知识蒸馏缩小大规模模型与实用性价比差距:ImageNet top-1精度达82.8%
126 浏览量
更新于2025-01-16
收藏 1.56MB PDF 举报
大规模模型的高准确率与低成本之间的差距在计算机视觉领域日益显著,尤其是在图像分类、对象检测和语义分割等任务中。最先进的大规模模型,如那些基于Transformer架构的,虽然能够在ImageNet数据集上取得高达82.8%的top-1精度,但它们的高昂计算成本限制了它们在实际场景中的应用。相比之下,小型模型如ResNet-50和MobileNet由于计算效率和经济性更受从业者青睐。
本文的焦点在于解决这种高精度与实际部署之间的鸿沟,作者并不追求发明全新的模型方法,而是寻求一种强大且有效的知识转移策略——知识蒸馏。知识蒸馏是一种机器学习技术,通过将大型模型(教师模型)的知识传授给小型模型(学生模型),从而帮助后者提高性能,同时保持较小的模型尺寸和较低的计算需求。
研究者强调了在训练过程中的一些关键设计选择对知识蒸馏效果的影响。例如,耐心的训练和提供一致的图像视图对于蒸馏过程至关重要,这与使用预计算的教师目标相比,能带来更好的性能提升。他们通过对大量视觉数据集,特别是ImageNet,进行深入的实证研究,展示了通过恰当的知识蒸馏方法,即便是相对较小的学生模型也能逼近甚至超越大型模型的性能。
值得注意的是,研究者的工作着重于将最新的技术进步转化为实际应用,关注的是模型的实用性而非纯粹的理论突破。他们通过TensorflowHub平台的数据下载量变化,揭示了这一转化的重要性。通过细致的实验和分析,论文为如何在保持高准确率的同时降低成本提供了实用的指导,这对于推动大规模模型在实际场景中的广泛应用具有深远影响。
10927
Σ
C
×
×
不
固定教师
独立噪声
一致性教学函数匹配
S
不
logit
匹配
logit
匹配
S
不
logit
匹配
S
不
logit
匹配
S
不
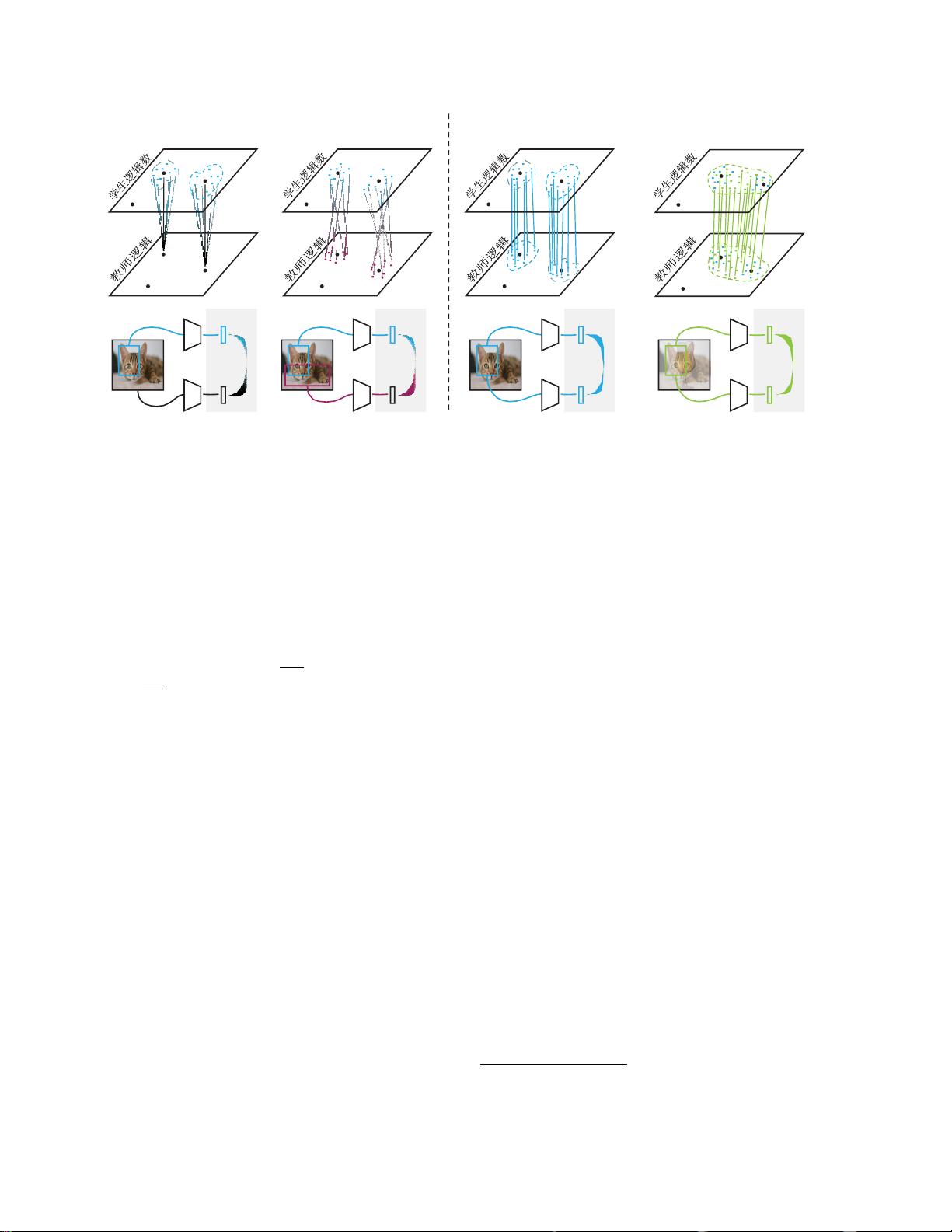
图2.进行知识提炼时各种设计选择的示意图。左:
教师
接收固定图像,而
学生
接收随机增强。中左:
教师
和
学生
接受独立的图
像增强。中右:
教师
和
学生
获得一致的图像增强。右:
教师
和
学生
接收一致的图像增强,加上输入图像流形通过包括图像对之
间的线性段来扩展(称为mixup[51]增强)。
到原始数据集
KL(p
t
||
p
s
)= [
−
p
t
,
i
log p
s
,
i
+ p
t
,
i
log p
t
,
i
]
,
(
1
)
i
∈C
其中是一组类。此外,如[12]中所述,我们引入温度参
数T,其用于在预测的软最大概率分布之前调整预测的
软最大概率分布的熵。
在损失计算中使用:
p
sexp(
log
p
s
)和
在计算可行的情况下(我们总共训练了成千上万个模
型),我们使用相对较低的输入分辨率,并将输入图
像大小 调整为128 128大小, 除了我们的 ImageNet 实
验,使用标准输入
224 224分辨率。
对于我们所有的实验,我们使用Google Cloud TPU加速器-
[19].我们还报告了我们的批量大小,epoch或更新步骤
的总数,这允许估计资源重新分配。
p
texp
(
log
p
t
)。
任何感兴趣的特定实验的
测试
要求模型代码和重量是公开的
2
。
培训设置。 为了优化,我们训练模型
使用Adam优化器[21]和默认参数,除了初始学习率,
这是我们超参数探索的一部分我们使用余弦学习率时
间表[27],无需热重启。我们还扫描了所有实验的重量
为了稳定训练,我们在梯度的全局L2范数上启用阈值
为1.0的梯度裁剪。最后,我们在所有实验中使用批量
大小512,除了在ImageNet上训练的模型,我们使用批
量大小4096进行训练。对于其余的超参数,我们将在
下一节中讨论它们的扫描范围以及相应的实验我们的
配方的另一个重要组成部分是
混合
数据增强策略[51]。
特别是,我们在“函数匹配”策略中引入了一个混合变
量
β分布。
除非另有明确说明,否则为了吸引人,我们使用此
外,为了使我们的前-
3.
模型压缩
3.1.
调查“一贯和耐心的教师”假设
在这一节中,我们对我们在引言中提出的假设进行
了实验验证,并在图2中可视化,即蒸馏在被视为函数
匹配时效果最好,即当学生和教师看到输入图像的一
致视图时,通过mixup合成地
为了确保我们的研究结果是稳健的,我们对四个中
小型数据集进行了非常彻底的分析,即Flowers102[30]
(1020张训练图像),Pets[32](3312张训练图像),
Food101[20](约68k张训练图像)和SUN397[47](76k
张训练图像)。
为了消除任何混淆因素,对于每个单独的蒸馏设
置,我们扫描学习率的所有组合{0
。
0003
,
0
。
001
,
0
。
003
,
0
。
01},重量
衰变
{
1
·
10
−
5
,
3
·
10
−
5
,
1
·
10
−
4
,
3
·
10
−
4
,
1
·
10
−
3
}
,
和
2
https://github.com/google-research/big_transfer
随机
作物
插值
mixup
相同
的
输入
随机
作
物
固定教师预
测
学生
噪
声
教师
噪
声
随机
作
物
相同
的
输入
剩余13页未读,继续阅读
基于知识蒸馏的Resnet改进轻量化模型实现高光谱图像分类(附数据集及高准确率),基于知识蒸馏学习的轻量化高光谱图像分类模型代码 Pytorch制作 教师模型采用Resnet18,学生模型是对教师模型
2025-02-02 上传
2025-03-01 上传
169 浏览量
116 浏览量
131 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- ITween插件实用教程:路径运动与应用案例
- React三纤维动态渐变背景应用程序开发指南
- 使用Office组件实现WinForm下Word文档合并功能
- RS232串口驱动:Z-TEK转接头兼容性验证
- 昆仑通态MCGS西门子CP443-1以太网驱动详解
- 同步流密码实验研究报告与实现分析
- Android高级应用开发教程与实践案例解析
- 深入解读ISO-26262汽车电子功能安全国标版
- Udemy Rails课程实践:开发财务跟踪器应用
- BIG-IP LTM配置详解及虚拟服务器管理手册
- BB FlashBack Pro 2.7.6软件深度体验分享
- Java版Google Map Api调用样例程序演示
- 探索设计工具与材料弹性特性:模量与泊松比
- JAGS-PHP:一款PHP实现的Gemini协议服务器
- 自定义线性布局WidgetDemo简易教程
- 奥迪A5双门轿跑SolidWorks模型下载
