深度学习驱动的RGB相机转RGB-D:连续深度估计与不确定性处理
PDF格式 | 4.28MB |
更新于2025-01-16
| 122 浏览量 | 举报
RGB→D传感:单目深度不确定性的深度学习估计方法
深度学习在计算机视觉领域的应用日益广泛,尤其是在三维重建和场景理解方面,传统的有源深度传感器如飞行时间相机和LiDAR虽然能提供密集的深度信息,但它们存在诸多局限性,如有限的操作范围、低空间分辨率、高能耗和传感器干扰。为克服这些问题,本文提出了一种创新的深度学习技术,旨在从单目视频流中实时估计每个像素的深度及其不确定性。
不同于传统的深度学习方法,该研究不再仅关注单一深度值的估计,而是采用深度概率分布的方式,这样可以为每个输入帧提供三维深度的概率分布量。这种方法运用了贝叶斯滤波框架,通过连续处理多个输入帧,逐步降低深度不确定性,提高精度、鲁棒性和时间稳定性。这种处理方式使得RGB相机能够模拟RGB-D相机的功能,实现更加准确、稳定和可扩展的深度感知。
与其他现有工作相比,该方法在深度估计的准确性和泛化能力上有所突破,能够在保持高效的同时解决单目方法的尺度模糊和漂移问题,以及立体和多视图方法的对应难题和高计算成本。实验结果证明,该方法的输出可以直接用于经典的RGB-D三维扫描方法,用于构建三维场景模型,显著提升了三维重建的质量和效率。
总结来说,本文的工作主要贡献在于提出了一种深度学习驱动的单目深度估计框架,它不仅能提供精确的深度估计,还提供了深度的不确定性信息,这对于增强现实、自动驾驶等对实时三维感知要求高的应用场景具有重要意义。通过结合深度学习的模型能力和单目视觉的优势,该方法有望推动RGB-D传感技术的发展,进一步拓展计算机视觉在更多领域的应用。
10988
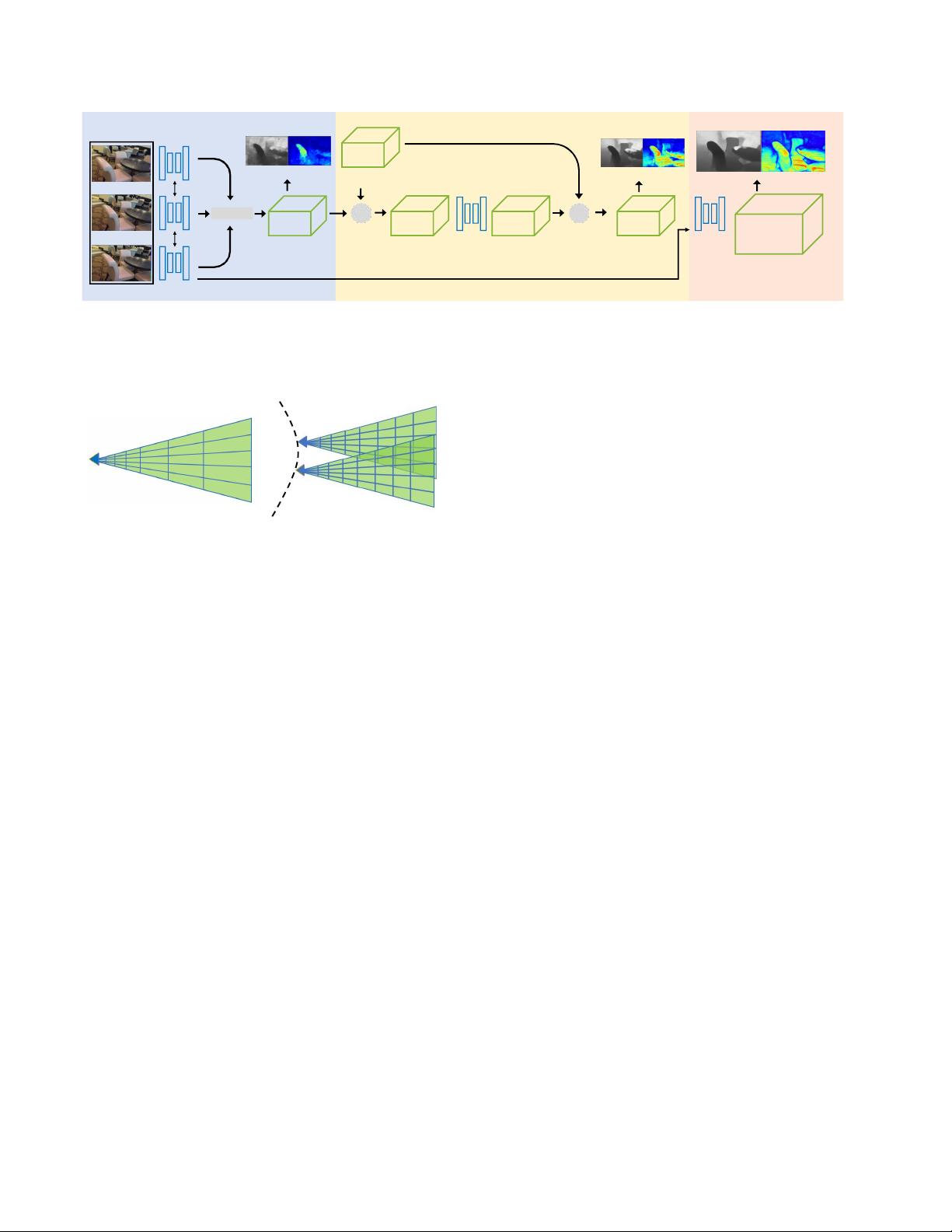
图2.概述了所提出的用于视频中不确定性深度估计的网络。我们的方法将视频中的本地时间窗口中的帧作为输入,并输出随时
间更新的深度概率体积(DPV)。更新过程采用贝叶斯过滤器方式:我们首先取使用D-Net估计的局部DPV之间的差(第二
节)。3.1)和来自先前帧的预测DPV以得到残差;然后残差由K-Net(第3.1节)修改3.2)并加回预测的DPV;最后DPV被R-Net
细化和上采样(第3.2节)。3.3),其可用于计算深度图及其置信度。
当前帧
I
t
并计算它们的差。因此,对于所有深度候选
者,我们可以计算成本体积,它在
softmax
层之后产
生
DPV
Σ
(a)
深度概率体积(DPV)
L
(d
t
|I
t
)
=
k
∈N
t
,
k
||
、
||
,
不
图3. DPV的表示和更新。(a)DPV被定义在由针孔相机模型定
义的3D平截头体上。
(b)
DPV随着相机移动而随时间更新
深度的似然估计(MLE)及其置信度:
d
=
最
大
值
x
深度:d(u
,
v)= p(d;(u
,
v))
·
d
,
(1)
d
=
d
min
置信度
:
C
(
u
,
v
)
=
p
(
d
,
(
u
,
v
))
。
(
二)
为了使符号更简洁,我们将省略(u
,
v),并在本文
的其余部分使用p(d)表示DPV。
当处理视频流时,DPV可以被视为系统的隐藏状
态。 当摄像机移动时, 如图3(b),DPV p(d)
随着新观测的到来而更新,特别是对于重叠卷。同
时,如果相机运动是已知的,则我们可以容易地从当
前状态
预测
下一个状态p(d)。这种预测更新迭代自
然意味着贝叶斯过滤方案随着时间的推移更新DPV以
获得更好的准确性。
3.1.
D Net:估计DPV
对于每个帧
I
t
,我们使用名为
D-Net
的
CNN
来估计
条件
DPV
,
p
(
d
t
|
I
t
),使用
I
t
及其节奏相邻帧。在
本文中,我们考虑
五帧的
局部
t
,
t
+ 2
(25fps/30fps)。对于给定的深度候选d,我们可以通
过将所有相邻帧扭曲成
估计深度概率(第第
3.1
节)
随时间积分深度概率(秒)
3.2
)
细化深度概率(第
3.3
)
N
t
D-net
深度 信心
预测
DPV
#
(
%
t
|
I
)
:
t
+
)
)
深度置信度
深度
信心
共享
K-Net
R-net
Softmax
-
+
实测
DPV
#
(
%
t
| I
t
)
残余
剩余增益
更新DPV
#
(
%
t
|
I
)
:
t
)
经纱
精制DPV
跳过从图像功能到
R-Net
的连接
相机轨迹
不
t+1
(b)更新DPV
…
…
剩余10页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
