跨任务注意机制在多任务学习中的应用——提升场景理解
159 浏览量
更新于2025-01-16
收藏 1.31MB PDF 举报
"本文主要探讨了多任务学习中的跨任务注意机制,并强调了其在场景理解中的应用,特别是在2D语义分割、密集深度估计、表面法线估计和边缘估计等任务中的价值。作者提出了一个新的多任务学习架构,利用相关引导注意和自我注意来促进任务间的相互增强,提高平均表示学习效果。文章通过广泛的实验验证了该方法在合成和真实数据集上的优势,并将其扩展到多任务无监督域自适应设置。提供的代码库地址为https://github.com/cv-rits/DenseMTL。"
在深度学习领域,多任务学习(MTL)已经成为解决复杂场景理解的有效途径。传统的单任务学习方法往往专注于单一任务的性能提升,而MTL则旨在通过共享参数和信息交流,实现不同任务之间的互补和协同,从而提高整体模型的泛化能力。在这种框架下,多个任务共享一个编码器,而每个任务拥有特定的解码器,如图1所示,解码器之间通过注意力机制进行信息交换,形成所谓的“多任务交换块”(mTEB)。
跨任务注意机制是MTL的关键组成部分,它允许模型关注不同任务之间的相关性。相关引导注意是指模型根据任务之间的相关性调整注意力分配,例如,深度估计和语义分割任务之间可能存在紧密关联,深度信息可以帮助识别语义边界。自我注意则让模型能够关注自身任务的内部特征,以强化任务特定的表示学习。
在本文中,作者通过实验证明了提出的多任务学习架构在2D语义分割、密集深度估计和表面法线估计等多个任务上优于单一任务模型和竞争性的基线方法。实验不仅覆盖了有监督的设置,还扩展到了无监督的域自适应环境,展示出模型的广泛适用性和鲁棒性。
此外,多任务学习在实际应用中,尤其是在机器人和自动驾驶等领域,有着显著优势。例如,几何任务如深度和法线估计可以辅助语义任务,减少错误传播,反之亦然。通过在一个统一的系统中处理多个任务,可以更好地应对现实世界中的挑战,提高系统的稳定性和可靠性。
跨任务注意机制是多任务学习的核心,它促进了不同任务间的互补和协同,提高了整体模型的性能。这项工作对于理解如何有效地整合和利用多种视觉任务的信息,以实现更全面的场景理解具有重要意义。
2331
⭢
⭢
“
⭢
D
⭢
⭢
“
⭢ ⭢⭢
⭢
俄.
西
?
D
C
correlation-guided attention(绿色)to
i
,来自任务
j
的对任务
i
有贡献的特征。第二,自我关注
⭢
⭢
⭢
?
C
空间向
上-
样品
空间下
采样
项目
项目
提取物
掩模
通道孔
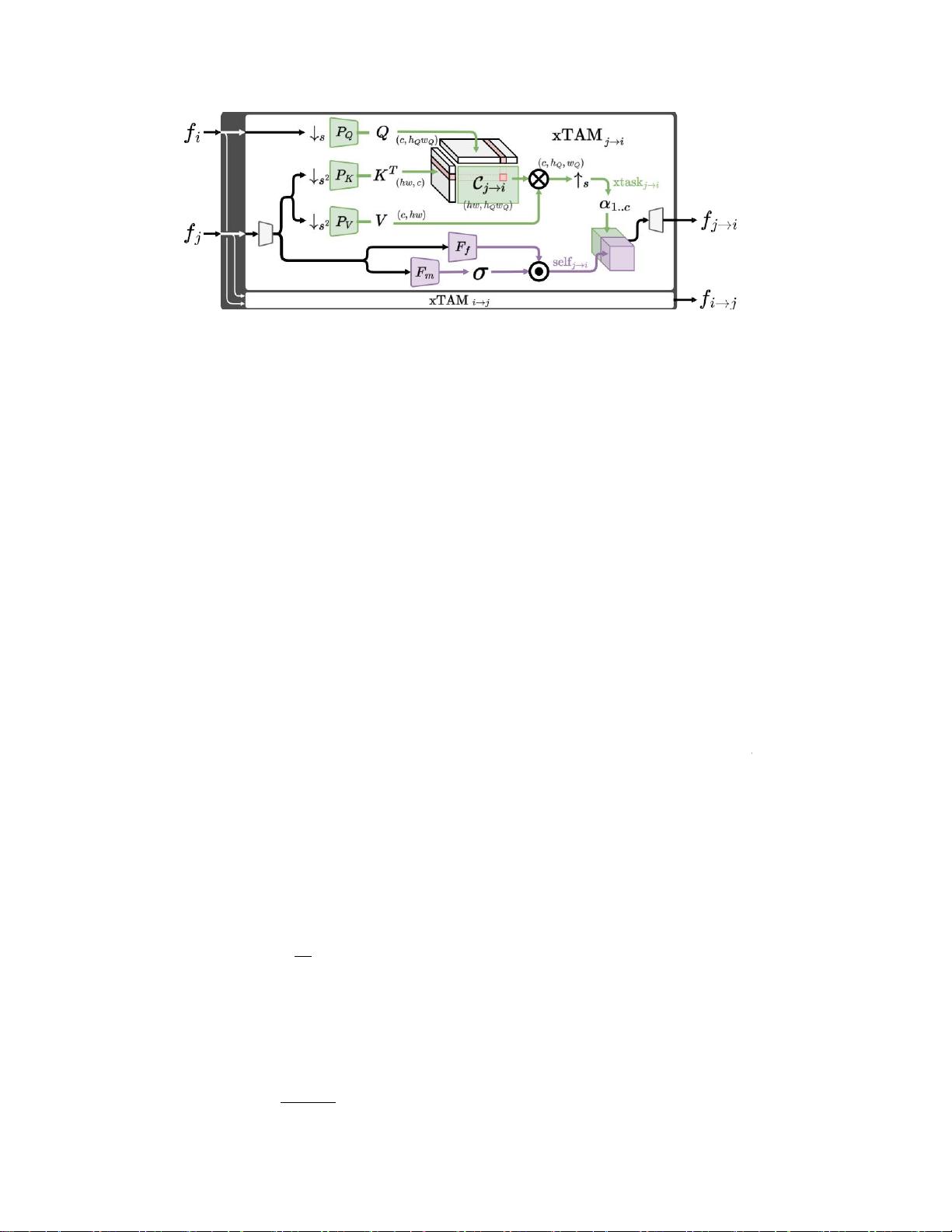
图2:双向跨任务注意力(xTAM)。 我们通过discov实现任务对(i,j)之间的信息流,
每个方向特征,
f
ji
和f
伊
什
季
.仅xTAM
朱
伊
在这里详细介绍。 它依赖于两种注意力机制。 一是
(紫色)以覆盖来自
R
信号
j
的互补信号
self
j
。最好的颜色。
为了便于讲话,我们描述方向
xTAM
j
i
注意力特征
xtask
j
i
通过乘以相关性
其中,任务
j
帮助任务
i
,但强调
xT AM bein n
具有投影的
j
特征的矩阵
C
j
∈
i
双向的,由
xTAM
j
i
和
xTAM
i
j
两者组成
。
xtask
j
i
3.1.1
方向性跨任务注意(
xTAM
ji
)。
在这里
,考虑
i作为我们的主要任务,
j
作为次要任务,
我们试图估计来自任务
j
的可以对i
有
贡献的特征。我们
利用两个跨任务注意力:(i)
相关性引导的注意力
,
其目标是利用跨任务空间相关性来引导提取次要任务
对主要任务的贡献特征,以及
(ii)对次要任务的
自我关注
,以自我发现对主要任务有
益的互补信号在图中,两种注意力的可视化分别用绿
色和紫色表示。2所示的序列。注意,每个注意力对主
要任务i
的
贡献不同
其中
V P
Vs
2
f
j
,
P
V
为
1x1
投影,
s
为
上采样算子。
自我关注。 我们还使用了空间注意力
[33]我们称之为相反,下面的机制(紫色块图。2)仅
从j中提取特征,并且旨在从fj中提取与预测任务i相关
的
私有信息
:
self
j
i
是 我 们
的 自 我 关 注 特 征
。 其 中 是 元 素 乘 法 , σ 是
sigmoid函数。
F
f
和F
m
都是卷积层,它们由目标任务i监
督,以学习从其中提取相关信息。
或者基于共享的
j
和
i
知识的识别,或者基于
特征
f
j
.
自我关注的特点是
自我
j
i
被定义为
独家
J
知识我们使用1x1卷积层(图中的灰色块)。2)
尺寸兼容性。
相关引导注意力。 为了引导功能,我们依赖于
来自
F
f
的特征与由F
m
提供的动态掩模之间的逐点相乘。
方向性特征。为了构造最终的
方向有限元
-
任务特征的空间相关性(
图雷
斯夫
朱
伊
为
歼
i
互动,两个注意力为主
见图
2
)。在实践中,我们将
缩减的
fi
和
fj
特征投影到
d
维子空间上,如
[29]
中所示,使得
K P
Q
sfi
,
Q
P
K
s
2
fj
,其中
s
是缩减算子,
s
是比例因子,并且
P
Q
,
P
K
分离
1x1
卷积。然后,通过对矩阵乘法
K
T
Q
应用
softmax
并使用
d
进行归一化
来获得空间相关矩阵
j
i
:
特征图被组合为:
f
ji
“rdiagpα1
,
...
,
α
c
q
∈
xtask
j
i
,
self
ji
s
,
(
4
)
其中
,
.
是通道级级联操作,
α
1
.. c
是可学习的
标量
,用于对c个通道进行加权
的xtask
ji
.所有α
1
.. c
初始化为0;学习将自适应地调整每
个通道的加权。直觉上,跨任务交换首先只从自我注
意开始,然后
C
j
i
T
Q
ste
c
.
(
一)
逐渐调整α
1
。
c
值以包括来自相关性引导的注意力的一些
贡献。 这个首字母-
化策略对于稳定训练非常重要,特别是
其中
d
是特征尺寸
[29]
。直觉上,
ji
具有高值,其中
来自
i
和
j
的特征
高度相关
剩余12页未读,继续阅读
661 浏览量
213 浏览量
112 浏览量
点击了解资源详情
2025-02-11 上传
2025-01-07 上传
2025-02-14 上传
2025-01-22 上传
657 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 昆仑通态MCGS嵌入版_XMTJ温度巡检仪软件包解压教程
- MultiBaC:掌握单次与多次组批处理校正技术
- 俄罗斯方块C/C++源代码及开发环境文件分享
- 打造Android跳动频谱显示应用
- VC++实现图片处理的小波变换方法
- 商城产品图片放大镜效果的实现与用户体验提升
- 全新发布:jQuery EasyUI 1.5.5中文API及开发工具包
- MATLAB卡尔曼滤波运动目标检测源代码及数据集
- DoxiePHP:一个PHP开发者的辅助工具
- 200mW 6MHz小功率调幅发射机设计与仿真
- SSD7课程练习10答案解析
- 机器人原理的MATLAB仿真实现
- Chromium 80.0.3958.0版本发布,Chrome工程版新功能体验
- Python实现的贵金属追踪工具Goldbug介绍
- Silverlight开源文件上传工具应用与介绍
- 简化瀑布流组件实现与应用示例
