动态优化池化: DynOPool提升深度网络性能
PDF格式 | 789KB |
更新于2025-01-16
| 28 浏览量 | 举报
DynOPool是一种创新的动态优化池化模块,它旨在解决传统神经网络中池化操作固定接受域所带来的次优问题。池化在深度学习中扮演着关键角色,通过聚合局部特征来控制模型复杂性和提升性能。然而,当前的池化操作通常依赖于预设的超参数,如感受野大小和形状,这些往往不能适应所有场景,可能导致对不同尺度物体的识别效果不佳。
DynOPool的核心贡献在于它引入了一个端到端学习的过程,允许网络自适应地调整池化操作的比例因子,从而动态地优化接收域的大小和形状。这不仅提高了特征映射的效率,还使得深层网络能够以最合适的尺度观察输入图像,增强其表达能力和泛化能力。此外,该模块可以无缝融入深度神经网络中的任意嵌入式层,只需极低的额外成本即可实现。
为控制模型的复杂性,DynOPool引入了额外的计算成本限制损失项,这样可以在保持性能的同时,避免过度拟合或不必要的计算开销。这种设计既考虑了模型的精度,也兼顾了效率,使得模型能够在资源有限的情况下仍能展现出优秀的表现。
实验证明,通过整合DynOPool的学习模块,模型在图像分类和语义分割等多个任务上显著优于现有的基线算法,特别是在处理不同尺度物体和场景时,展现出了更好的适应性和泛化能力。因此,DynOPool为深度学习模型提供了一种有效且灵活的池化优化策略,有助于推动深度学习在更多领域的广泛应用。
551
×
×
×
×
×
- −
[·|
在
H
完
毕
W
out
0.30G / 71.18%(0.31G /69.49%)
(a) CIFAR-拉伸
1.24G/60.06%(1.26G/56.70%)
(b) CIFAR瓷砖
1.18G / 67.82%(1.26G /65.49%)
(c) CIFAR-大型
图
1.
我们进行玩具实验
CIFAR-100
与三个不同的合成数据集
;
(
a
)随机作物的垂直拉伸图像(
b
)平铺一个减半的图像在一个
4 - 4
网格(
c
)四倍减半的图像。虽然内容几乎相同,但每个特征图的最佳大小和形状取决于输入图像的特征而有很大不同
与具有固定特征图大小的人类设计模型不同,我们的模型调整特征图大小以保持每个特征图中的最佳信息量,从而提高性
能。粗体字中的数字是
GMAC
和
DynOPool
给出的精度,而括号中的数字来自人类设计的模型。
并专注于全球信息。另一方面,如果图像包含大量类别
特定信息,
例如
纹理、局部模式将更重要。
为了验证这一假设,我们构建了CIFAR-100数据集的
两个变体,CIFAR-tile和CIFAR-large,如图1所示。为
此,我们首先将CIFAR中的原始图像降采样为一半,构
建16 16图 像 。 然后 ,我 们 将 下 采 样 的 图 像平 铺为
CIFAR-平铺的4 4,并将下采样的图像上采样为CIFAR-
大的大小64 64。
正如预期的那样,我们的模型如图1(b)和
(c)以较大幅度优于人类设计的模型。尽管两个数据
集都是用大小为16的同一组基础图像构建的, 16、学
习 网 络 DynOPool 的 模 型 具 有 不 同 的 形 状 ;我 们 在
CIFAR-tile上训练的模型比在早期层中在CIFAR-large上
训练的模型具有更大的特征图。请注意,CIFAR-tile的
DynOPool更喜欢在网络的开始处使用小的接收场,因
为tiled对象非常小。另一方面,我们的CIFAR- large模
型被鼓励在低层有大的接收场,因为输入图像是从一个
小的图像放大的,在早期的层中观察大的区域是有意义
的。
4.
该方法
输入要
素格网
输出要
素格网
双线性
插
值
聚合
函数
H
输入
= 8,H
输出
= 3, R
h
= H
输出
/
H
输入
W
in
= 11, W
out
= 3, r
w
= W
输出
/
W
输入
图
2.
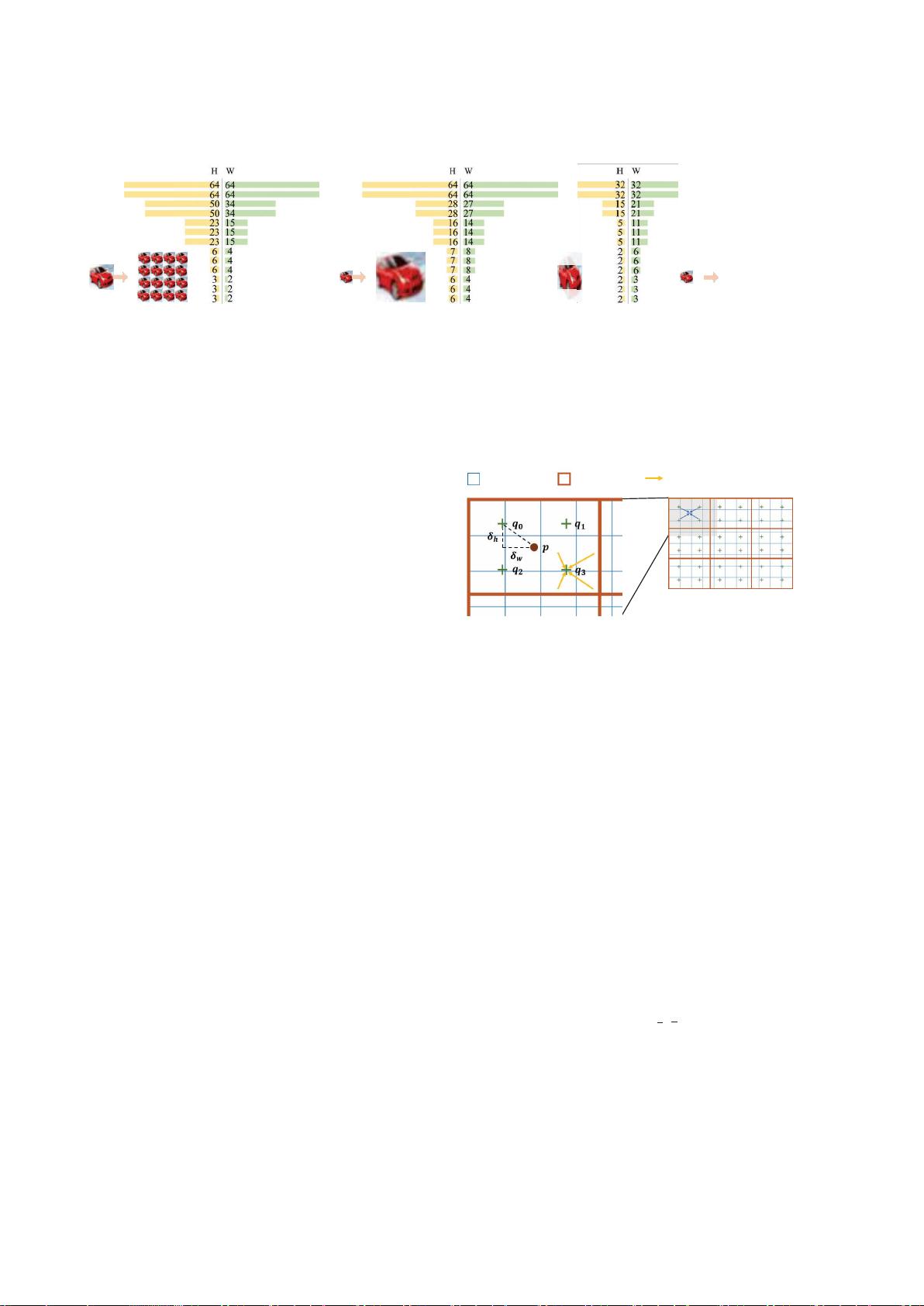
建议的集成模块
DynOPool
的概述(最佳彩色视图)。
我们优化了一对输入和输出特征图之间的比例因子
r
=(
rh
,
rw
)
,分别用
x
in
和
x
out
表示
。棕色点
p
表示
xout
中的网格单元
的
中 心
,而绿色十字表示同一单元中的四个查询点
q
。通过对
应于
x
中的四个最近像素的特征的双线性插值给出
q i
的表示
。
通过四个
查询点的特征聚合来导出网格单元
in x out
的输出
特征,其中通常采用诸如最大池化的简单聚合函数。
4.1.1 DynOPool的设计
图2说明了DynOPool的工作原理。DynOPool首先将特
征图
x
in
划分为
H
out
×
W
out
网格,
我们详细讨论了建议的可学习的学习模块,简称为
DynOPool,其中包括它的概念,
H
输出
=
[H
输入
·
r
h
|
W
输出
=
[
W
输入
·
r
w
|
、
(
一
)
优化和实际效益。
其中
r
=
(
r
h
,
r
w
)表示高度的比例因子,
4.1. 动态优化池(DynOPool)
DynOPool中的fixed模块,它接受一个输入的特征
图,
x
∈
R
H
in
×
W
in
,并返回一个大小调整后的输出-
特征图的宽度,并且是舍入操作。假设(1
,
1)和
(
1
,
1
)是
x
的左上
角
和右下角的归一化坐标,则输出
特征图中网格单元的大小变为
2
×
2
。
put,
x
out
∈
R
H
out
×
W
out
,定义和优化如下。
然后,给定以p
=
(
p
h
,
p
w
)为
中心的网格单元
,
剩余11页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 武汉大学数字图像处理课程课件精要
- 搭建个性化知识付费平台——Laravel开发MeEdu教程
- SSD7练习7完整解答指南
- Android中文API合集第三版:开发者必备指南
- Python测试自动化实践:深入理解更多测试案例
- 中国风室内装饰网站模板设计发布
- Android情景模式中音量定时控制与铃声设置技巧
- 温度城市的TypeScript实践应用
- 新版高通QPST刷机工具下载支持高通CPU
- C++实现24点问题求解的源代码
- 核电厂水处理系统的自动化控制解决方案
- 自定义进度条组件AMProgressView用于统计与下载进度展示
- 中国古典红木家具网页模板免费下载
- CSS定位技术之Position-master解析
- 复选框状态持久化及其日期同步技术
- Winform版HTML编辑器:强大功能与广泛适用性
