无监督生成协作学习用于视频异常检测
PDF格式 | 12.17MB |
更新于2025-01-16
| 138 浏览量 | 举报

... ... ... ...
14744
0
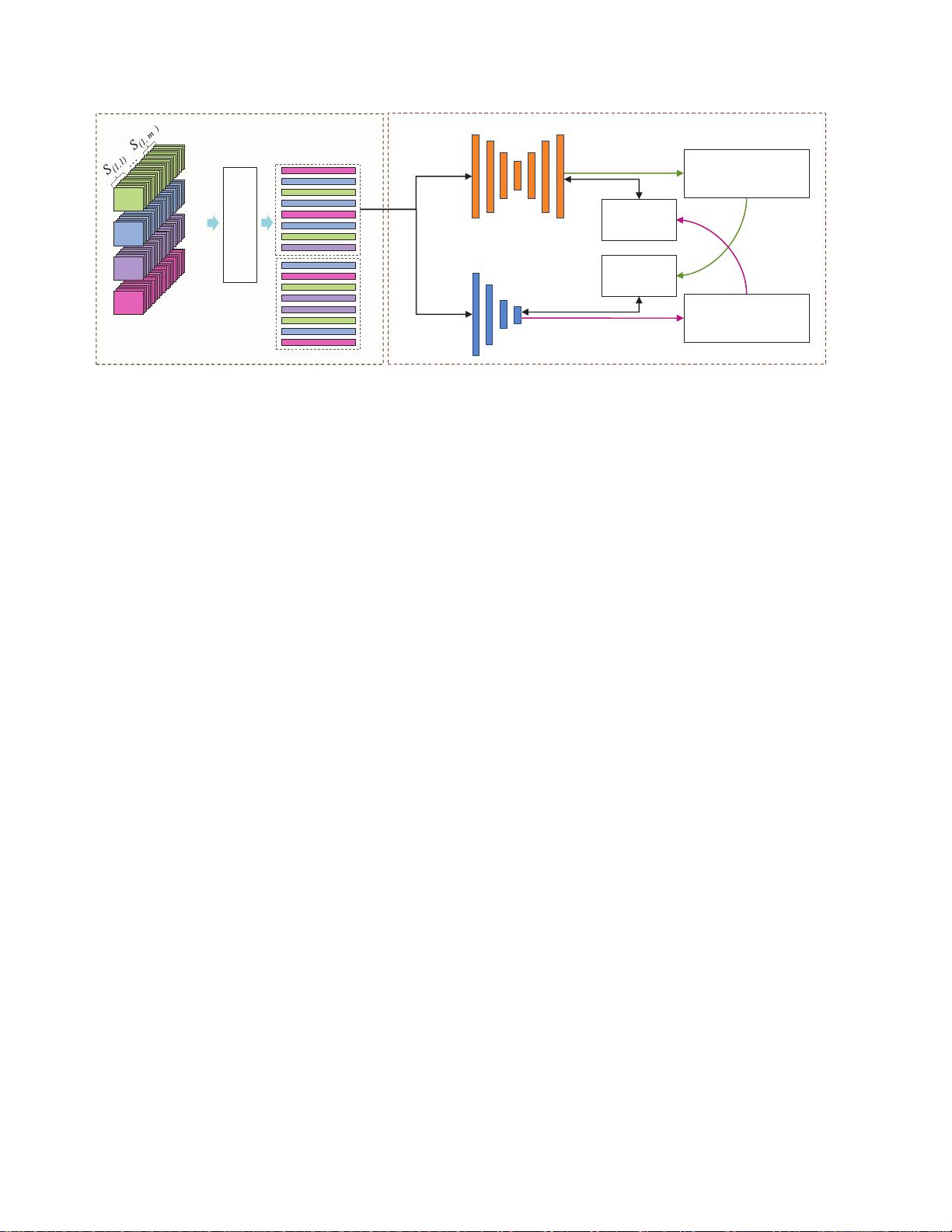
生成协作学习用于无监督视频异常检测
0
M.ZaighamZaheer1,2,3,5,ArifMahmood4,M.HarisKhan5,MattiaSegu3,FisherYu3,Seung-IkLee1,2*
电子与通信研究所1,科学与技术大学2,ETHZurich3,旁遮普信息技术大学4,穆罕默德∙本∙扎耶德人工智能大学5
0
摘要
0
弱监督和一类分类(OCC)设置下的视频异常检测已经得到
了很好的研究。然而,无监督视频异常检测方法相对较少,
可能是因为异常事件的发生频率较低且通常不明确,再加上
缺乏真实监督,可能会对学习算法的性能产生不利影响。这
个问题具有挑战性,但也具有回报,因为它可以完全消除获
取繁琐注释的成本,并使这些系统能够在没有人为干预的情
况下部署。为此,我们提出了一种新颖的无监督生成协作学
习(GCL)方法,用于视频异常检测,该方法利用了异常的
低频率,以在生成器和判别器之间建立交叉监督。本质上,
两个网络以合作方式进行训练,从而实现无监督学习。我们
在两个大规模视频异常检测数据集UCF
crime和ShanghaiTech上进行了大量实验。与现有的无监督
和OCC方法相比,我们的方法在性能上得到了一致的改进,
证实了其有效性。
0
1.引言
0
在现实世界中,基于学习的异常检测任务非常具有挑战性,
主要是因为此类事件的罕见发生。由于这些事件的无约束性
质,这个挑战进一步加剧。因此,获取足够的异常示例非常
困难,而且可以安全地假设永远不会收集到用于训练完全监
督模型所需的详尽集合。为了使学习变得可行,异常通常被
认为是与正常数据明显偏离的重要偏差。因此,一种流行的
异常检测方法是训练一个仅使用正常训练样本学习主导数据
表示的一类分类器[14,17,25,28,41,42,45,47,60,64,
66,72]
0
*通讯作者。**Zaigham在ETH
Zurich担任访问研究员和MBZUAI实习生期间完成了部分工作。
0
(b)一类分类(c)弱监督(d)无监督(a)完全监督
0
异常帧正常帧A异常视频
0
A
0
未标记的视频
0
图1.视频异常检测的不同训练模式:(a)
完全监督模式需要训练数据中的帧级正常/异常注释。(b)
一类分类(OCC)只需要正常训练数据。(c)
弱监督模式需要视频级别的正常/异常注释。(d)
无监督模式不需要训练数据注释。
0
(图1)
一类分类(OCC)方法的一个明显缺点是正常训练数据的有
限可用性,无法捕捉所有正常变化[9]。此外,OCC方法通
常不适用于视频监控中存在的具有多个类别和广泛动态情况
的复杂问题。在这种情况下,未见过的正常活动可能与学习
到的正常表示显著偏离,被预测为异常,导致误报[14,
67]。最近,弱监督异常检测方法变得越来越受欢迎[24,26,
34,46,56,63],通过使用视频级别标签[50,65,67,69,
74]来减少获取手动细粒度注释的成本。具体而言,如果视
频的某些内容是异常的,则将其标记为异常,如果所有内容
都是正常的,则将其标记为正常,需要对整个视频进行手动
检查。尽管这种注释相对具有成本效益,但在许多实际应用
中仍然不切实际。有大量的视频数据,特别是原始镜头,可
以用于异常检测训练,而不需要注释成本。不幸的是,据我
们所知,几乎没有任何值得注意的尝试利用未标记的训练数
据进行视频异常检测。在这项工作中,我们探索了用于视频
异常检测的无监督模式,这显然比完全、弱或一类监督更具
挑战性(图1)。然而,由于假设最少,因此更有回报,将鼓励
开发新颖且更实用的算法。请注意,文献中的“无监督”一
词通常指的是假设所有正常训练数据的OCC方法[11,37,64,
66]。然而,它也表示不需要训练数据注释。

剩余10页未读,继续阅读
相关推荐

1053 浏览量



cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握PerfView:高效配置.NET程序性能数据
- SQL2000与Delphi结合的超市管理系统设计
- 冲压模具设计的高效拉伸计算器软件介绍
- jQuery文字图片滚动插件:单行多行及按钮控制
- 最新C++参考手册:包含C++11标准新增内容
- 实现Android嵌套倒计时及活动启动教程
- TMS320F2837xD DSP技术手册详解
- 嵌入式系统实验入门:掌握VxWorks及通信程序设计
- Magento支付宝接口使用教程
- GOIT MARKUP HW-06 项目文件综述
- 全面掌握JBossESB组件与配置教程
- 古风水墨风艾灸养生响应式网站模板
- 讯飞SDK中的音频增益调整方法与实践
- 银联加密解密工具集 - Des算法与Bitmap查看器
- 全面解读OA系统源码中的权限管理与人员管理技术
- PHP HTTP扩展1.7.0版本发布,支持PHP5.3环境
