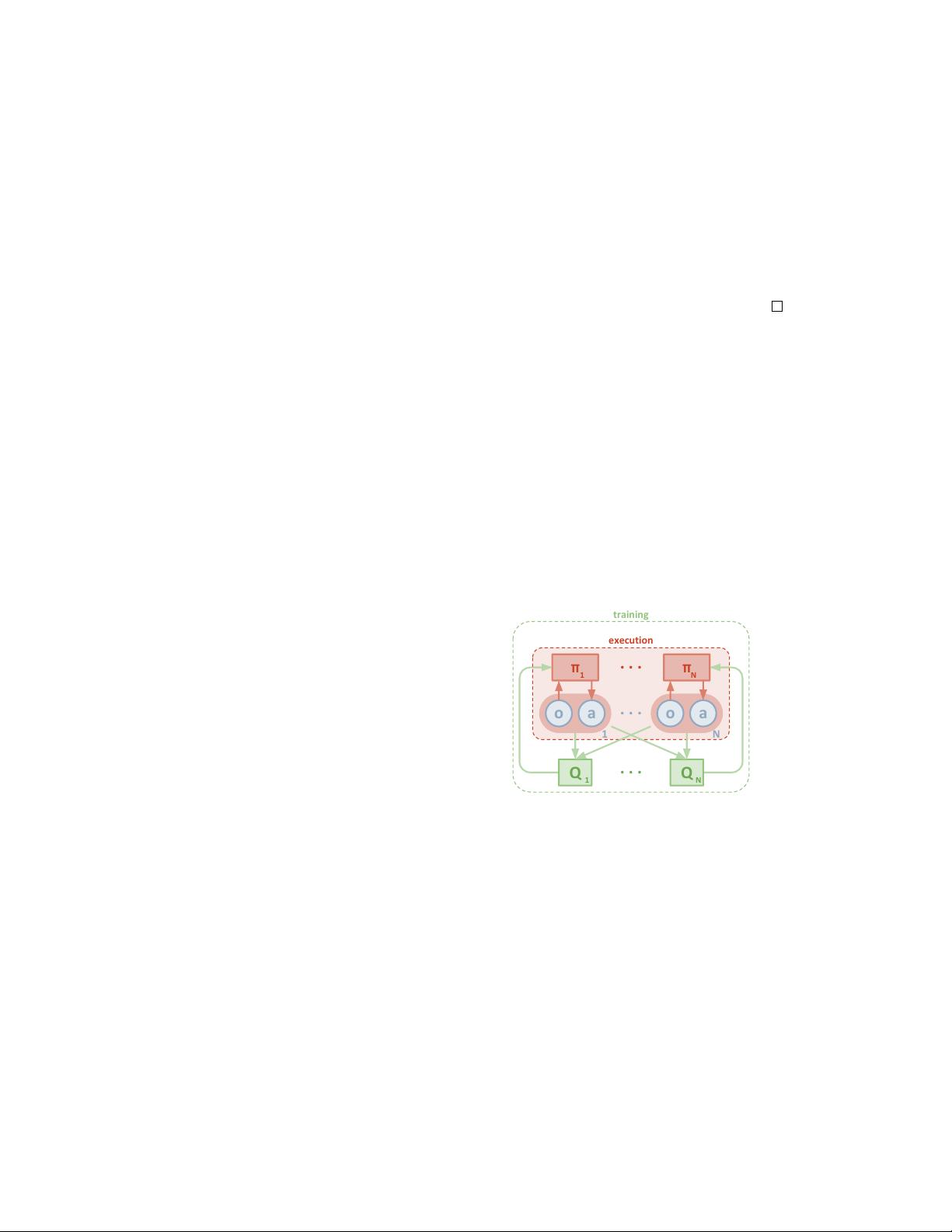
We then present an adaptation of actor-critic methods that considers action policies
of other agents and is able to successfully learn policies that require complex multi-
agent coordination. Additionally, we introduce a training regimen utilizing an
ensemble of policies for each agent that leads to more robust multi-agent policies.
We show the strength of our approach compared to existing methods in cooperative
as well as competitive scenarios, where agent populations are able to discover
various physical and informational coordination strategies.
1 Introduction
Reinforcement learning (RL) has recently been applied to solve challenging problems, from game
playing [
24
,
29
] to robotics [
18
]. In industrial applications, RL is emerging as a practical component
in large scale systems such as data center cooling [
1
]. Most of the successes of RL have been in
single agent domains, where modelling or predicting the behaviour of other actors in the environment
is largely unnecessary.
However, there are a number of important applications that involve interaction between multiple
agents, where emergent behavior and complexity arise from agents co-evolving together. For example,
multi-robot control [
21
], the discovery of communication and language [
31
,
8
,
25
], multiplayer games
[
28
], and the analysis of social dilemmas [
17
] all operate in a multi-agent domain. Related problems,
such as variants of hierarchical reinforcement learning [
6
] can also be seen as a multi-agent system,
with multiple levels of hierarchy being equivalent to multiple agents. Additionally, multi-agent
self-play has recently been shown to be a useful training paradigm [
29
,
32
]. Successfully scaling RL
to environments with multiple agents is crucial to building artificially intelligent systems that can
productively interact with humans and each other.
Unfortunately, traditional reinforcement learning approaches such as Q-Learning or policy gradient
are poorly suited to multi-agent environments. One issue is that each agent’s policy is changing
as training progresses, and the environment becomes non-stationary from the perspective of any
individual agent (in a way that is not explainable by changes in the agent’s own policy). This presents
learning stability challenges and prevents the straightforward use of past experience replay, which is
∗
Equal contribution.
arXiv:1706.02275v4 [cs.LG] 14 Mar 2020


剩余15页未读,继续阅读

汀、人工智能
- 粉丝: 8w+
- 资源: 400
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 利用迪杰斯特拉算法的全国交通咨询系统设计与实现
- 全国交通咨询系统C++实现源码解析
- DFT与FFT应用:信号频谱分析实验
- MATLAB图论算法实现:最小费用最大流
- MATLAB常用命令完全指南
- 共创智慧灯杆数据运营公司——抢占5G市场
- 中山农情统计分析系统项目实施与管理策略
- XX省中小学智慧校园建设实施方案
- 中山农情统计分析系统项目实施方案
- MATLAB函数详解:从Text到Size的实用指南
- 考虑速度与加速度限制的工业机器人轨迹规划与实时补偿算法
- Matlab进行统计回归分析:从单因素到双因素方差分析
- 智慧灯杆数据运营公司策划书:抢占5G市场,打造智慧城市新载体
- Photoshop基础与色彩知识:信息时代的PS认证考试全攻略
- Photoshop技能测试:核心概念与操作
- Photoshop试题与答案详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


