新闻图像字幕生成:多模态注意力与transformer模型的结合
PDF格式 | 1.16MB |
更新于2025-01-16
| 52 浏览量 | 举报
"该文提出了一种端到端的模型,用于生成新闻图像的字幕,结合了多模态注意力机制和Transformer语言模型。模型针对新闻图像的特点,即需要真实世界知识(特别是命名实体)和丰富的语言表达能力,通过图像中的面部和对象关联标题中的单词,利用多模态多头注意力机制解决知识问题。同时,借助最先进的Transformer语言模型和字节对编码,生成语言丰富的字幕。在GoodNews数据集上,模型在CIDEr得分上有显著提升,并引入了更大的NYTimes800k数据集,包含更多文章质量和图像位置信息。"
在当前的计算机视觉和自然语言处理领域,新闻图片字幕的生成是一个重要课题。传统的图像字幕系统虽然能够识别通用对象,但往往缺乏对具体命名实体和地点的了解,且生成的字幕语言多样性不足。新闻环境为解决这些问题提供了独特的场景,因为新闻文章提供了丰富的上下文信息,包括不断变化的词汇和风格。
文中提到的"TransformandTell"模型创新性地将新闻标题的生成与图像内容和文章文本相结合。通过多模态注意力机制,模型可以关注到图像中的关键区域(如人物或物体)以及文章中的相关文字,这有助于提取必要的世界知识。同时,Transformer语言模型的运用增强了模型的语言生成能力,尤其是对于新词和罕见词的处理,使生成的字幕更加准确和多样。
实验结果显示,该模型在GoodNews数据集上的CIDEr得分提高了近四倍,证明了模型的有效性。此外,提出的NYTimes800k数据集扩大了训练数据规模,包含的文章质量更高,图像位置信息的加入也为模型提供了额外的上下文线索,进一步推动了模型性能的提升。
这篇研究通过融合多模态信息和先进的语言模型,为新闻图片字幕生成提供了一个有力的解决方案,为未来的研究提供了新的方向,尤其是在处理多模态信息和提升生成内容的语义连贯性方面。
13037
我
输出标
题
字节对
令牌
文章
图像
Transformer解码器
以 前 的
字 节 对
令牌
对象
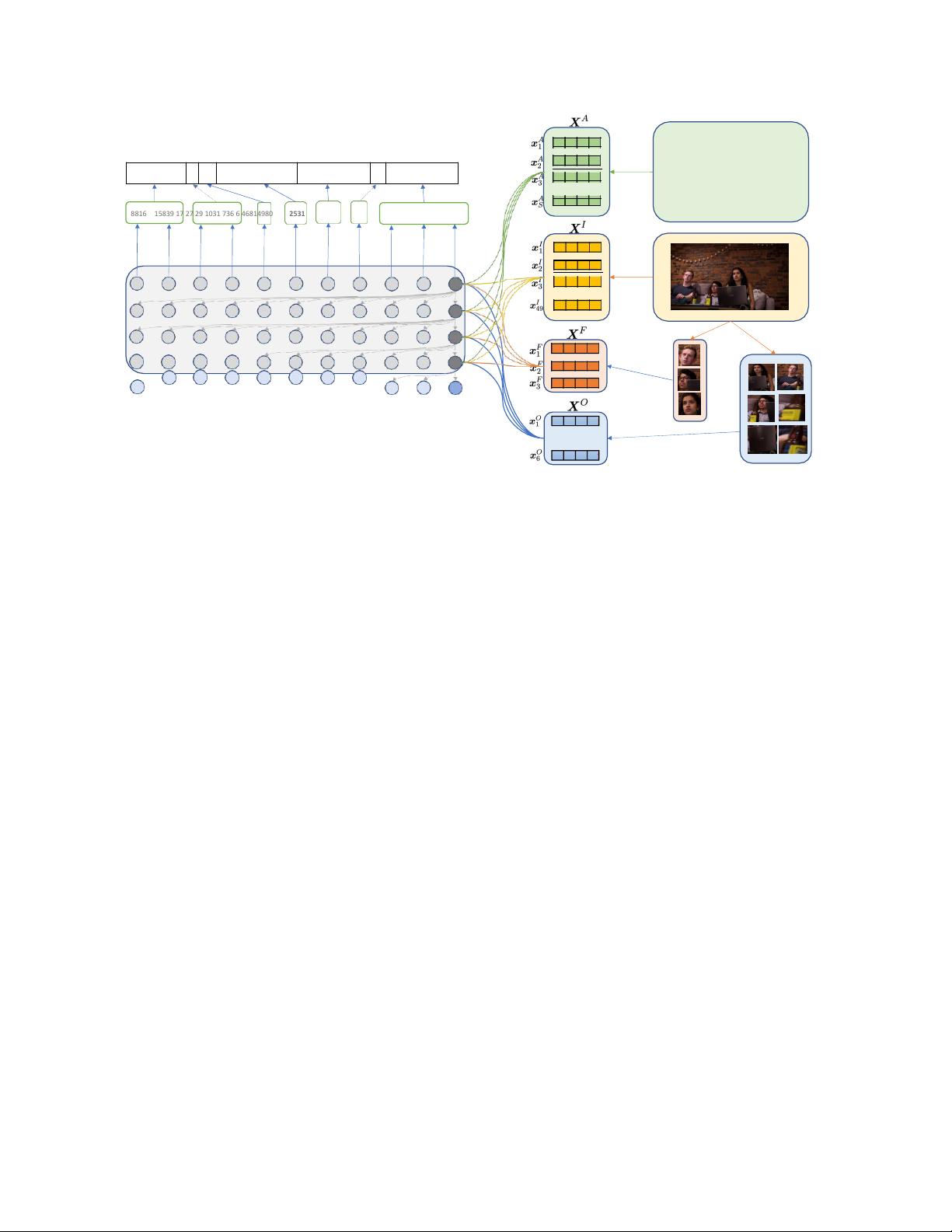
图2:转换和告知模型概述。左:具有四个Transformer块的解码器;右:编码器的文章,图像,面孔和对象。解码
器将字节对标记的嵌入作为输入(底部的蓝色圆圈)。例如,最后一个时间步中的输入14980表示来自前一个时间
步的“Varshini”中的“arsh”。灰色箭头显示每个块中最后一个时间步的卷积。彩色箭头表示对右侧四个域的关注:
文章文本(绿线)、图像补丁(黄线)、面部(橙线)和对象(蓝线)。最终的解码器输出是字节对标记,然后
将其组合成完整的单词和标点符号。
ageNet.我们使用池化层之前的最终块的输出作为图像
表示。这是一套
置信度小于0.3,并选择最多64个具有最高置信度分数
的对象通过ResNet-152
49
种不同的载体
x
I
∈R
2048
,其中每个向量对应-
在ImageNet上进行预训练。 与图像编码器相比,
在图像被分割
分成大小相等的7乘7块。 这就给了我们
X
I
=
{
x
I
∈
R
D
I
}
M
I
,其中
D
I
=
2048
且
M
I
=
49
我们把池化层之后的输出作为代表,
每个物体的位置。 这给了我们一组物体向量
X
O
=
{
x
O
∈R
D
O
}
M
O
,其中对于
ResNet
,
D
O
=
2048
i i
=1
i i
=1
ResNet-152。使用这种表示允许解码器关注图像的不
同区域,已知这可以提高其他图像字幕任务的性能[53]
并且已被广泛采用。
人脸编码器:我们使用MTCNN [56]来检测图像中的人
脸边界框。然后,我们最多选择四个面孔,因为大多
数字幕最多包含四个人通过将边界框传递给FaceNet
[ 40 ]来获得每 个人脸的矢量表示,FaceNet[40]是在
VGGFace2数据集[5]上预先训练的。每个图像
是
X
F
=
{
x
F
∈R
D
F
}
M
F
,其中对于
FaceNet
,
D
F
=
512
152
,
MO
是对象的数量
文章编码器:为了对文章文本进行编码,我们使用
RoBERTa [27],这是对流行的BERT [ 9 ]模型的最新改
进。RoBERTa是一个预先训练的语言表示模型,为文
本提 供上下 文嵌入。它 由24层双 向Transformer 块组
成。
与GloVe [35]和word2vec [31]嵌入不同,其中每个单
词只有一个表示,Transformer中的双向性和注意力机
制允许单词根据周围上下文具有不同的向量表示。
最大的GloVe模型的词汇量为1.2
i i
=1
M
F
是面的个数如果图像中没有面,则
X
F
是空集。
即使人脸是从图像中提取的,将它们视为单独的输
入域也是有用的。这是因为专门的人脸嵌入模型被调
整用于识别人,因此可以帮助解码器生成更准确的命
名实体。
对象编码器:我们使用YOLOv3 [38]来检测图像中的
对象边界框。我们用一个
万虽然这个值很大,但许多罕见的名称仍然会映射到
未 知 的 标 记 。 相 比 之 下 , RoBERTa 使 用 BPE [41 ,
36],它可以编码任何由Unicode字符组成的单词。在
BPE中,每个字首先被分解成一个字节序列。然后使
用贪婪算法合并公共字节序列。在[36]之后,我们的
vo- cabulary由50 K最常见的字节序列组成。
灵感来自Tenneyet al。[46]他表明BERT中的不同层
代表传统中的不同步骤
进步活动家在气候问题上将民主党推向左
翼。 现在怎么办?
罗伯塔
....
底特 律
--
今年
4
月, 自由环保组织
“
日出 运
动
”
(
SunriseMovement
)的 年轻活动人士
在韦 恩州立大学(
Wayne
StateUniversity
)举行了一场集会,支持采
取激进 措施遏制气候变化。他们的 目标
是: 让民主党总统候选人公开支持绿色
新政
ResNet-152
....
MTCNN
YOLOv3
FaceNet
面临
0 8816 15839 17 27 29 1031 736 6 46814980
....
ResNet-152
8816 15839 17 27 29 1031 736 6 46814980 2531
日出
‘
S
执行
主任
、
瓦尔希尼
剩余11页未读,继续阅读
相关推荐




cpongm
- 粉丝: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
