深度学习驱动的高效3D隐式体积与纹理压缩技术
PDF格式 | 23.89MB |
更新于2025-01-16
| 58 浏览量 | 举报
"深度隐式体积压缩及其对应的纹理压缩方法"
深度隐式体积压缩是一种新兴的技术,主要用于优化存储和传输3D体素网格中的截断有符号距离场(TSDF)和相关纹理。TSDF是3D重建领域常用的一种数据结构,它能够表示物体表面附近的密度信息,常用于构建密集表面映射和自由视点视频。然而,这些表示方法往往需要大量的内存空间,特别是在处理高分辨率的4D数据时。
本文由谷歌的研究人员提出,他们设计了一种基于块状神经网络架构的端到端训练方法,用于压缩TSDF。这种方法旨在实现最佳的率失真平衡,即在压缩数据的同时尽可能减少信息丢失,保证重建的质量。为了防止在解压过程中出现拓扑错误,他们无损地压缩TSDF的符号信息,并通过设定体素大小的上界来限制可能的重建误差。
此外,针对与TSDF相关的纹理压缩,研究者们提出了一种快速的基于块状UV参数化的方法。该方法能生成一致的纹理贴图,随后利用现有的视频压缩算法(如H.264或HEVC)进行高效压缩。实验结果显示,他们的算法在两个4D性能捕捉数据集上对比现有最先进的方法,能在保持相同失真水平的情况下降低66%的比特率,或者在相同比特率下减少50%的失真。
论文中引用的前文表明,TSDF由于其体素值的相关性和规则的网格结构,被证明适合高效压缩。而传统的压缩方法如Draco[24]可能需要对低多边形网格进行简化,这可能导致细节丢失,而其他方法可能产生块状伪影(如[59]所示)。相比之下,该研究的新方法在保持低比特率的同时,显著降低了失真。
3D形状学习的编码器-解码器架构,借鉴了图像处理领域的卷积神经网络(CNN)的成功经验,特别适用于处理具有网格结构的数据。因此,研究者可能将这样的深度学习技术应用于压缩过程,以提高效率和重建质量。
这篇论文介绍了一种创新的压缩策略,旨在解决3D和4D数据存储和传输的挑战,特别是对于那些需要高效压缩以适应VR/AR、远程存在感和自由视点视频流的应用。该方法的贡献在于结合了深度学习和传统压缩技术的优势,以达到更高的压缩效率和更优的视觉效果。
1295
0
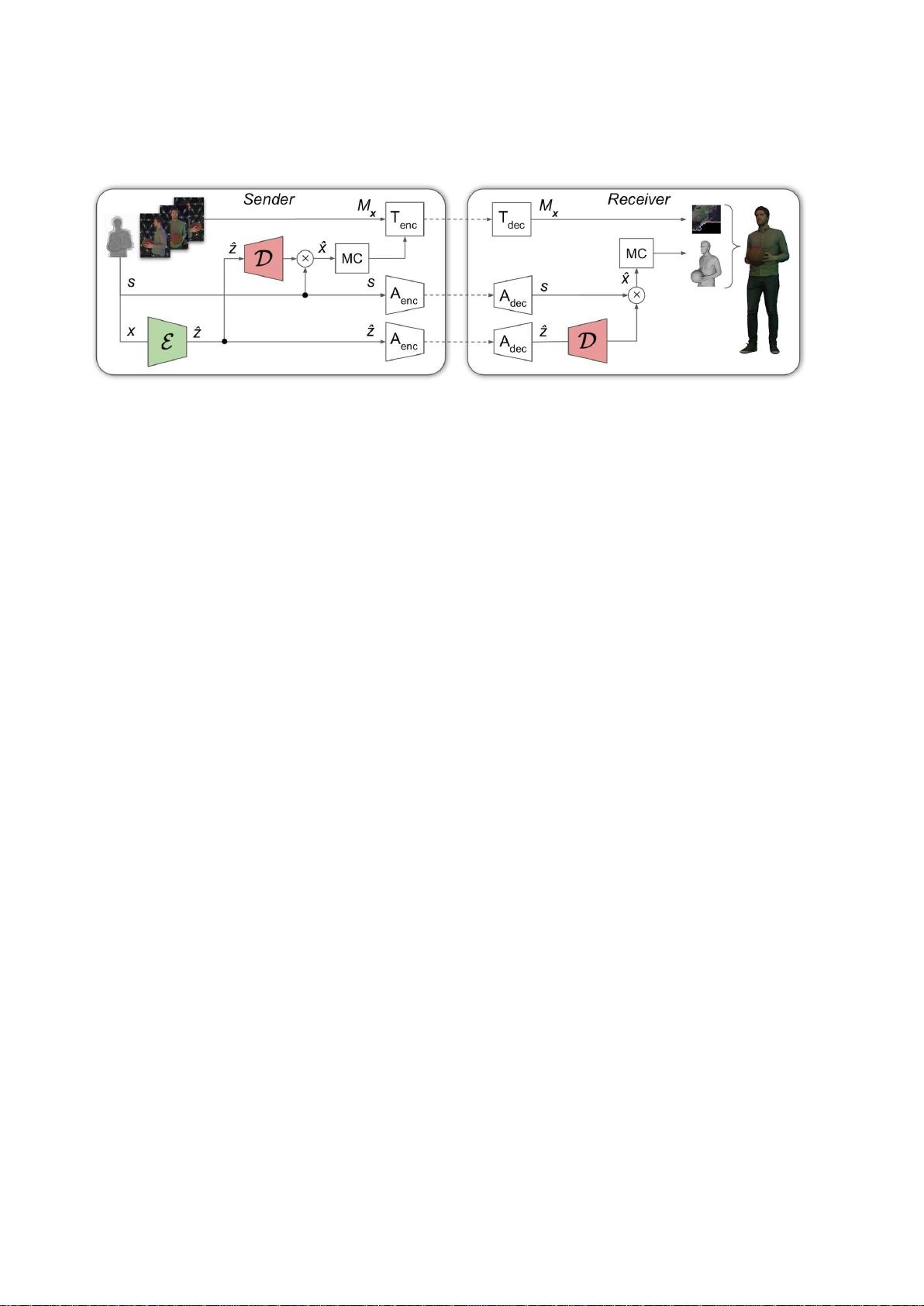
图2:压缩流水线-给定输入的TSDF块x及其符号配置s=sign(x),编码器将x转换为量化的代码ˆz=
bE(x)e。然后,ˆz和s通过学习的先验分布pˆz(ˆz)和解码器估计的条件分布ps|ˆz(s|ˆz)进行熵编码和传输到接收端(A
enc和Adec块)。重构的块ˆx=s⊙|D(ˆz)|与Marching
Cubes(图中的MC)一起用于提取网格,然后用于生成Morton打包图Mx。Mx被单独编码(使用Tenc和Tdec块)。
0
类似于[3]的优化自动编码器来进行端到端的3D几何压缩:Ya
n等人[69]使用了类似PointNet的编码器结合全连接解码器,
训练时直接最小化整个点云上的Chamfer距离,同时满足速
率约束。Quach等人[52]使用基于块的编码来在MVUB数据
集[35]上获得更高的质量。他们的网络使用了一种称为focal
loss的方法来预测体素占用情况,类似于加权二元交叉熵。在
迄今为止最完整和性能最好的工作中,Wang等人[64]也使用
了基于块的编码和预测的体素占用情况,使用了加权二元交
叉熵。他们报告相对于MPEG
G-PCC在高分辨率8iVFB数据集[18]上的比特率降低了60%,
尽管他们只报告了与最先进的MPEG
V-PCC的近似等价性。相比之下,我们在更高分辨率的数据
集上使用基于块的编码,并且通过直接压缩TSDF而不是占用
情况,得到了至少三倍于MPEGV-PCC的比特率。
0
3.背景
0
我们的目标是压缩一个由TSDF体积V={Vt}T
1和对应的纹理图集T={Tt}T
1组成的输入序列,这些数据都是从多视角RGBD序列[26,
59]中提取出来的。由于几何和纹理是非常不同的,我们将它
们分别进行压缩。接收端在渲染之前将这两个数据流进行融
合。为了压缩几何数据V,受到最近学习压缩方法的进展的启
发,我们提出了一个端到端训练的压缩流水线,以体积块作
为输入;详见第4节。因此,我们还设计了一种基于块的UV
参数化算法来处理纹理T;详见第5节。对于那些对这个主题
和符号不熟悉的人,我们在补充材料中概述了压缩的基本原
理。
0
4.几何压缩
0
端到端学习压缩面临两个主要挑战,这两个挑战都源于中间
步骤的不可微性:1压缩由于压缩需要量化而不可微;2从
TSDF值进行表面重建通常是不可微的,例如Marching
Cubes等流行方法。为了解决1
,我们借鉴了最近在学习图像压缩方面的进展。为了解决2
,我们观察到MarchingCubes
算法在已知拓扑的情况下是可微的。训练的计算可行性。整
个序列的密集TSDF体积数据V={Vt}Tt=1
的维度非常高。例如,Tang
等人在其数据集中使用的序列有500帧,每帧包含240240
400
个体素。数据的高维度使得无法计算地联合压缩整个序列。
因此,我们按块状方式独立处理每个帧,这与Tang
等人的方法相似。从TSDF体积V
中,我们提取所有不重叠的大小为kkk的块{xm}M
1,这些块包含零交叉。我们将这些块称为占用块,并独立进
行压缩。
0
4.1.推断
0
压缩流程如图2所示。给定要传输的块
x,发送方首先使用学习编码器E和参数θe
计算有损量化的潜在表示ˆz=bE(x;θe)
e。接下来,发送方使用ˆz计算TSDF标志的条件概率分布
ps|ˆz(s|ˆz;θs),其中s是块的真实标志配置,θs
是分布的可学习参数。然后,发送方使用熵编码器通过无损
编码潜在编码ˆz和标志s来计算比特流ˆz位和s位。
剩余10页未读,继续阅读
相关推荐





cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 小学水墨风学校网站模板设计
- 深入理解线程池的实现原理与应用
- MSP430编程代码集锦:实用例程源码分享
- 绿色大图幻灯商务响应式企业网站开发源码包
- 深入理解CSS与Web标准的专业解决方案
- Qt/C++集成Google拼音输入法演示Demo
- Apache Hive 0.13.1 版本安装包详解
- 百度地图范围标注技术及应用
- 打造个性化的Windows 8锁屏体验
- Atlantis移动应用开发深度解析
- ASP.NET实验教程:源代码详细解析与实践
- 2012年工业观察杂志完整版
- 全国综合缴费营业厅系统11.5:一站式缴费与运营管理解决方案
- JAVA原生实现HTTP请求的简易指南
- 便携PDF浏览器:随时随地快速查看文档
- VTF格式图片编辑工具:深入起源引擎贴图修改
