PointAugment:点云分类的自动增强框架
139 浏览量
更新于2025-01-16
收藏 1.3MB PDF 举报
"PointAugment是一种自动增强框架,专门针对点云分类任务,旨在通过自动优化和增强训练数据,提升深度神经网络的泛化能力。该框架采用了对抗学习策略,能够根据分类网络的需求动态生成增强样本。同时,PointAugment包含了一个可学习的点增强函数,实现了形状变换和逐点位移,以增加数据多样性。通过精细设计的损失函数,PointAugment能够适应分类器的学习进度。研究表明,PointAugment在多个代表性网络上提高了点云分类的准确性,尤其是在ModelNet40等数据集上表现显著。与传统仅在预定义范围内随机扰动输入点云的增强策略相比,PointAugment能够更有效地避免过拟合,提升网络性能。"
点云分类中的自动增强方法是解决3D数据集有限数量和多样性问题的关键技术。由于3D点云数据集(如ModelNet40)相对于2D图像数据集(如ImageNet和MSCOCO)来说,样本量较小且多样性有限,这可能导致深度学习模型过拟合,降低其泛化能力。传统的数据增强方法,如随机旋转、缩放和抖动,虽然有效,但可能无法充分利用整个增强空间,并且没有考虑网络训练的反馈。
PointAugment通过引入对抗学习策略,将数据增强与网络训练过程结合起来,使得增强器能够根据分类网络的需求自适应地生成增强样本。这种方法的优势在于,它可以动态调整增强策略,以优化网络性能,避免因固定增强导致的训练不足问题。
此外,PointAugment引入了一个可学习的点增强函数,这个函数能够执行形状变换和逐点位移,从而更加灵活地改变点云结构,增加数据的多样性和复杂性。配合精心设计的损失函数,PointAugment能够更好地利用分类器的学习进度,逐步优化增强策略,进一步提升模型的泛化性能。
实验结果显示,PointAugment在多个点云分类网络上表现出色,显著提高了分类准确率,证明了该方法的有效性。通过自动增强和联合优化,PointAugment为点云分类任务提供了更强大、更适应性强的数据增强工具,有助于推动3D深度学习领域的进步。
6380
i
=1
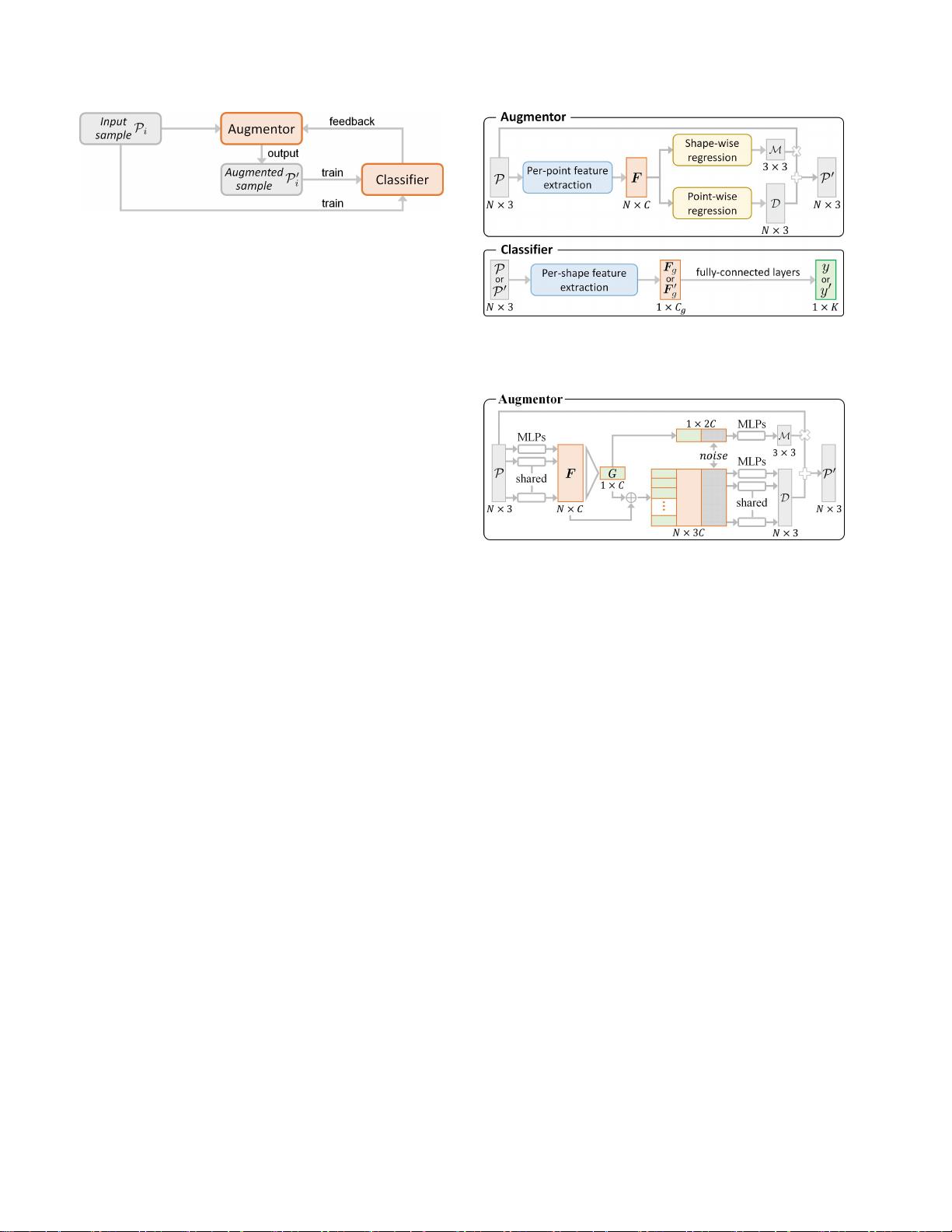
图2:PointAugment框架的概述。我们以端到端的方式
使用对抗学习策略联合优化增强器和分类器
输入训练数据集
{P
i
}
M
M
个样本,其中每个样本
样本有N
个
点,在我们用sam训练分类器C
我们首先将P
i
馈送到我们的增强器A以生成
增广样本
P
′
。然后
,我们分别供给
Pi
和
P
′
图3:增强器和分类器的图示。的
增广器从P生成增广样本
P
′
,
我我
对分类器C进行训练,并进一步将C
在详细说明PointAugment框架之前,我们
首先讨论我们框架背后的主要思想。这些是新的想法
(在以前的作品中不存在[3,14,8]),使我们能够
有效地增强训练样本,现在是3D点云而不是2D图像。
•
样本感知
。而不是找到一个通用的一套增强政策
或程序处理每一个输入数据样本,我们的目标是
回归一个特定的aug-
通过考虑样本的潜在几何结构,为每个输入样本
创建分段函数。我们称之为样本感知自动增强。
•
2D vs. 3D
增强
。与图像的2D增强不同,3D增强涉
及更大且不同的空间域。会计性质
对于3D点云,我们考虑点云样本上的两种变换:
形状变换(包括旋转、缩放及其组合)和点位移
(点位置的抖动),其中我们的增强器应该学习
产生它们以增强网络训练。
•
联合优化
。在网络训练过程中,分类器会逐渐学
习,变得更强大,因此我们需要更具挑战性的增
强样本
以更好地训练分类器,因为分类器变得更强。因
此,我们以端到端 的方式设计和训练 PointAug-
ment框架,这样我们就可以联合优化增强器和分
类器。为此,我们必须仔细设计损失函数,并动
态调整增强样本的难度,同时考虑输入样本和分
类器的容量。
4.
方法
在本节中,我们首先介绍增强器和分类器的网络架
构细节(第4.1节)。然后,我们给出了我们为增强子
(4.2节)和分类器(4.3节)制定的损失函数,并介绍
了
分类器预测给定
P
′
或P作为输入的类标签。
图4:我们的增强器实现。
我们的端到端培训策略(第4.4节)。最后,我们介绍
实现细节(第4.5节)。
4.1.
网络架构
增强剂与现有的工作[3,14,8]不同,我们的增强器
是样本感知的,它学习生成一个特定的函数来增强每
个输入样本。从现在开始,为了便于阅读,我们去掉
下标
i
,
并表示
P
作为增强器A的训练样本输入,
A .对应的增广样本输出
我们的增强器的整体架构如
图
3
(顶部)所示。首
先,我们使用逐点特征提取单元来嵌入所有
N
个
点
的点特征
F
∈
R
N
×
C
在P中,其中C是特征通道的数量。 从F,
然后,我们使用架构中的两个单独的组件来回归特定
于 输 入 样 本 P 的 增 强 函 数 : ( i ) 形 回 归 产 生 变 换
M
∈R
3
×
3
,(ii)点回归产生位移D ∈R
N
×
3
。 注意,学
习的
M
是线性的
矩阵在
3D
空间中,主要结合旋转和缩放,而学习的
D给出逐点平移和抖动。使用
M
和D,我们可以生成
增广样本
P
′
为
P
·
M
+
D。
我们提出的增强器框架的设计是通用的,这意味着
我们可以使用不同的模型来构建其组件。图4显示了我
们当前的IM-
剩余10页未读,继续阅读
2133 浏览量
113 浏览量
176 浏览量
2022-11-30 上传
307 浏览量
482 浏览量
379 浏览量
125 浏览量
113 浏览量

cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机组成原理期末试题及答案(2011参考)
- 均值漂移算法深入解析及实践应用
- 掌握npm与yarn在React和pg库中的使用
- C++开发学生信息管理系统实现多功能查询
- 深入解析SIMATIC NET OPC服务器与PLC的S7连接技术
- 离心式水泵原理与Matlab仿真教程
- 实现JS星级评论打分与滑动提示效果
- VB.NET图书馆管理系统源码及程序发布
- C#实现程序A监控与自动启动机制
- 构建简易Android拨号功能的应用开发教程
- HTML技术在在线杂志中的应用
- 网页开发中的实用树形菜单插件应用
- 高压水清洗技术在储罐维修中的关键应用
- 流量计校正方法及操作指南
- WinCE系统下SD卡磁盘性能测试工具及代码解析
- ASP.NET学生管理系统的源码与数据库教程
