细粒度分类:基于混合专家的统一框架
86 浏览量
更新于2025-01-16
收藏 1.14MB PDF 举报
“学习粒度特定专家的混合用于细粒度分类”
本文探讨的是细粒度视觉分类问题,这是一个旨在识别图像子类别的任务,如动物品种识别。在细粒度分类中,类间的差异往往很小,而类内的变化较大,加上多对象尺度和复杂背景,使得这类问题更具挑战性。为解决这些问题,作者提出了一种名为“学习粒度特定专家的混合”(Learning Granularity-Specific Experts for Mixtures, ME)的框架。
传统的混合专家(ME)模型基于神经网络,采用分区和征服的策略,将问题空间划分为多个子空间。然而,在细粒度分类中,由于可用训练数据有限,直接应用数据划分策略并不实际。为此,作者引入了一种新的方法,结合了专家渐进增强学习策略和基于Kullback-Leibler分歧的约束来促进专家之间的多样性。
这一策略允许新专家在已有专家知识的基础上学习,并逐步加入到模型中。通过Kullback-Leibler分歧约束,确保新专家与已有专家的预测分布不同,促使每个专家关注问题的不同方面,从而更专注于特定的子空间问题。这种方法有助于提升模型的分类性能,实现在几个细粒度基准数据集上的先进表现。
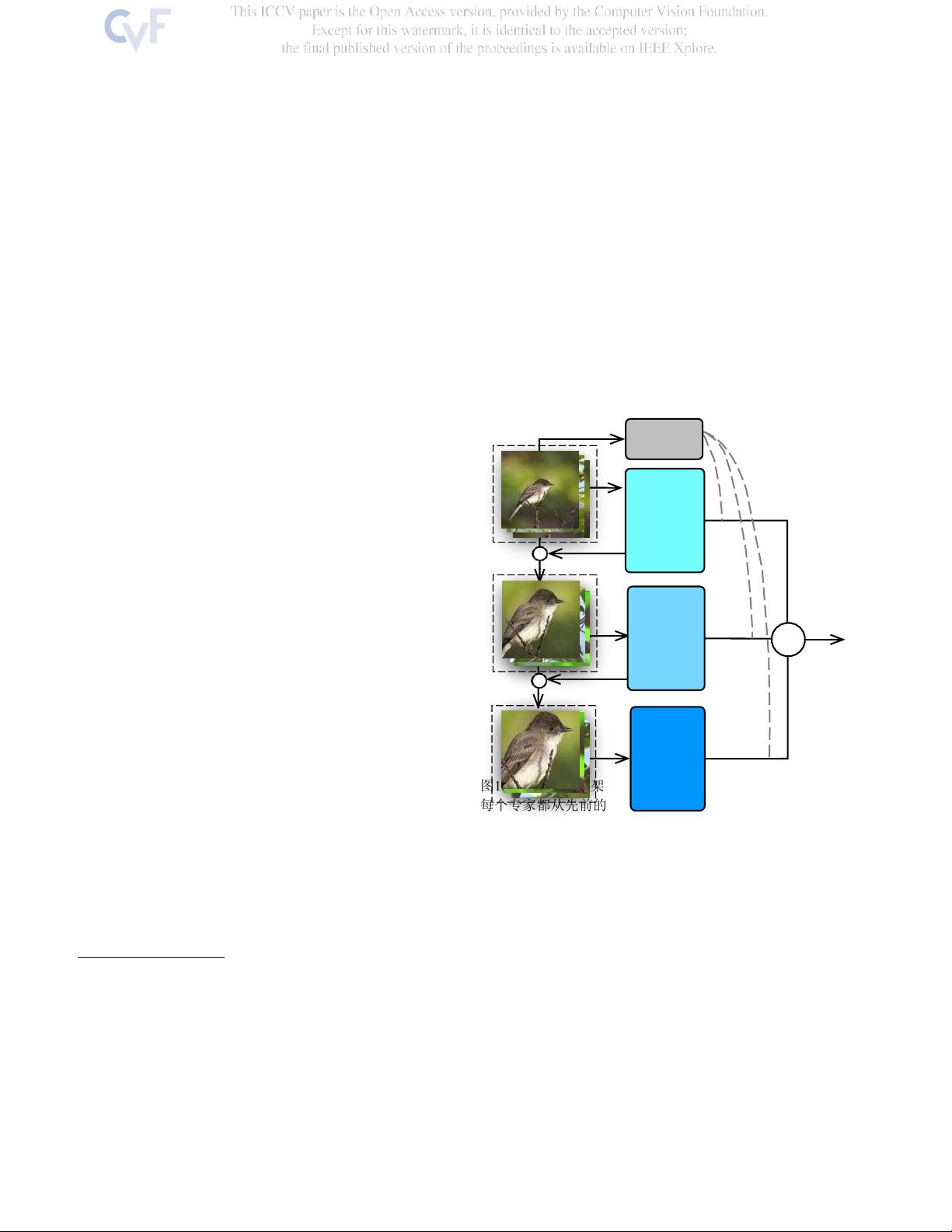
文章结构如图1所示,包括多个专家和一个门控网络。门控网络的作用是决定每个专家对最终预测的贡献比例。专家之间通过学习和协作,共同处理复杂的细粒度识别任务,而门控网络则负责协调这些专家,确保整体分类效果的优化。
该研究通过创新的混合专家框架,有效地解决了细粒度分类中的数据限制和复杂性问题,提高了模型的泛化能力和分类准确性。这种多样性驱动的专家学习方法为未来在有限数据条件下提升机器学习模型性能的研究提供了新的思路。
8331
学习粒度特定专家的混合用于细粒度分类
张连波
1
、黄少
丽
2
、刘伟
1
、陶大成
2
1
澳大利亚新南威尔士州齐本德尔市悉尼科技大学
FEIT
计算机科学学院高级分析研究所
2
UBTECH Sydney AI Centre,School of Computer Science,FEIT,University of Sydney,
Darlington,NSW 2008,Australia
{lianbo.zhang@student.,wei.liu@} uts.edu.au{shaoli.huang,dacheng.tao}@ sydney.edu.au
摘要
我们的目标是将细粒度识别的问题空间划分为一些
特定的区域。为了实现这一点,我们开发了一个统一
的框架的基础上混合的
experts
。由于可用于细粒度识
别问题的数据有限,通过使用数据划分策略来学习不
同的实验是不可行的。为了解决这个问题,我们通过
结合专家渐进增强学习策略和基于
Kullback-Leibler
分
歧的约束来促进专家之间的多样性该策略利用已有专
家的先验知识在数据集上学习新的专家,并将其依次
加入模型,同时引入约束条件,迫使专家产生不同的
预测分布。这些驱动器的
experts
学习任务从不同的方
面,使他们专注于不同的子空间问题。实验结果表
明,该模型提高了分类性能,并达到了最先进的性能
在几个细粒度的基准数据集。
1.
介绍
细粒度视觉分类,如动物品种识别[10,16,27,
21],旨在识别给定图像的子类别。细粒度任务中的对
象通常具有较小的类间方差和较大的类内方差,以及
多对象尺度和复杂背景,导致问题空间更加复杂。
在本文中,我们倾向于将细粒度问题空间划分为
此,我们开发了一个统一的框架,基于混合神经网络
前,
*
通讯作者。
图
1.
概述我们的框架,其中包括几个专家和一个门控网络。
每个专家都从先前的专家那里学习先前的知识门控网络确定
每个专家对最终预测的贡献。
perts(ME)[9,19,1]。基于神经网络的ME通常遵循
分区和征服的方案,其中问题空间被划分为子空间。
像[13,12]这样的例子已经在细粒度任务上进行了研
究,但是这些方法专注于从一组独特的子集中学习专
家,就像传统的ME方法一样。战略
门控网
络
G
1
G
2
Y
G
3
Expert 3
专家
2
Expert 1
下载后可阅读完整内容,剩余9页未读,立即下载
2021-09-20 上传
2019-08-16 上传
2021-09-25 上传
点击了解资源详情
138 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
