基于学习的车载SLAM快速束调整方法
114 浏览量
更新于2025-01-16
收藏 1.08MB PDF 举报
"车载SLAM中基于学习的捆绑调整:一个快速优化方法"
本文主要探讨的是在车载SLAM(Simultaneous Localization and Mapping)中如何通过一种基于学习的捆绑调整(Bundle Adjustment, BA)方法来实现更快速的优化,特别适用于计算资源有限的嵌入式系统。捆绑调整是SfM(Structure from Motion)和视觉SLAM中的关键步骤,旨在通过最小化图像特征的重投影误差来优化相机姿态和地图点的参数。
传统的束调整算法,如Levenberg-Marquardt方法,虽然能够提供高精度的参数估计,但其计算复杂度较高,对于实时性要求严格的车载SLAM系统来说,可能无法满足需求。尤其是当需要在关键帧上进行局部BA时,快速的执行时间对于保持系统的鲁棒跟踪至关重要。
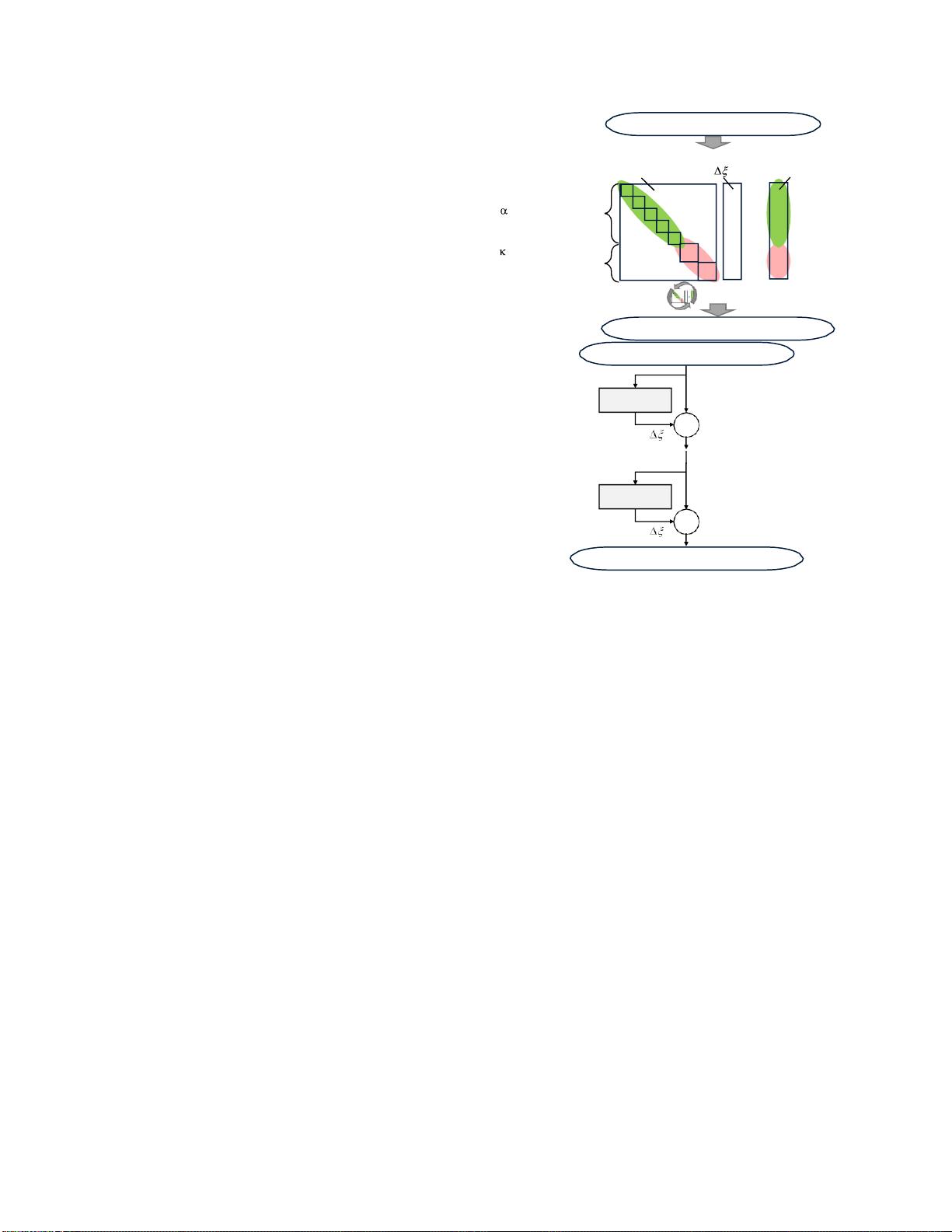
田中哲、Sasagawa和冈谷孝之提出了一种新的方法,利用图网络来实现BA的快速计算。这种方法构建了一个由关键帧和地标节点以及表示地标的可见性的边组成的图形模型。图网络接收初始参数值作为输入,并通过预测这些参数的最优更新值来进行学习。其内部结构受到Levenberg-Marquardt方法正规方程的启发,以重投影误差的总和作为损失函数进行训练。
实验结果显示,尽管该方法在参数估计精度上略低于传统BA,但其执行速度显著提升,达到传统方法的1/60,这对于实时SLAM应用来说是一个巨大的改进。这使得在嵌入式系统中实现高效且稳定的SLAM成为可能,减少了由于计算时间过长导致的跟踪失败问题。
在视觉SLAM领域,基于特征点的方法因其成熟性和鲁棒性而被广泛应用。然而,即使是轻量级的特征描述符,如ORB-SLAM系统所采用的ORB,也会因BA步骤的计算成本而导致性能瓶颈。因此,这个基于学习的BA方法为解决这一问题提供了一种新的解决方案,有助于在保持系统性能的同时,减少计算负担。
这篇研究工作对于车载SLAM和类似应用场景具有重要意义,它展示了如何通过机器学习技术优化传统BA算法,以适应资源受限的环境,进一步推动了实时SLAM系统的发展。
6252
(
H
)
(
)
下
一
页
(
g
)
=
迭代
估计的相机姿势/地标
初始相机姿势/地标
GN块
正在更新值()
+
GN块
正在更新值()
+
估计的相机姿势/地标
步骤S
步骤1
使用观测值作为训练数据来重新发送两个时间点之间
的状态转换它的目的是避免传统的基于物理模型的仿
真的困难,如计算的复杂性或物理模型然而,使通用
ML模型在高维状态空间中学习具有大自由度的映射并
不简单。GN的成功归因于通过图对实体之间的交互的
刚好足够的表示
我们将GN应用于BA,其中输入是相机姿势和地标
的指定初始值,并且输出是它们的优化值。我们使用
因子图组成
行对应于
-th地标
行对应于
-th关键帧
初始相机姿势/地标
Hessian矩阵更新值梯度
摄像机姿势和地标的组合来构建GN并定制消息传递的
输入,其灵感来自Levenberg-Marquardt方法中使用的
Hessian,从而实现端到端学习。
3.
该方法
3.1.
学习捆绑调整
给定相机姿态和地标地标的图像坐标。视觉SLAM
系 统 经 常 在 内 部 进 行 小 型 / 中 型 BA , 其 通 常 使 用
Levenberg-Marquardt方法。它通过求解线性方程迭代
地更新估计 其计算复杂性随着参数的数目而增加; 5-15
个更新是必要的,直到收敛。
为了在更短的时间内完成此BA计算,我们用基于学
习的方法代替Levenberg-Marquardt方法。具体来说,
我们训练一个模型,该模型接收相机姿势和地标的初
始值,并输出它们的估计值。这种模型需要满足以下
要求:
它可以处理可变数量的输入/输出,即,M
个
相机
姿态和N
个
地标,其中M和N在每个时间不同提供
的观察结果也不同。
它可以尽可能准确地预测参数,尽管从输入到输
出的映射有很大的自由度。
为了满足这些要求,我们采用了图网络框架[5]。它
使用一个图来利用手头问题的归纳偏差并对其进行推
理;根据输入自适应地创建图形。在这项研究中,我们
使用流行的BA图表示,即,两种类型的节点之间的二
分图关键帧(即,相机姿态)和地标,其边缘反映来
自关键帧的地标的可见性。这个图处理所有可能的交
互
(a)
基于Levenberg-Marquardt方法
(b)
基于学习的图网络
图
2.
基于
Levenberg- Marquardt
方法的标准
BA
与所提出的基于
学习的方法的比较
关键帧和地标,使得在我们的问题中使用归纳偏差然
而,在设计图形网络中的组件时仍然存在很大的自由
我们应该如何选择合适的设计?
我们的解决方案是模仿Levenberg-Marquardt方法;参
见图2。由于如果我们执行精确的计算将不会有助于加
速,因此我们考虑使用可学习的模型来绕过Levenberg-
Marquardt计算的一部分。我们的初步测试发现,它可
以训练一个模型来预测Hessian矩阵的块对角元素和梯
度的参数更新。
按 照 Levenberg-Marquardt 方 法 , 我 们 多 次 更 新 参
数,而更新的次数是固定的,而不是我们设计了一个
图网络(GN)块来更新参数一次,并将它们堆叠起来
以执行多次更新。我们训练GN块的堆栈因此,请注
意 , 我 们 并
不 试 图 或 期 望
使 每 个 块 预 测 Levenberg-
Marquardt更新。
·
·
剩余10页未读,继续阅读
点击了解资源详情
166 浏览量
501 浏览量
808 浏览量
202 浏览量
点击了解资源详情
1466 浏览量
124 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现ART与SART算法在医学CT重建中的应用
- S2SH整合版:快速搭建Struts2+Spring+Hibernate开发环境
- 托奇卡项目团队成员介绍
- 提升外链发布效率的SEO推广神器——搜易达网络推广大师v2.035
- C#打造简易记事本应用详细教程
- 探索虚拟现实地图VR的奥秘
- iOS模拟器屏幕截图新工具
- 深入解析JavaScript在生活应用开发中的运用
- STM32F10x函数库3.5中文版详解与应用
- 猎豹浏览器v6.0.114.13396 r1:安全防护与网购敢赔
- 掌握JS for循环输出的最简洁代码技巧
- Java入门教程:TranslationFileGenerator快速指南
- OpenDDS3.9源码解析及最新文档指南
- JavaScript提示框插件:鼠标滑过显示文章摘要
- MaskRCNN气球数据集:优质图像识别资源
- Laravel日志查看器:实现Apache多站点日志统一管理
