高分辨率视频预测:STRPM模型与时空残差分析
12 浏览量
更新于2025-01-16
收藏 1.94MB PDF 举报
"STRPM是一种针对高分辨率视频预测的时空残差预测模型,旨在处理512x4K等高分辨率视频,通过时空编解码方案和残差预测记忆(RPM)来优化预测效果。该模型利用生成对抗网络(GAN)与学习感知损失(LP损失)提升预测的感知质量,表现出优于现有方法如CrevNet的预测性能。该研究受到多项国家自然科学基金和国家重点研发项目的资助。"
高分辨率视频预测是当前视频处理领域的一个重要挑战,因为高分辨率视频包含了丰富的空间和时间信息,对模型的预测精度要求更高。STRPM模型通过深入分析现有视频预测方法的局限,提出了一个创新的解决方案。
首先,STRPM采用时空编解码结构,目的是为了保留高分辨率视频中的时空信息。这种结构允许模型在保持视频细节的同时,有效地处理大量的像素数据,这对于处理高分辨率视频至关重要。
其次,残差预测记忆(RPM)是STRPM的核心组成部分,它关注于前一帧与未来帧之间的时空残差特征(STRF)建模,而非直接预测整个帧。这种策略有助于捕捉复杂的运动信息,特别是对于高分辨率视频中可能出现的微小运动变化,RPM能够更准确地追踪。
此外,STRPM结合了生成对抗网络(GAN)和学习感知损失(LP损失)进行模型训练。GAN被用来生成更接近真实视频的预测结果,提高视觉质量。而LP损失则有助于提升预测帧的感知质量,确保预测的视频不仅在像素级相似,而且在视觉效果上也接近真实。
实验结果显示,STRPM相比于CrevNet等现有方法,能在高分辨率视频预测上获得更优的预测结果,尤其是在视觉细节的保留和复杂运动的捕捉方面表现出色。这些进步对于视频压缩、视频编辑、自动驾驶等应用具有重要意义,因为它们都依赖于准确的视频预测技术。
STRPM模型通过独特的时空残差预测和高效的特征提取策略,为高分辨率视频预测提供了新的思路,有望推动相关领域的技术发展。同时,这种方法也展示了在处理高信息密度视频数据时,如何通过精细的建模和训练策略提升预测性能。
13948
∼
··
·
监督
时空编码
器
v
O
E
O
P
时空解码
器
O
D
不
v
t+1
时间编码
器
T
E
剩 余
预 测
记忆
T
P
时间解码
器
T
D
空间编
码器
S
E
S
P
空间解
码器
S
D
v
t
+
1
火车
MSE
损失
鉴别器
L
鉴别器
层
k
1
习得性知觉丧失
层
k
2
火车
L
对抗性损失
火车
层
N
层
N
层
1
层
1
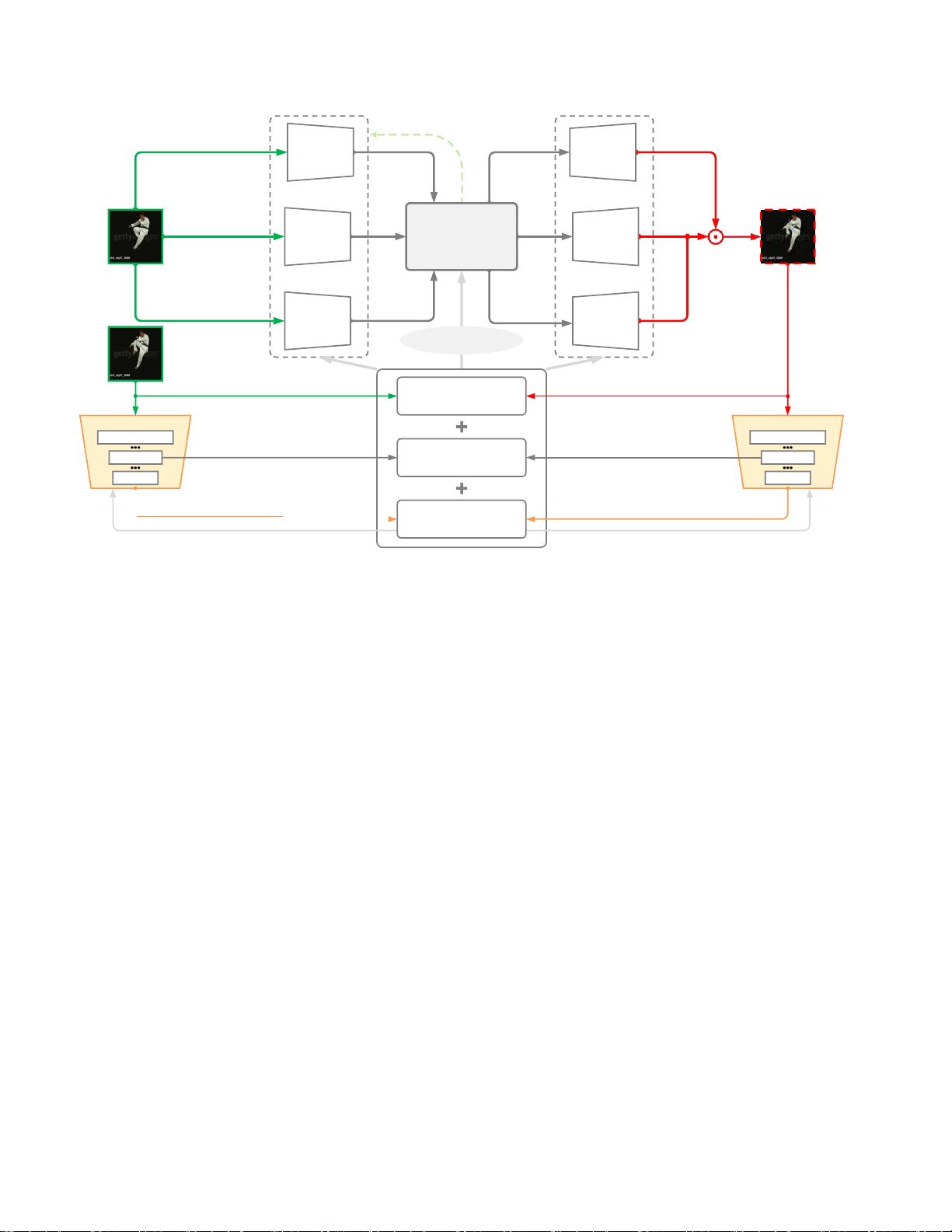
图2.提出的时空残差预测模型(STRPM)的结构绿色箭头表示输入信息流,红色箭头表示预测信息流。
更高分辨率的视频(512 4K)。为了解决上述问题,
我们提出了一个时空残差预测模型(STRPM)的高分
辨率视频预测与可接受的计算负载。此外,通过使用
所提出的学习感知损失,可以从所提出的方法生成更
自然的视频。
3.
时空残差预测模型
在本节中,我们详细介绍了提出的时空残差预测模
型( STRPM )。 所提 出的 模型 的整 体结 构如 图2 所
示。与低分辨率视频不同,高分辨率视频包含了更复
杂的纹理细节和更多多变的运动信息,因此,高分辨
率视频预测迫切需要解决两个问题:
•
如何为每一帧保留更多的视觉细节?
•
如何更准确地预测帧间的运动信息?
本文提出了时空残差预测模型(STRPM)来解决上述
问题。
3.1.
时空编解码方案
为了减少计算资源,在视频预测中通常使用单个编
码器将视频帧编码为低维特征。然而,时间信息和空
间信息会相互影响,预测记忆必须进一步提取时间和
空间信息来预测未来的帧,在此过程中,可能会丢失
大量的时空信息,使得很难为每一帧重建满意的视觉
为了解决这个问题(第一个问题),我们新颖地利用
多个时空编码器来独立地提取时间域和空间域中的深
度特征这样,空间信息和时间信息将不再相互影响,
使得预测存储器更容易利用空间时间信息进行视频预
测。编码过程可以表示如下,
(
T
E
,
S
E
,
O
E
)
=
(
Enc
T
(
v
t
)
,
Enc
S
(
v
t
)
,
Enc
O
(
v
t
))
,
(
1
)
其中
v
t
表示源视频
V
中的
第
t
帧。
Enc
T
()
、
Enc
S
()
、
Enc
O
()分别表示时间、空间和时空编码器
TE
、
SE
、
OE
分别表示时间步长
t
处的编码的低维时
间、空间和时空特征
特别地,上述编码特征
T
E
、
S
E
、
O
E
剩余10页未读,继续阅读
201 浏览量
2021-09-19 上传
2025-03-04 上传
123 浏览量
206 浏览量
点击了解资源详情
点击了解资源详情
2023-05-24 上传

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 支付宝订单监控免签工具:实时监控与信息通知
- 一键永久删除QQ空间说说的绿色软件
- Appleseeds训练营第4周JavaScript练习
- 免费HTML转CHM工具:将网页文档化简成章
- 奇热剧集站SEO优化模板下载
- Python xlrd库:实用指南与Excel文件读取
- Genegraph:通过GraphQL API使用Apache Jena展示RDF基因数据
- CRRedist2008与CRRedist2005压缩包文件对比分析
- SDB交流伺服驱动系统选型指南与性能解析
- Android平台简易PDF阅读器的实现与应用
- Mybatis实现数据库物理分页的插件源码解析
- Docker Swarm实例解析与操作指南
- iOS平台GTMBase64文件的使用及解密
- 实现jQuery自定义右键菜单的代码示例
- PDF处理必备:掌握pdfbox与fontbox jar包
- Java推箱子游戏完整源代码分享
