无监督时间建模:双向多速率视频重建
PDF格式 | 760KB |
更新于2025-01-16
| 47 浏览量 | 举报
“双向多速率重建视频时间模型是悉尼科技大学的研究者提出的一种无监督的时间建模方法,旨在解决视频领域缺乏足够标记数据的问题,特别是对于时间信息的建模。该模型称为多速率视觉递归模型(MVRM),通过训练不同间隔的剪辑帧来学习处理运动速度变化的能力。”
在视频分析中,时间信息的准确捕捉是至关重要的。早期的手工特征如密集轨迹(DT)和改进的密集轨迹(iDT)虽然能捕获视频运动结构,但因为光流计算的高昂成本和提取效率低而受到限制。随着深度学习的发展,深度视觉特征在图像分类和检测任务上表现出了优于传统手工特征的效能,但在视频表示学习方面仍然存在挑战。
双向多速率重建视频时间模型(MVRM)的创新之处在于其无监督学习策略,能够从未修剪的视频中学习时间信息。考虑到运动速度的变化,模型通过编码不同间隔的帧来适应这种变化。例如,快速运动的场景可能需要更高的帧采样率,而静态或慢速运动的场景则可以使用较低的采样率(如图1所示)。这种方法使得学习到的模型更加灵活,能够更好地处理各种运动速度的情况。
MVRM的核心在于利用过去和未来相邻片段作为时间上下文,重建两个时间跨(现在→过去和现在→未来),这模拟了时间的双向流动。模型通过向后重建和前向重建的双向招募策略来实现这一目标,从而捕获不同时间点的视频信息。
该方法在实际应用中展示了优秀的性能,尤其是在复杂事件检测和视频字幕生成这两个具有挑战性的任务上。在MEDTest-13数据集上,对于事件检测,MVRM实现了最佳单一特征,相比现有方法提高了10.4%的表现。同时,在YouTube2Text数据集的全部评估指标上,MVRM也达到了视频字幕生成的最优效果。
双向多速率重建视频时间模型是一种有效的视频理解工具,通过无监督学习和多速率框架,能够在缺乏标注数据的情况下捕捉和建模时间信息,提高视频分析的准确性和效率。这一方法为未来视频理解和处理技术的发展提供了新的思路。
2655
∗
∗
∗
V H
邻域以无监督的方式被纳入网络,提供了更丰富的训
练信息,并创造了从大量未经修剪的视频中学习的机
会。
视频字幕。视频字幕作为连接视觉理解和自然语言描
述的桥梁,近年来已成为一个热门的任务。条件是
在视觉上下文中,RNN每一步产生一个单词来生成视
频的字幕。Venugopalan等人[44]使用堆叠序列到序列
(seq2seq)[40]模型,其中
慢食
FastSlow
V
h
t-1
U
x
+
+
LSTM用作视频序列编码器,另一个LSTM用作字幕解
码器。Yao等人[51]在描述解码阶段引入了时间注意机
制。Pan等人[28]提出使用分层LSTM对视频序列进行
建模,而Yu
等人
。[52]使用分层GRU网络来模拟字幕
的结构。在这项工作中,我们证明了在我们的模型中
学习的强视频表示改进了视频字幕任务,证实了我们
的特征的泛化能力。
3.
多速率视觉递归模型
在本节中,我们将介绍我们的视频序列建模方法。
我们首先回顾了门控递归单元(GRU)的结构,并将
GRU扩展到多速率版本。然后介绍了无监督表示学习
的模型架构,随后介绍了事件检测和视频字幕的任务
特定模型在模型描述中,为了增加可读性,我们省略
了所有的偏差项。
3.1.
多速率门控循环单元
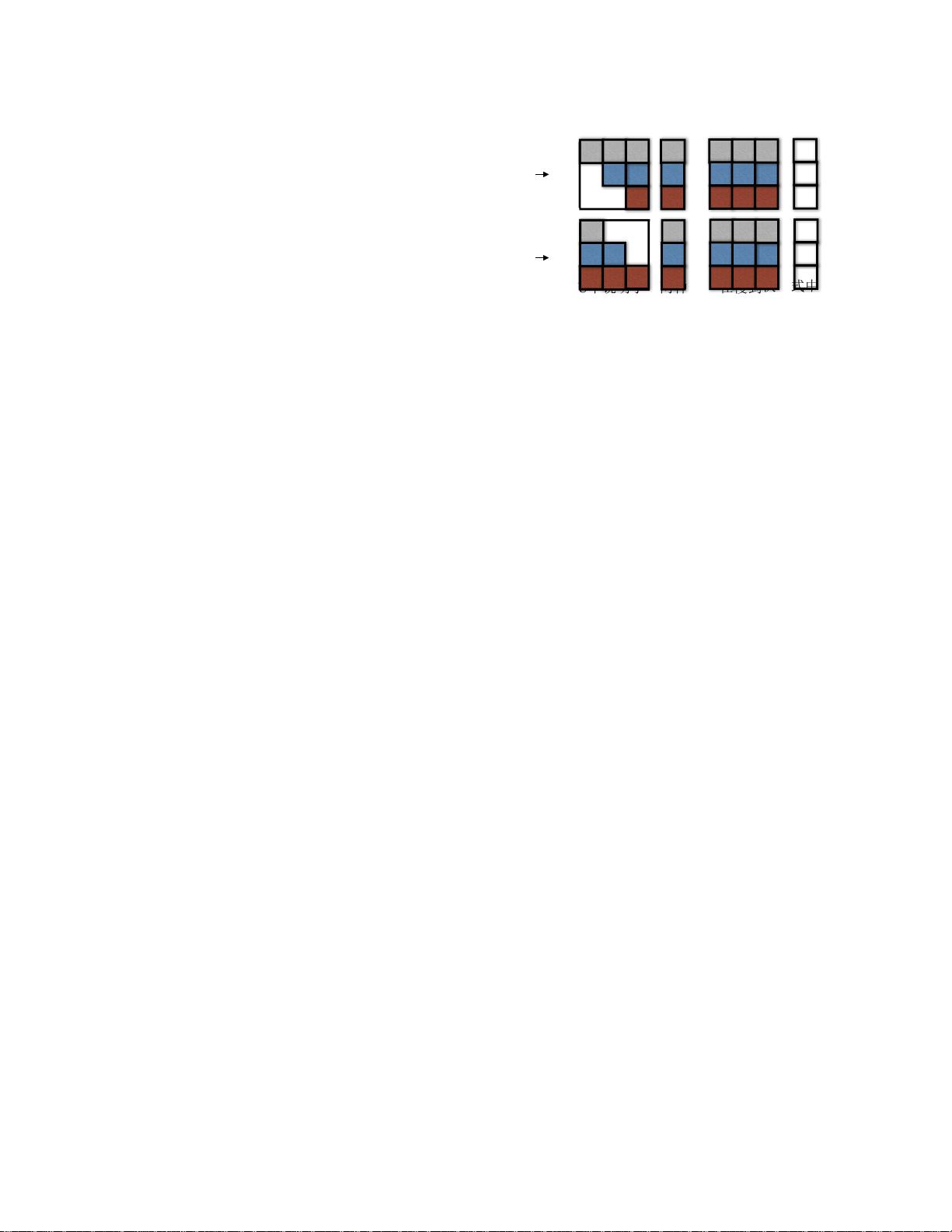
图
2.
我们在
mGRU
中说明了这两种模式 在慢到
快模式中,状
态矩阵
V
是
块上三角矩阵
,并且在快到慢模式中,它们是块
下三角矩阵。
多速率门控递归单元(
mGRU
)。受发条
RNN [22]
的启发,我们将
GRU
单元扩展到多速率版本。发条
RNN
使用延迟的输入连接和步骤之间的相互连接来
捕获更长的依赖关系。与传统的
RNN
不同,在传统
的
RNN
中,状态中的所有单元都遵循等式中的协议
1
,发条
RNN
中的状态和权重被分成不同的组,以
不同的速率对信息进行我们将状态
h
t
分成
k
组,每组
g
i
具有时钟周期
Ti
,其中
i
∈ {1
,
. . .
,
k
}。
Ti
可以是任意数,我们经验性地
使用
k
=
3
并设置
T1
,
T2
,
T3
=
1
,
3
,
6
。较快的组(具有
较小的
T
i
)比
较慢的组,较慢的模块跳过更多的输入。形式上,在
每个步骤t,满足(tMODT
i
)
=
0
的组的矩阵被激活并且
用于计算下一状态,其为
r
i
=σ(U
i
x
公
司
简
介
V
i
,
j
h
j
)
,
门控经常性股。在每一步t,
GRU
单元获取
t r
t
j=1
r
t
−1
帧表示
x
t
和先前状态
h
t
-1
作为输入
z
i
=σ
(
U
i
x
公
司
简
介
V
i
,
j
h
j
)
,
并生成隐藏状态H
以及输出O
的
t z
t
j
=1
z
t
−1
(三
)
t t
h
<$
i
=
t
anh
(
U
i
x
公
司
简
介
V
i
,
j
(r
i
h
j
))的情
况
下,
由下式计算
t
h
'
不
j
=1
h
<$
t
t
−1
h
i
=
(
1
−
z
i
)
h
i
+
z
i
h
<$
i
,
r
t
=σ(U
r
x
t
+ V
r
h
t
−
1
)
,
t t t
−1
t t
z
t
=
σ
(U
z
x
t
+ V
z
h
t
−
1
)
,
h
<$
t
=
t
anh
(
U
h
<$
x
t
+
V
h
<$
(
r
t
h
t
−
1
))
,
h
t
=
(
1
−
z
t
)
h
t
−
1
+
z
t
h
<$
t
,
o
t
= W
o
h
t
,
(一)
其中,状态权重矩阵
Vk
被划分为
k
个
块行,并且每个
块行被划分为
k
个
块列。
Vi
,
j
表示块行
i
和块列
j
中的
子矩阵
。
输入权重矩阵
U
i
被划分
为
k
个块行,并且
U
i
表示块行
i
中的权重
其中
x
t
是输入,
r
t
是复位门,
z
t
是
更新门,
h
t
是建议状
态,
h
<$
t
是内部状态,
σ
是
sigmoid激活函数U和V
是
加权函数,
和
Σ
.
i
V
i
,
j
h
j
,
快速→慢速模式
k
V
i
,
j
h
j
=
1
t−
1
trices,而
xes
是元素乘法。输出
o
t
通过状态
h
t
的线性变
换计算。我们将整个过程表示为:
j
=1
μ
m
t
−1
k i
,
j
j
j=i
t−1
,
慢速
→
快速模式
(四)
h
t
,
o
t
=
GRU
(
x
t
,
h
t
−
1
)
,
(
2)
当它迭代了S步时,我们可以得到最后一步的
状态h
S
。
两种模式可用于状态转换。在从慢到快模式中,较
快组的状态考虑先前较慢的状态,因此较快状态不仅
包含当前速度的信息,而且包含较慢且不太快的信
息。
Σ
剩余11页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
